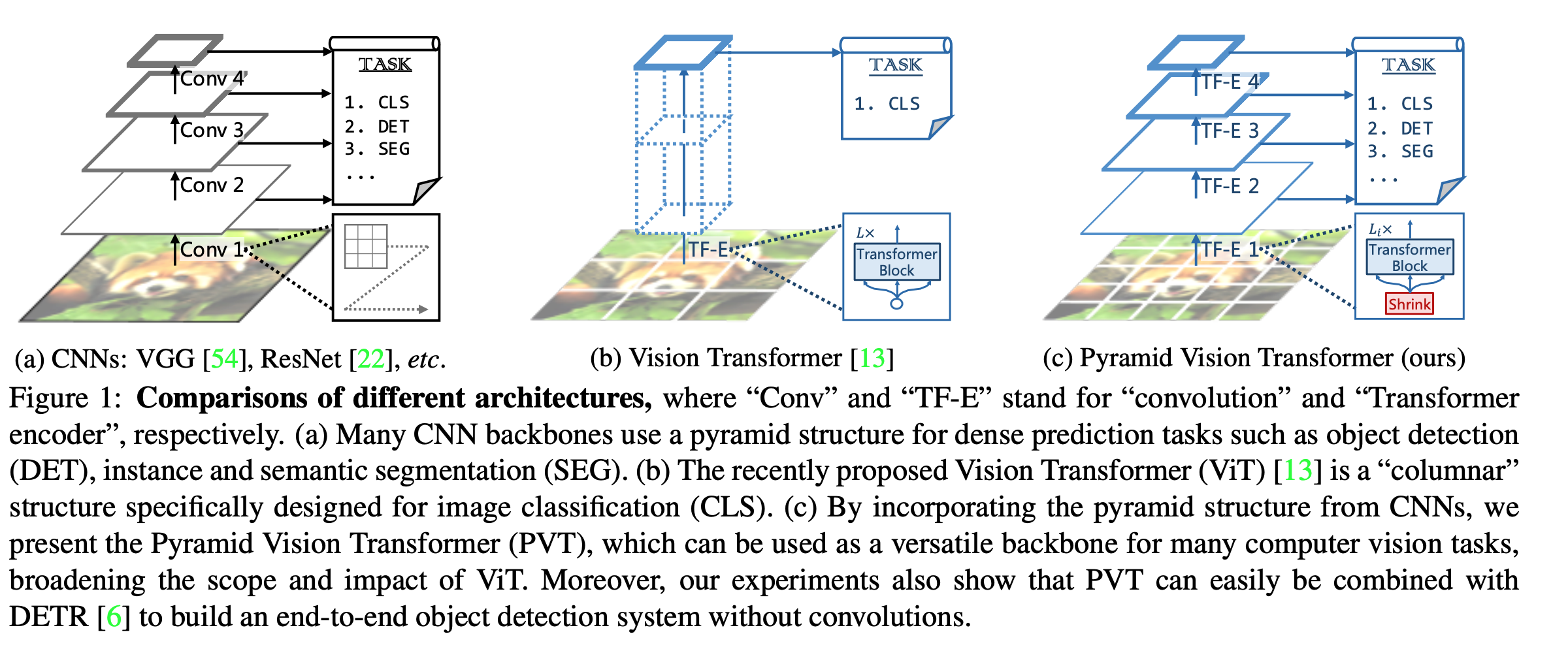
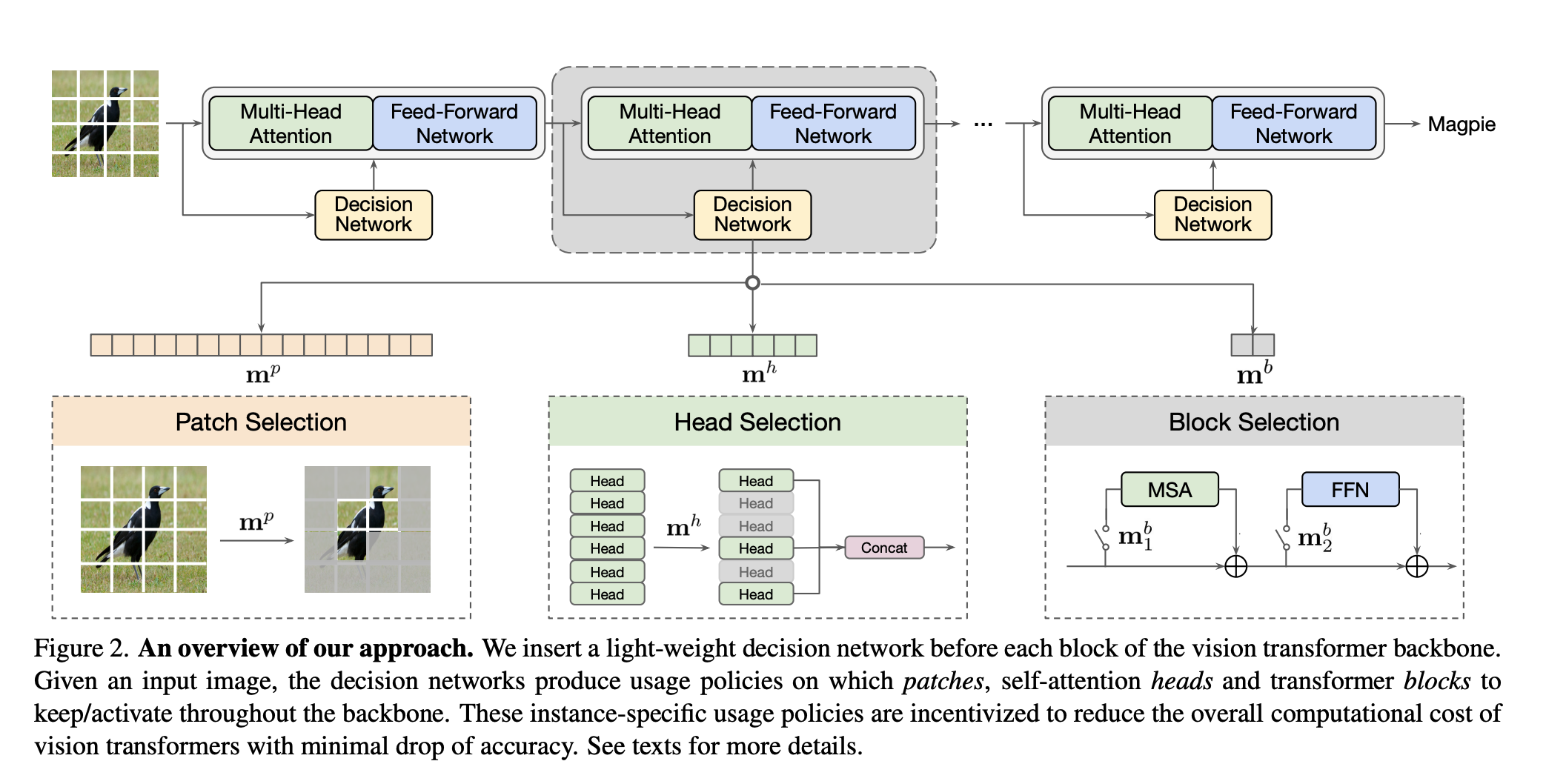
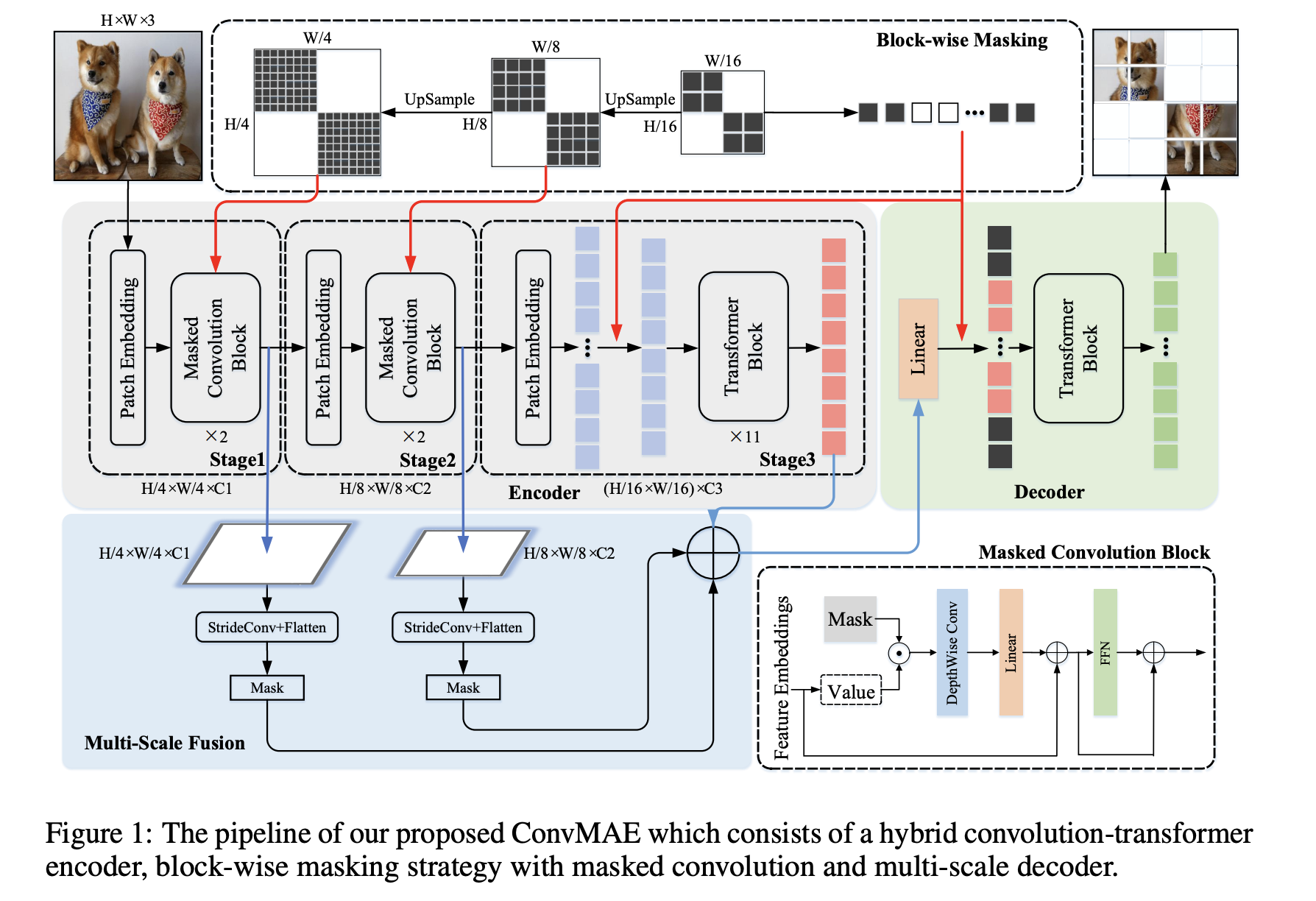
Pyramid Vision Transformer PVT v2では Positional Encodingが存在しない https://twitter.com/yu4u/status/1522360958228000769 FFNにzero padding付きのdepthwise convを入れることで位置情報をencodeさせて, Positional Encodingを置換 zero paddingに重要性がある → How Much Position Information Do Convolutional Neural Networks Encode? ...
