Sparse Attention 📅 2022/4/7 · ☕ 1 min read https://data-analytics.fun/2021/02/01/understanding-sparse-transformer/ todo ... #post
DALL-E 📅 2022/4/7 · ☕ 1 min read https://data-analytics.fun/2021/05/31/understanding-openai-dalle/ todo ... #post
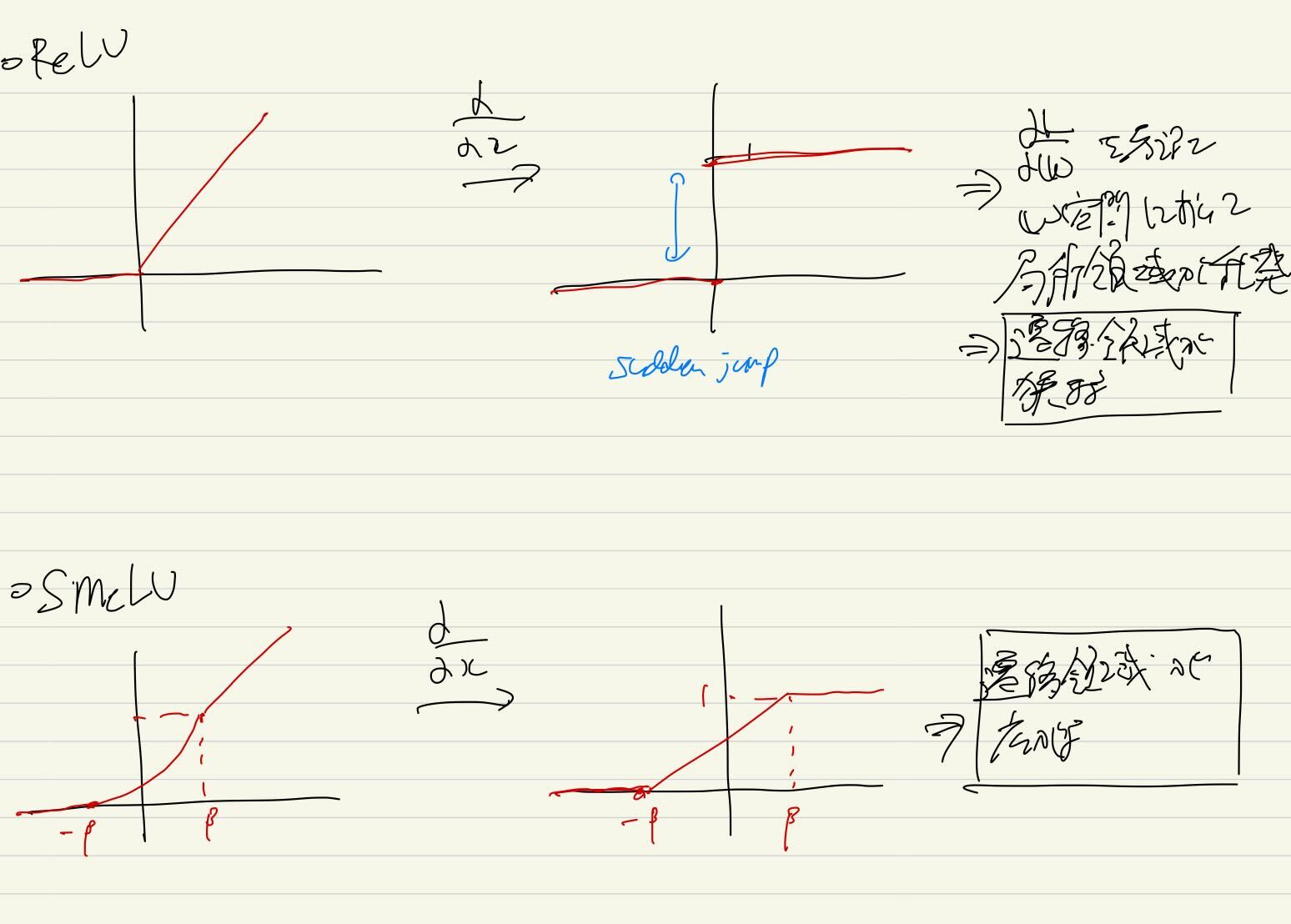
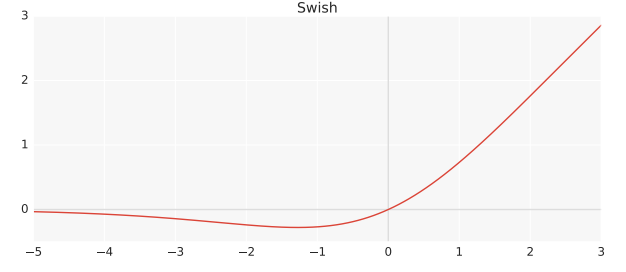
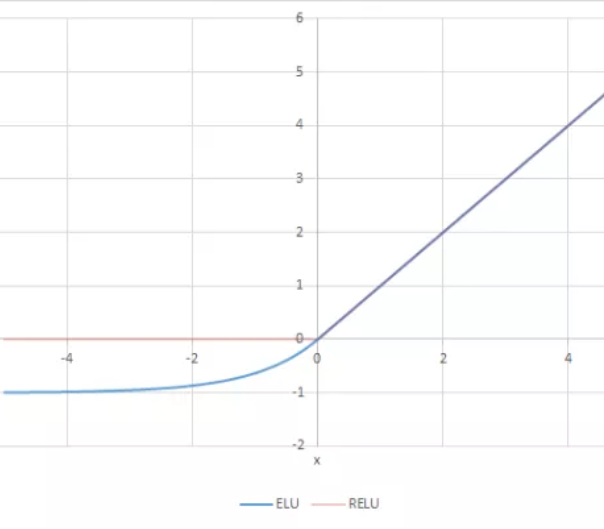
【論文メモ】SmeLU 📅 2022/4/7 · ☕ 1 min read ReLUの原点での急な変化を, 2次関数で補完することでスムーズにした活性化関数 SmeLU (Smooth ReLU)を提案 リコメンデーションシステムにおいては, 再現性の低さは致命的となる ReLU は勾配がジャンプするので(sudden jump), 損失平面に局所領域ができてしまう そのため, 遷移領域が狭まる 遷移領域が狭まってしまうと局所的な遷移しかしないので, モデ ... #論文
