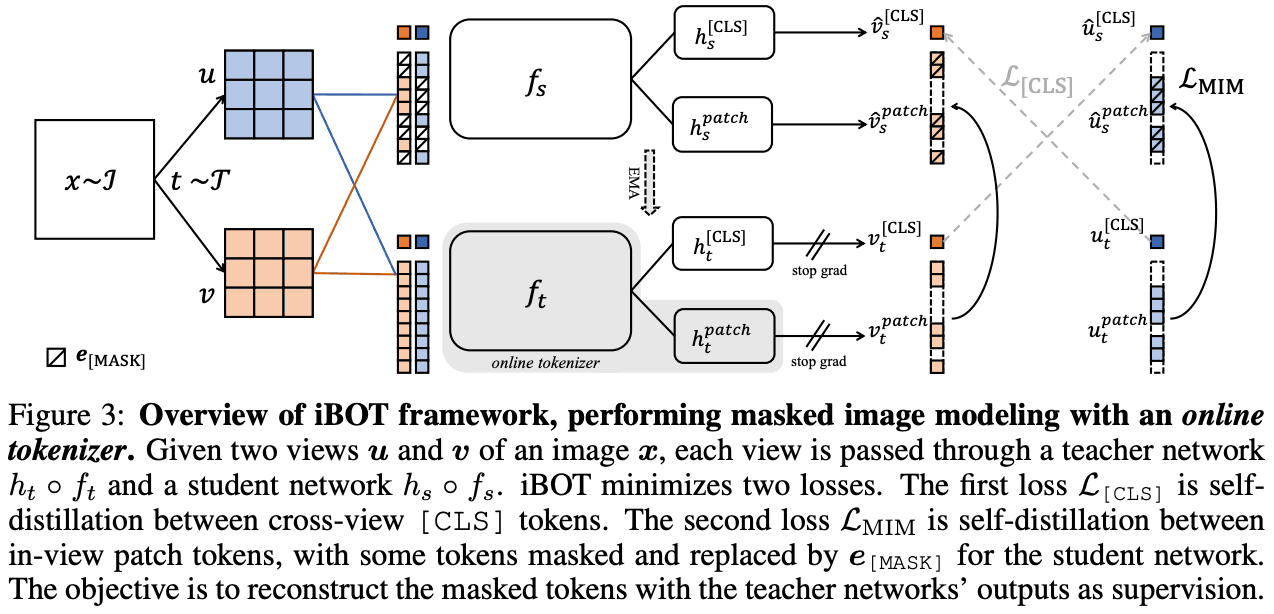
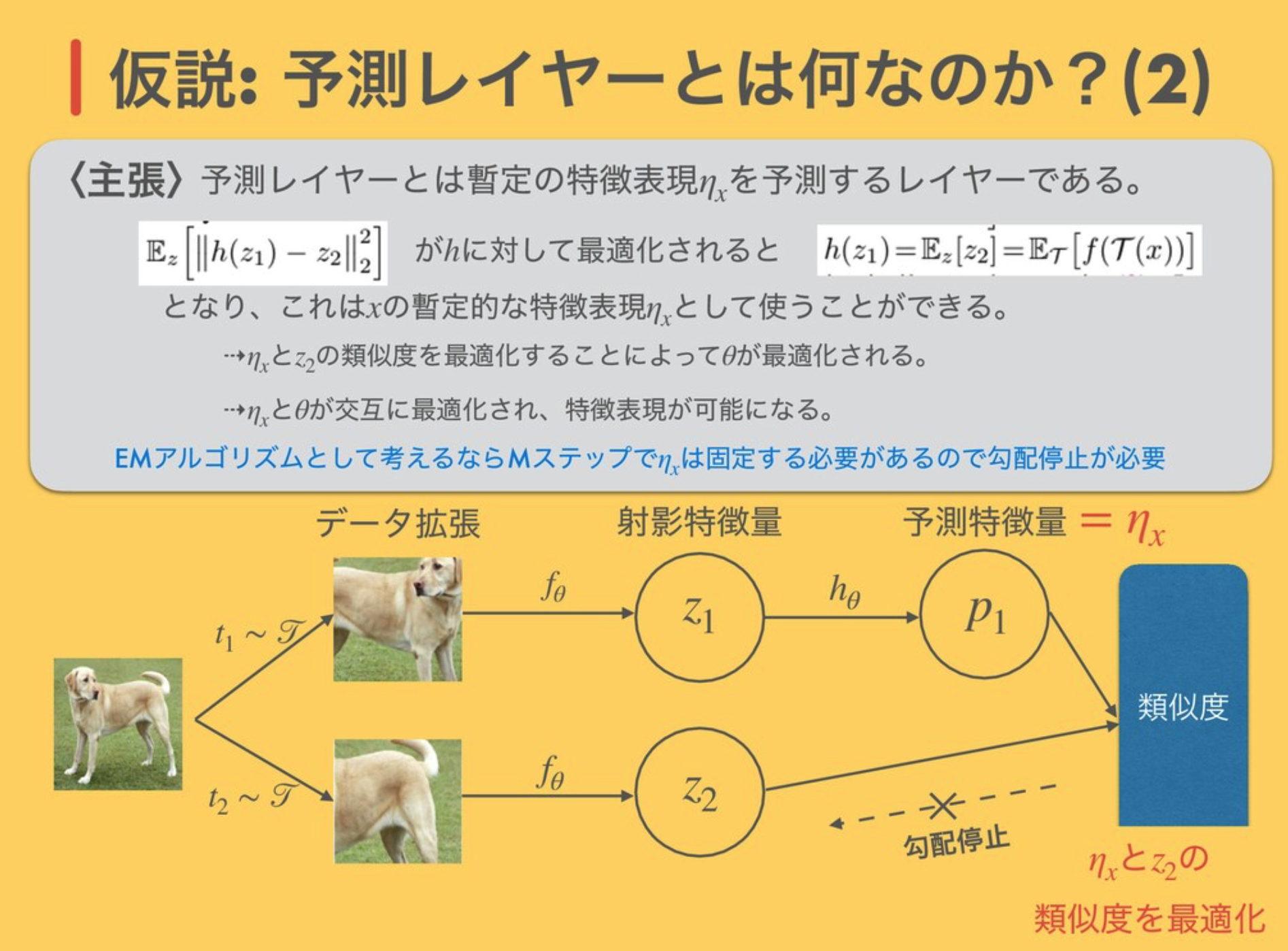
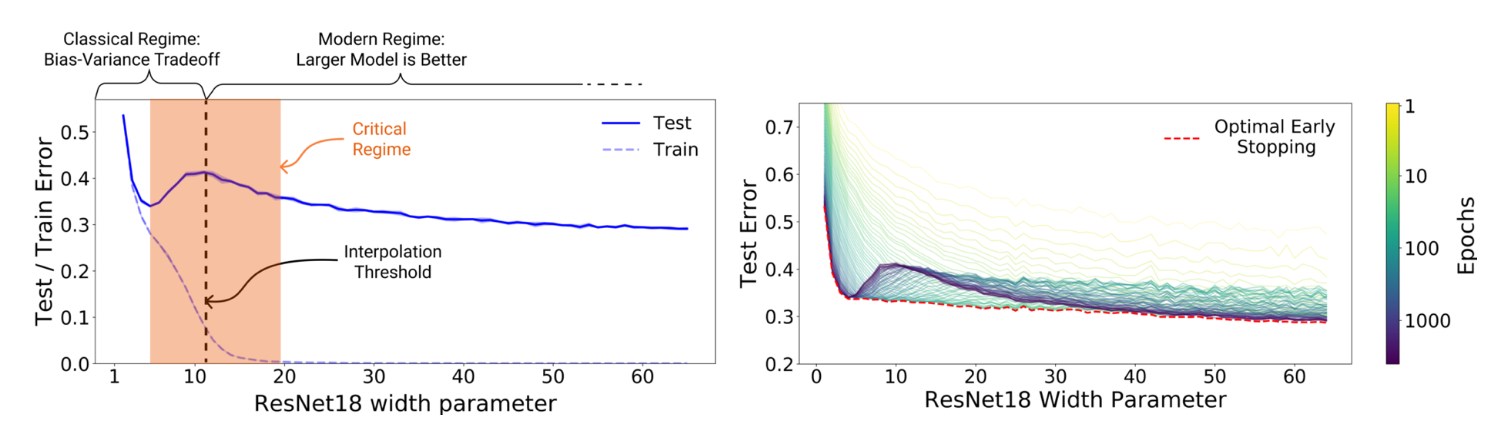
【論文メモ】How Much Position Information Do Convolutional Neural Networks Encode?
· ☕ 1 min read
