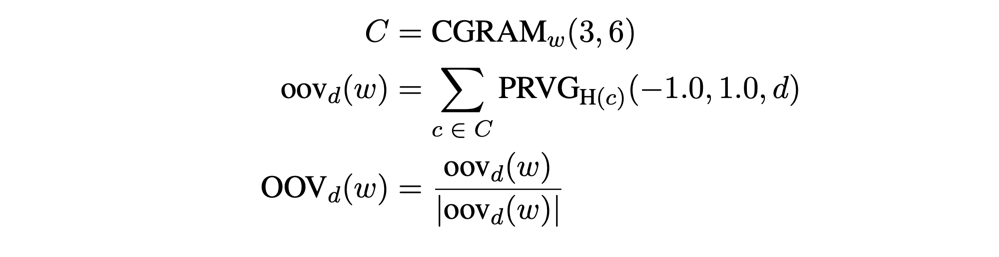· ☕ 1 min read
最初にメモリ上に展開するため, めっちゃ速い OOV (Out-of-Vocabulary) に強いらしい 似ているOOV同士は近い所に埋め込みたい (1) 似てる単語があったら, その単語に近くなるように埋め込みたい (2) $oov_d(w) = [0.3OOV_d(w)+0.7MATCH_3(3,6,w)$] (1) → 似ている単語は同じ感じにしたい = OOV (2) → 似てる単語があったら, その単語に近くなるように埋め込みたい = MATCH 与えられた単語に近い単語上位3つの平均を取る mag ...