Capsule Neural Network 📅 2022/4/5 · ☕ 1 min read 背景: pooling処理によって, 特徴間の相対的な関係性が学習しににくなっている スカラではなくベクトルですべて処理する https://qiita.com/motokimura/items/cae9defed10cb5efeb62 ... #post
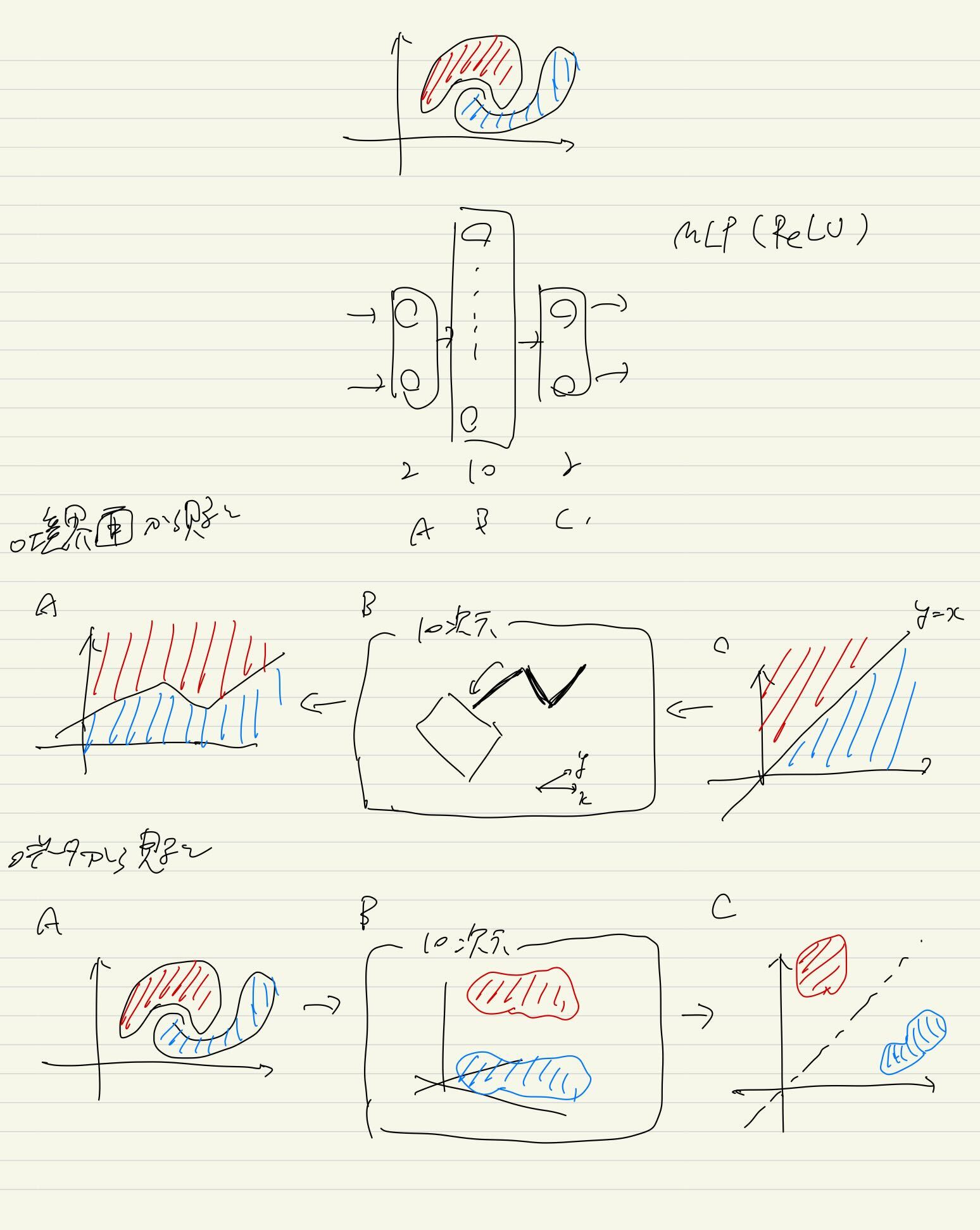
ReLUは如何に関数を近似するか? 📅 2022/4/4 · ☕ 2 min read #* 関数近似 NNは基本的に関数近似器 活性化関数があることで非線形なものも近似することができる 活性化関数がなければ, ただの線形変換にしかならない + 層を重ねる意味がない ReLUはほとんど線形関数と変わらないけど, どのように関数を近似するのか? 大前提 : ReLUは折りたたみを表現できる なので, カクカクで任意の関数を近似できる $$f(x) = ... #ReLU #機械学習 #post
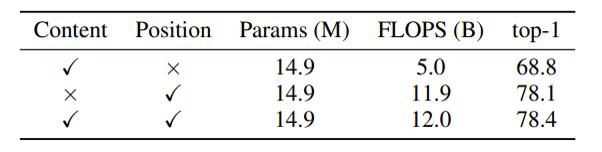
LambdaNetwork 📅 2022/4/3 · ☕ 1 min read MSAと同様, d方向に分割して, 並列処理 行列計算に関しては torchのテンソル積 を参照 Linear Attention LambdaNetsはContentとPositionの2つを計算する Contentのみを出力とすれば, Linear Attentionと同等になる → Efficient Transformer ... #post
torchのテンソル積 📅 2022/4/1 · ☕ 1 min read 三次元 $\times $三次元の行列 1つ目をバッチサイズとして, バッチ単位で行列積 torch.bmm 4次元 $\times $3次元の行列 (j×1×n×m) と (kxm×p)の積は(j,k,n,p)となる バッチなど、行列以外の次元は、ブロードキャストされる。そのため、行列以外の次元はブロードキャストできるものでなければならない。例えば、tensor1が(j×1×n× ... #PyTorch #post