ARIMA 📅 2022/3/6 · ☕ 1 min read ARIMA: auto regressive integrated moving average 自己回帰移動平均モデル ... #post
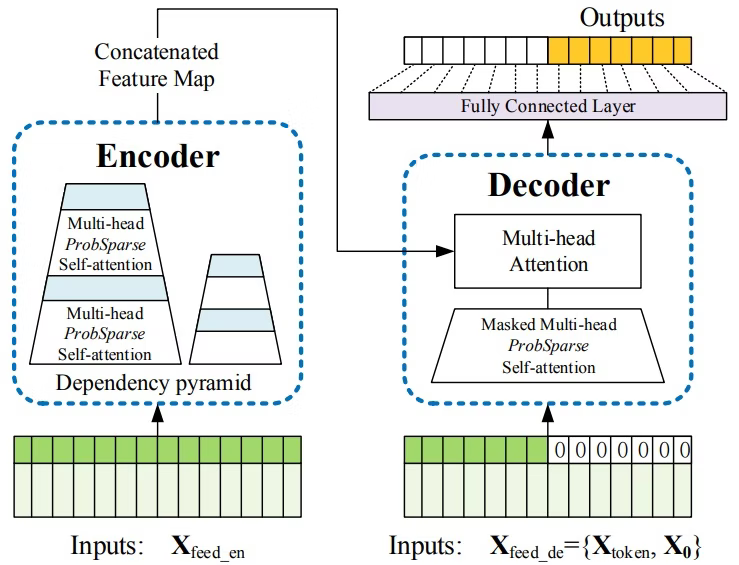
Informer 📅 2022/3/6 · ☕ 1 min read $P(key|query)$が高いqueryを上位X分だけ取り出してself-attentionを計算 - LogSparse Transformerのようなヒューリスティックな手法から脱却 Self-attention Distilling self-attentionの各層をpoolingでダウンサンプリングして蒸留 ... #post
NestJS → Query String(GET)にarray 📅 2022/3/3 · ☕ 1 min read https://github.com/nestjs/swagger/pull/67 array[]=abc&array[]=1234 で {abc,1234}が表現できるらしい これってどこまで標準的なの…? https://stackoverflow.com/questions/6243051/how-to-pass-an-array-within-a-query-string ... #post
内挿・外挿 📅 2022/3/1 · ☕ 1 min read https://atmarkit.itmedia.co.jp/ait/articles/2008/26/news017.html https://science-log.com/雑記topページ/「外挿」と「内挿」の違い/ https://ja.wikipedia.org/wiki/内挿 ... #post
Hugoで技術ブログ作った 📅 2022/2/28 · ☕ 1 min read 何投稿するの → 勉強したことだったり, 技術的なことだったり ・記事「技術ブログが書ける開発をする」に触発された👀 #hello_world #post
Linear Attention: Transformers are RNNs 📅 2022/2/26 · ☕ 1 min read RNNの計算量はO(nd^2) / Transformerの計算量はO(n^2d) $$Attention(Q, K, V) = sortmax(\frac{QK^T}{\sqrt{d_{key}}})V$$ $$Attention(Q, K, V)_i = \frac{\sum_{j=1}^n\exp(q_i^Tk_j)\cdot v_j}{\sum_{j=1}^n\exp(q_i^Tk_j)}$$ O(n^2)の部分をどうにかしたい O(n)に落としたい → Linear Attention とにかく類似度の計算ができれば良いので, 別の類似度計算に置き換えたい simでまとめると $$sim(q, k)=exp(\frac{q^Tk}{\sqrt{d_{key}}})$$ $$Attention(Q, K, V)_i = \frac{\sum_{j=1}^nsim(q_i, k_j)\cdot v_j}{\sum_{j=1}^nsim(q_i, k_j)}$$ q_iとk_jに依存しているので, 乗法に分離できると嬉 ... #post
研究 📅 2022/2/26 · ☕ 1 min read 発見 遠藤さんが「発見」という表現を使っていた 機械学習の研究 → 実験屋に近い側面にもっと注目した方が良い気がする 対象の問題 原因と結果の問題 仮説生成型と仮説検証型 https://xn--w8yz0bc56a.com/hypothesis-making-proving/ 解体と演算子 自然言語処理の研究では、(1)新しいアーキテクチャやモデルを導入する、(2)アーキテクチャやモデルを改良したり、様々なタスクに適用したりして得られた小 ... #post
モード崩壊 📅 2022/2/26 · ☕ 1 min read generatorの学習に失敗して、訓練データの(しばしば多峰性の)分布全体を表現できずに訓練データの最頻値(mode)のみを学習してしまいます。全国民の期待に応える能力がなく、とりあえず多数派のための政策をつくる、みたいなイメージですかね。 引用: https://qiita.com/triwave33/items/a5b3007d31d28bc445c2 GAN Wasserstein GAN ... #post
GAN 📅 2022/2/26 · ☕ 1 min read CNNを使えば良い → DCGAN GANの問題点 学習が安定しない 勾配消失問題が発生する モード崩壊が起きる Wasserstein GANの導入によって改善することができる 損失関数でJSダイバージェンス KLダイバージェンス じゃなくてJSのほうが精度が出るらしい ただ, JSダイバージェンスのせいで勾配消失・モード崩壊が起きているとも言えるみたい なので, 損失関数 ... #post
Wasserstein GAN 📅 2022/2/26 · ☕ 1 min read Wasserstein距離を用いるGAN Wasserstein距離は閉じた形で解が得られない なので, **iterativeに解を求める必要がある ** 普通のGANはDiscriminatorが偽物を見破れるように学習する 一方でWGANでは… DiscrimianatorはひたすらWasserstein距離を正確 ... #post