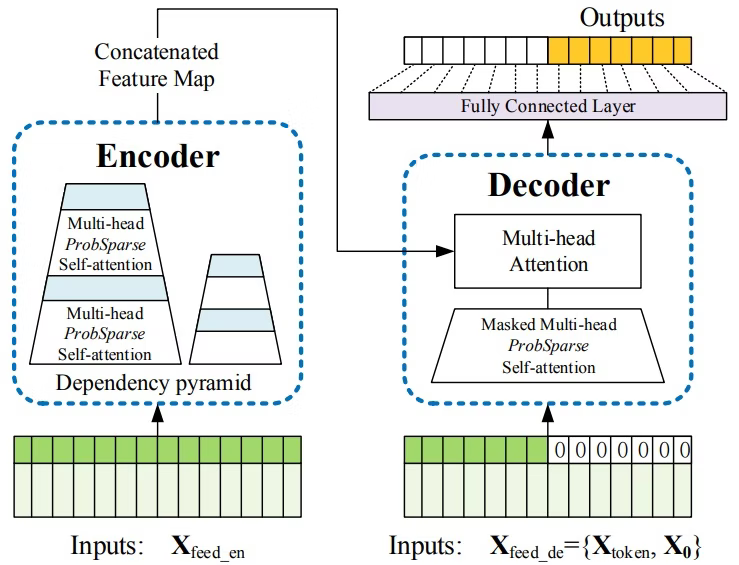
機械学習の解釈性
· ☕ 1 min read
特徴量の重要度 重要度を測るには, その特徴量を使えない状態を近似的に作り出せば良い PFI Permutation Feature Importance 特徴量 $X_i$ だけをシャッフルして, シャッフル前と後とで予測結果を比較 ( $X_j (j \neq i)$は固定) 本当に特徴量 $X_i$ が重要なら, シャッフルによって予測結果がブレるはず SHAP SHapley Additive exPlanations 特徴量 $X_i$があるときと無いときとで予測結果を比較 ...