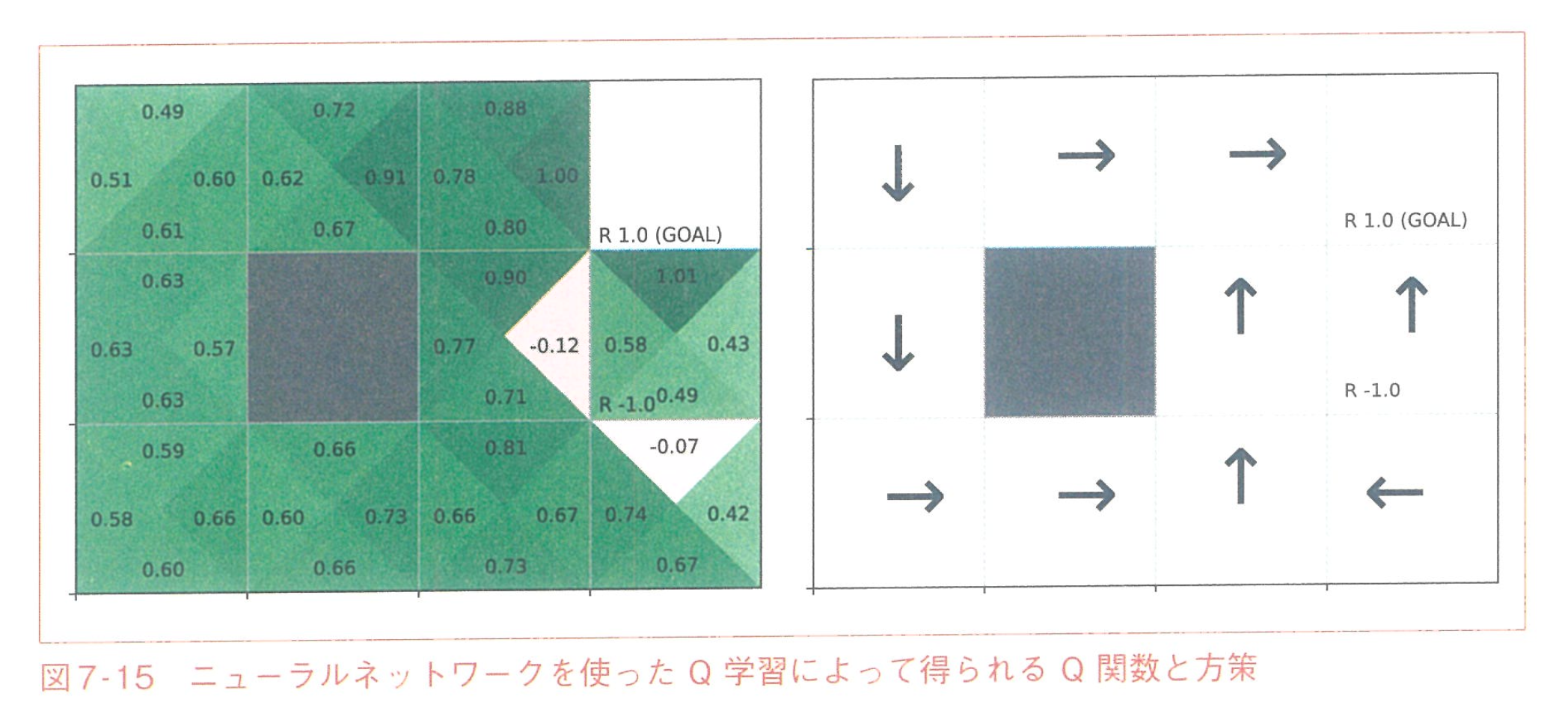
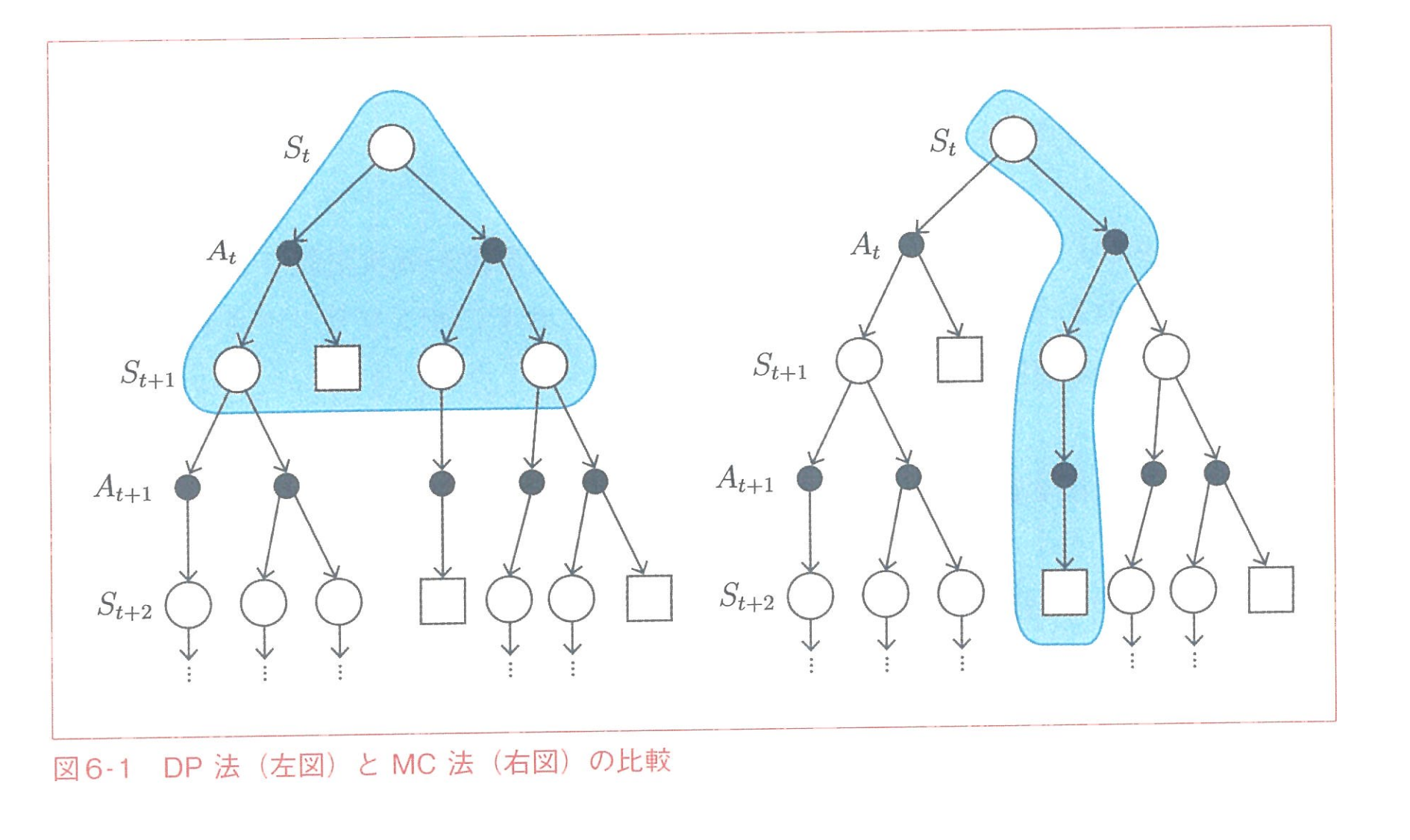
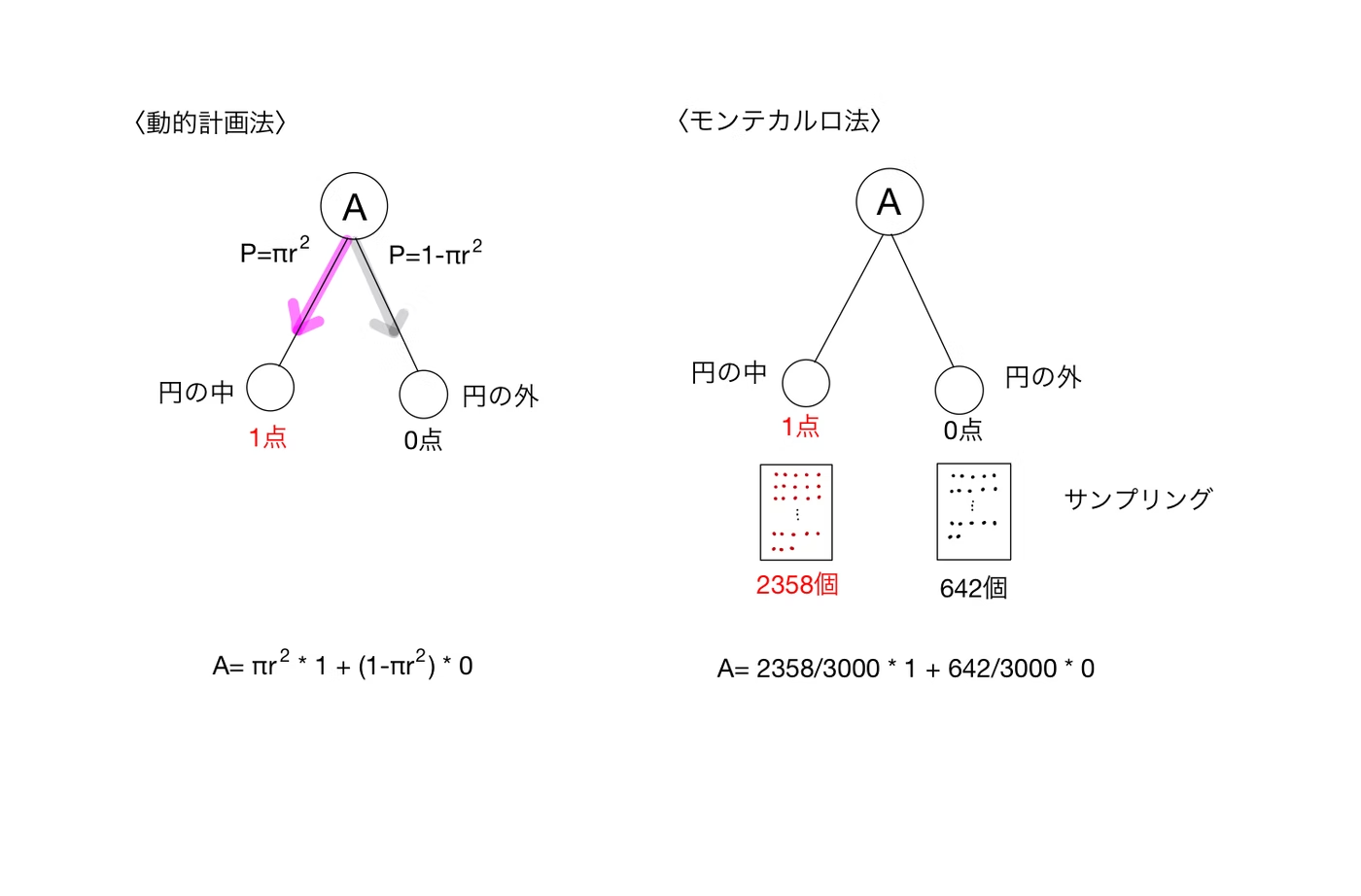
REINFORCE
· ☕ 1 min read
単純な方策勾配方法では $$\nabla J(\theta) = \mathrm{E}_{\tau_\theta} \lbrack \sum_t G(\tau) \nabla log \pi_\theta (A_t|S_t) \rbrack$$ が使われていたが, 全ての時刻 $t$において収益 $G(\tau)$が一律に使用されているのが気がかりである 重要なのは, 時刻 $t$の行動の後の評価であるから, $\lbrack0,t)$の収益はノイズとなり得る そこで, REINFORCEでは以下のように勾配を変更する $$\nabla J(\theta) = \mathrm{E}_{\tau_\theta} \lbrack \sum_t G_t ...