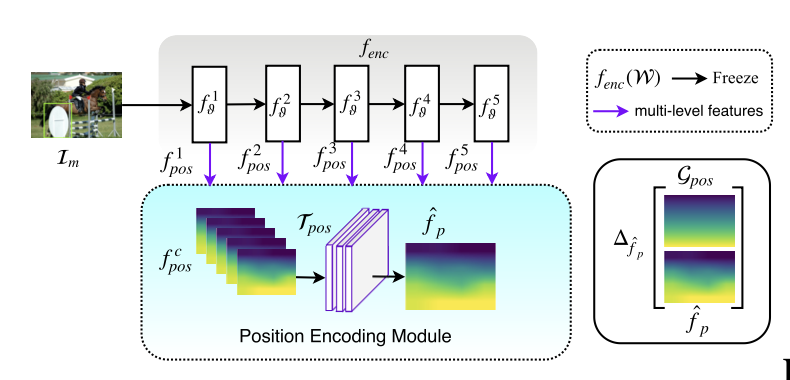
仮説 : CNNは絶対的な位置情報を獲得している PoSENet : 位置情報のmapを予測するモデルを構築して仮説を検証 $f_{enc}$が位置情報がエンコードするなら, $f_{enc}$の中間層の出力から, 位置情報を復元できるはず f1よりもf5のほうが位置mapの精度が高い より深い層のほうがより強く位置情報を保持している 仮説「位置情報は ...