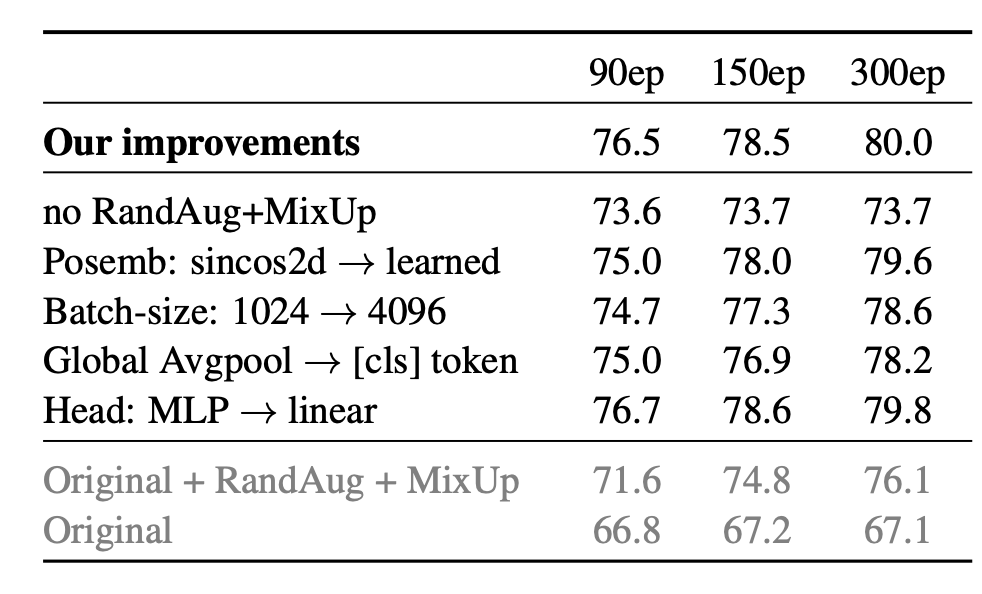
The main differences from [4, 12 are a batch-size of 1024 instead of 4096, the use of global average-pooling (GAP) instead of a class token [2, 11 , fixed 2D sin-cos position embeddings [2, and the introduction of a small amount of RandAugment [3 and Mixup [21 (level 10 and probability 0.2 respectively, which is less than [12). These small changes lead to significantly better performance than that originally reported in [4.
https://arxiv.org/pdf/2205.01580.pdf ...
todo https://webbeginner.hatenablog.com/entry/2020/06/26/120000#:~:text=2つの相関係数の違い&text=ピアソンの相関係数では%E3%80%81変数の値そのもの,順位を利用します%E3%80%82&text=正規分布に従うことを,を作ってい ...