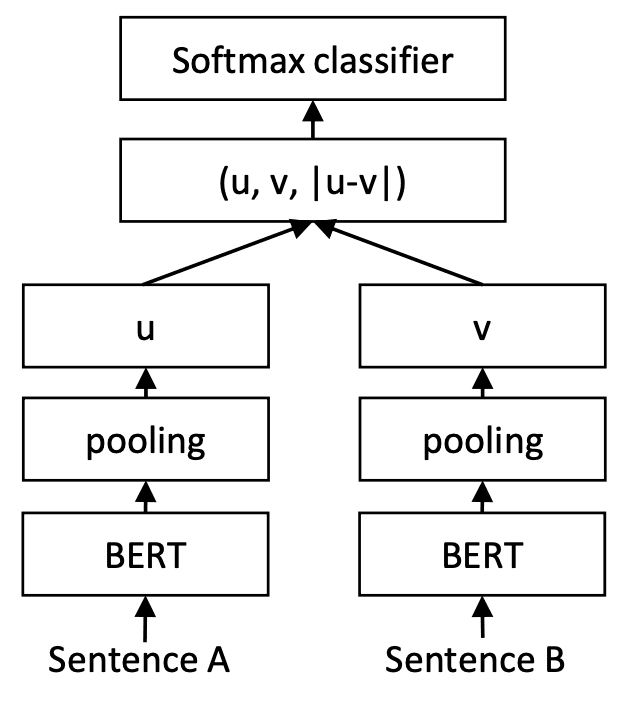
情報エントロピー
· ☕ 1 min read
要件 確率を用いたい ある独立な事象について, 情報量は加法的でありたい → つまり, ある独立な事象 $x, y$ について, $f(x,y) = f(x) + f(y)$ これらを満たすには, 積が加法的になれば良いので, $log$ が使えそうだ よって, 情報量を $f(x) = -log(p(x)) $ とする この”情報量”についての期待値を計算したものをエントロピーと定義する $H[y|x$ = -\sum_{x \in X} p(x) log(p(x)) ] ...