Convは高いロバスト性を持つ 例えば画像のシフトに強かったり ⇒ ViTにConvを導入 Conv自体はパッチ分割 & 線形変換と同じ CvTはパッチ同士が重なり合う Positional Encodingは行わない Convが同じことをやってるらしい … ? How Much Position Information Do Convolutional Neural Networks Encode? ...
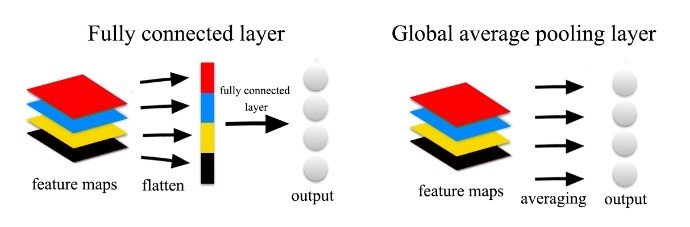
普通のtransformerモデルだとCLSをそのままMLPに通して分類器を構築する 本当にそれで良いの?? BERT系だと CLSを使うパターン BERT / ViT の画像分類タスク 後続のトークンの先頭と最後だけ使うパターン BERTのQAタスク Global Average Poolingで全トークンを圧縮するパターン BeiT の画像分類 がある https://www.ai-shift.co.jp/techblog/2145 todo ...