権威DNSサーバ 📅 2022/3/17 · ☕ 1 min read 自分の担当するドメインについて名前解決してくれるDNSサーバ 一方で, 他のDNSサーバなどを辿って名前解決してくれるやつはキャッシュDNSサーバ とも呼ばれる herokuとかでサブドメインのURL持てたりするけど, 自前でDNSサーバを設定してるって感じなのかな? ... #post
多次元正規分布でGibbs Sampling 📅 2022/3/16 · ☕ 7 min read はじめに 先日, 研究室の勉強会で この本 のGibbs Samplingの章(9.3.4)を担当しました. 実際にpythonで実装してみたりしたので, せっかくですから備忘録程度にまとめてみました. なお, 数弱によるガバガバ数学が展開されておりますのでご了承ください. Markov連鎖 Monte Carlo法 ベクトル $\boldsymbol{x}$ が分布 $p(\boldsymbol{x})$ に従う際, 期待値 ... #統計 #MCMC #post
共変量シフト 📅 2022/3/15 · ☕ 1 min read BatchNormによって減らすことができる BNは学習対象のパラメタを持つので注意 共変量シフトを抑えながら, レイヤの表現量を維持するためにパラメタ $\gamma, \beta$ が使われる https://gyazo.com/b54205f667854ac7219c5f7eb002c761 後で読む https://zenn.dev/takoroy/scraps/b26c76a9f94069 ... #機械学習 #post
Layer normalization 📅 2022/3/13 · ☕ 1 min read Post-LN 通常のTransformerだとこっち 性能が高い 不安定 Pre-LN (相対的に)性能は低い 安定 DeepNet DeepNetでは, DeepNormという手法を用いることで性能・安定性ともに向上させる これによって, 層数をバカでか数にしても, 安定して学習させることができる ... #post
重みの初期化 📅 2022/3/12 · ☕ 1 min read nn.init.hogehoge() で初期化できる 例 nn.init.xavier_uniform_(ln.weight) # Xavierの初期値 PyTorchの場合, デフォルトはHe ... #機械学習 #PyTorch #post
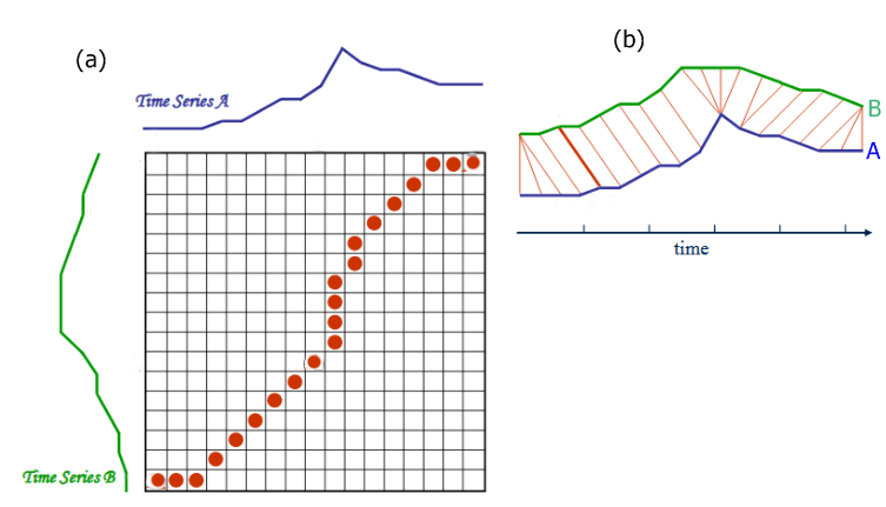
DTW距離 📅 2022/3/10 · ☕ 1 min read 2つの時系列データ $\boldsymbol{s}, \boldsymbol{t}$の類似度を計算 $\boldsymbol{s}, \boldsymbol{t}$をそれぞれ軸としたグリッドに対して, 最小のパスをDTWとする ... #機械学習 #時系列予測 #post
[Heroku] Dockerコンテナ上のpsqlにpg:pullする 📅 2022/3/9 · ☕ 2 min read Herokuでは, pg:pullを通してリモートからローカルへとテーブルを転送(pull)できるんですが, Dockerコンテナ上のpsqlへのpullに手こずったのでメモ. #Docker #DB #post
機械学習の解釈性 📅 2022/3/7 · ☕ 1 min read 特徴量の重要度 重要度を測るには, その特徴量を使えない状態を近似的に作り出せば良い PFI Permutation Feature Importance 特徴量 $X_i$ だけをシャッフルして, シャッフル前と後とで予測結果を比較 ( $X_j (j \neq i)$は固定) 本当に特徴量 $X_i$ が重要なら, シャッフルによって予測結果がブレるはず SHAP SHapley Additive exPlanations 特徴量 $X_i$があるときと無いときとで予測結果を比較 ... #機械学習 #post
時系列予測 📅 2022/3/6 · ☕ 1 min read Statistical and Machine Learning forecasting methods: Concerns and ways forward https://journals.plos.org/plosone/article/file?id=10.1371%2Fjournal.pone.0194889&type=printable ... #post
AR・MA・ARMA・ARIMA・SARIMA 📅 2022/3/6 · ☕ 1 min read AR Autoregressive Model 自己回帰モデル t-1の観測値と誤差項epsで回帰 AR(1) $$y_t = \phi y_{t-1} + \epsilon_t + \mu$$ MA Moving Average 移動平均モデル ARのように観測値メインではなく, 誤差項=差分をメインに計算する MA(1) $$y_t = \phi \epsilon_{t-1} + \epsilon_t + \mu$$ ARMA ARとMAを加算しただけ ARIMA d階差分系列 $y_t - y_{t-d}$をARMAで記述する ARIMA単体でAR・MA・ARMAを表現できる SARIMA ARIMAに加え ... #時系列予測 #post