-
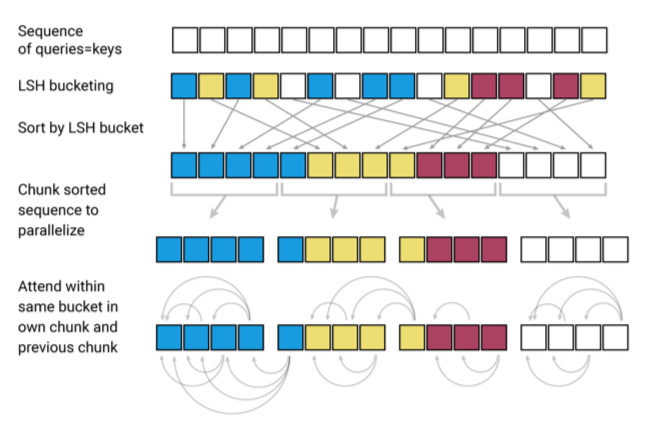
Attentionの計算量をO(NlogN)に
- 従来のTransformerだと内積計算がネック
- 類似度を計算しさえすれば良い
- ベクトルを回転させてバケツにブチこむ
- バケツごとに処理
- バケツ内は互いに近いベクトルのはず
-
-
Transformerを多層化するとそれだけの途中の状態を保存する必用がありますが、Reformerでしたら多層化してもそれぞれの層で状態を再計算できるため、メモリに保持する必用がなく、層の数だけメモリを削減できます。
- https://recruit.gmo.jp/engineer/jisedai/blog/reformer/
-
This page looks best with JavaScript enabled
Reformer
· ☕ 1 min read