【論文メモ】GSAM - Surrogate Gap Minimization Improves Sharpness-Aware Training
· ☕ 2 min read
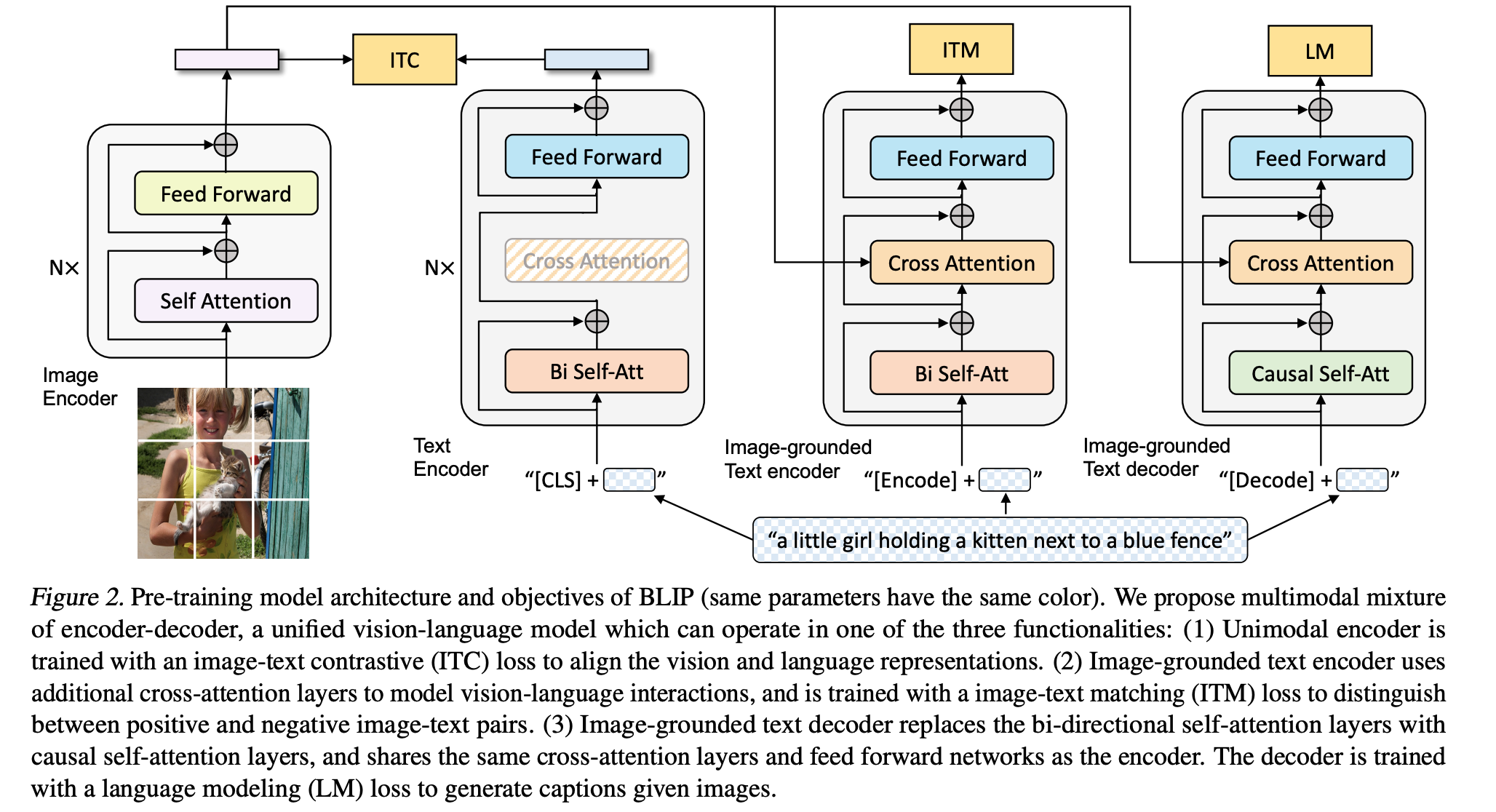
はじめに SAMの改良 (SAM : Sharpness-Aware Minimization) Surrogate Gap Minimization Improves Sharpness-Aware Training 論文メモ 問題提起 SAMの計算式では, 本当にフラットな損失点を見つけているとは言えない $$L_\mathcal{S}^\text{SAM}(\mathbf{w}) \triangleq \max_{|\mathbf{\epsilon}|_p\leq\rho} L_\mathcal{S}(\mathbf{w}+\mathbf{\epsilon})$$ 例えば下の図では, 近傍 $f_p$について最適化すると, SAMの場合, 青に収束してしまう危険がある 本当に見るべきは以下に定義するsurrogate gap $h(x)$ $$h(x) := f_p(x) - f(x)$$ surrogate gap $h(x)$については, H ...