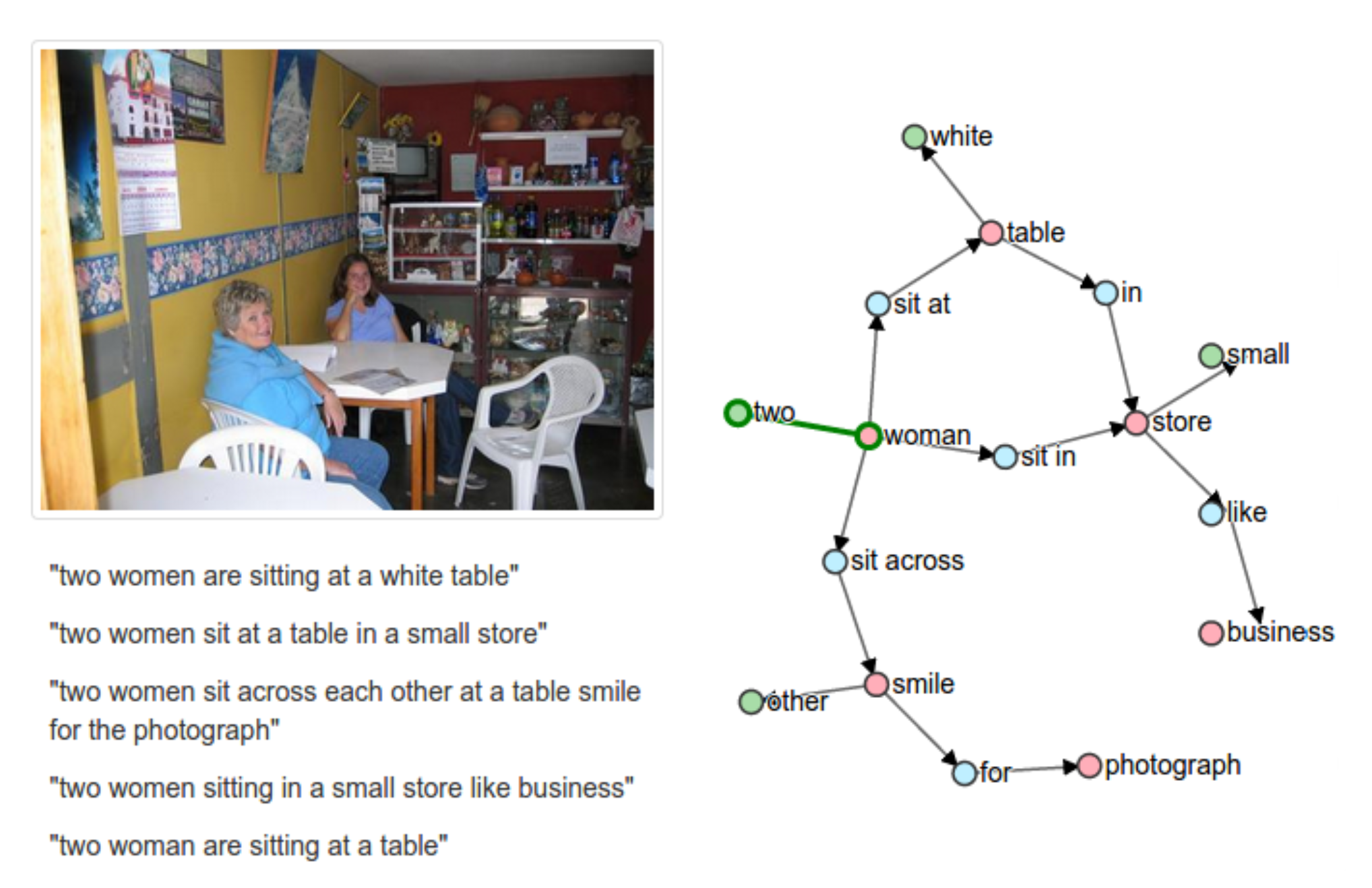
Stanford Scene Graph Parserの論文 (ACL 2015) 一応, scene graphを自動化してimage retrievalできるようにしようという趣旨 https://nlp.stanford.edu/software/scenegraph-parser.shtml 流れ ①Universal Dependenciesを一部修正したものをsemantic graphとして生成 a lot of 等のquantificational modifiersの修正 代名詞の解釈 複数名詞への対応 → ノー ...
STAIR MSCOCOにキャプションを付与 全部で820,310件のキャプション http://captions.stair.center/ Yuya Yoshikawa, Yutaro Shigeto, and Akikazu Takeuchi, “STAIR Captions: Constructing a Large-Scale Japanese Image Caption Dataset”, Annual Meeting of the Association for Computational Linguistics (ACL), Short Paper, 2017. YJ Captions 26k Dataset こちらもMSCOCOにキャプションを付与したもので, ACL2016 キャプション数がSTAIRの1/6程度 https://github.com/yahoojapan/YJCaptions Takashi Miyazaki and Nobuyuki Shimizu. 2016. Cross-Lingual Image Caption Generation. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1780 ...