SCDV 📅 2022/2/4 · ☕ 1 min read 文書ベクトルを生成する 文書分類タスク 例えば, wikipediaのページであれば, トピックを意識したベクトルが生成できる word2vecで生成したベクトルをクラスタリング(Gaussian Mixture Model)して, クラスタごとに各ベクトルを修正する ↓ 各クラスタを中心にベクトルが引きつけられている https://gyazo.com/3eb39c40e6ba8fafc1886272245e7857 機械学習 ... #post
協調フィルダリング 📅 2022/2/4 · ☕ 1 min read https://qiita.com/ogi-iii/items/ebfd77003d2dd18af13a https://qiita.com/ynakayama/items/ceb3f6408231ea3d230c ピアソン相関係数 → データが正規化されていないような状況でユークリッド距離よりも良い結果を得られることが多いとされています。 → なぜなら、ある評価者 A が辛口の評価を、評価者 B が甘口の評価をする傾向があったとします。しかしそれぞれのアイテムに対する評価の差に相関があった場合、これが高い相関係数を示すという特徴があるためで ... #機械学習 #post
CANINE 📅 2022/2/3 · ☕ 1 min read 分かち書きフリーのNLPモデル https://gyazo.com/b528d46973abfaf5596a10d8b36ae12c Transformerベース 入力はASCII ASCIIだとでかすぎるので, hashingによって圧縮 トークンは文字 なので, 事前学習時にただ単にmaskingしてもうまく行かない tokenizeしてsub-wordごとにmasking 日本語での実装例 https://github.com/octanove/shiba 機械学習 https://arxiv.org/abs/2103.06874 ... #post
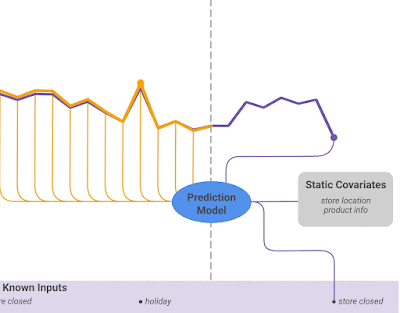
Temporal Fusion Transformer 📅 2022/2/3 · ☕ 1 min read Transformerベース 解釈可能性に秀でている Variable Selection とmulti-head attention 時系列予測 機械学習 ... #post
疲労 📅 2022/2/3 · ☕ 1 min read 「疲労が重なると、自分が工場にいる理由までも忘れ、こういう生活がもたらす最大の誘惑に負けそうになる。もうなにも考えないという誘惑だ。これだけが苦しまずにすむただひとつの方法だから。」 (冨原眞弓編訳『ヴェイユの言葉』みすず書房、P219) シモーヌ・ヴェイユ ... #post
dropout 📅 2022/2/3 · ☕ 1 min read 実質, 複数モデルのアンサンブルになる dropoutによってノードが選択されるので, 非活性化するニューロンが毎回の学習時に異なっていることで、それぞれのパターンで別々のモデルを学習していくことになり、つまり異なるモデルを学習している、とみなすことができます。 https://qiita.com/kuroitu/items/ ... #post
FLOPS 📅 2022/2/2 · ☕ 1 min read FLoating point number Operations Per Second 1秒間に浮動小数点演算が何回できるか ... #post