残差接続 📅 2022/7/5 · ☕ 1 min read 残差の何がうれしいか? そのモジュールが特徴量変換器として必要なければスキップすることができる 言い換えれば, 恒等変換が起点となるので, 恒等写像が簡単に実現できる ... #機械学習 #post
リプシッツ連続 📅 2022/7/4 · ☕ 1 min read 関数 $f(x)$ がリプシッツ連続である $\Leftrightarrow \exist k, \forall x_1, x_2 , |f(x_1)-f(x_2)|\leq k|x_1-x_2|$ 機械学習において, 摂動 $e$を与えた場合の解析に良く用いられるword (ホントか?) すなわち, リプシッツ連続であれば, $|f(x+e)-f(x)|\leq k|e|$ が成り立つので, 摂動に強い分類器であると言える. ... #数学 #post
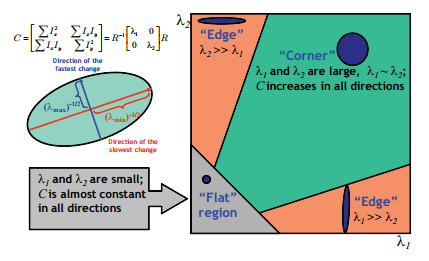
Hessianの固有値とフラットさ 📅 2022/6/30 · ☕ 1 min read Hessianの固有値は等高線の密度を表現する どの方向に勾配が, どの程度早く移動するか なので, 最大固有値が小さいと損失平面はフラットになる (等高線の密度がどの方向にも低い) ... #数学 #post
CORS 📅 2022/6/29 · ☕ 1 min read Cross-Origin Resource Sharing オリジンとは, プロトコル + ドメイン + ポート のこと つまり, CORSとは同じオリジン間でのリソースの共有のこと なので, オリジンが異なるリクエストは基本CORSエラーが起きる ... #Network #post
「村上春樹、河合隼雄に会いにいく」 📅 2022/6/29 · ☕ 4 min read p132-134 村上: ただ、ぼくが「ねじまき鳥クロニクル」に関 して感ずるのは、何がどういう意味を持っているの かということが、自分でもまったくわからないとい うことなのです。これまで書いてきたどの小説にも まして、わからない。 たとえば、「世界の終りとハードボイルド・ワン ダーランド」は、かなり同じような手法で書いたも のではあるのですが、ある ... #読書録 #post
Twitter 📅 2022/6/28 · ☕ 1 min read AboutMeでTweetの有害性について書いたが, とても良く言語化されている以下の記事達を発見した. /shokai/承認欲求の刺激につながる機能を全て排除する /shokai/人間には承認欲求を刺激すると知能が下がるバグがある ... #misc #post
REINFORCE 📅 2022/6/27 · ☕ 1 min read 単純な方策勾配方法では $$\nabla J(\theta) = \mathrm{E}_{\tau_\theta} \lbrack \sum_t G(\tau) \nabla log \pi_\theta (A_t|S_t) \rbrack$$ が使われていたが, 全ての時刻 $t$において収益 $G(\tau)$が一律に使用されているのが気がかりである 重要なのは, 時刻 $t$の行動の後の評価であるから, $\lbrack0,t)$の収益はノイズとなり得る そこで, REINFORCEでは以下のように勾配を変更する $$\nabla J(\theta) = \mathrm{E}_{\tau_\theta} \lbrack \sum_t G_t ... #強化学習 #post
強化学習 📅 2022/6/27 · ☕ 2 min read 引用: ゼロから作るDeep Learning ❹ ―強化学習編 価値を如何に定めるか? 状態 $s$と方策 $\pi$で決める→状態価値関数 状態 $s$と方策 $\pi$と行動 $a$で決める→行動価値関数 (Q関数) 方策 $\pi$はグラフ遷移そのものと等しい存在 例えば, $\pi(a|s)$は状態 $s$から行動 $a$を実行する確率を表す 価値ベース手法 価値 ... #post
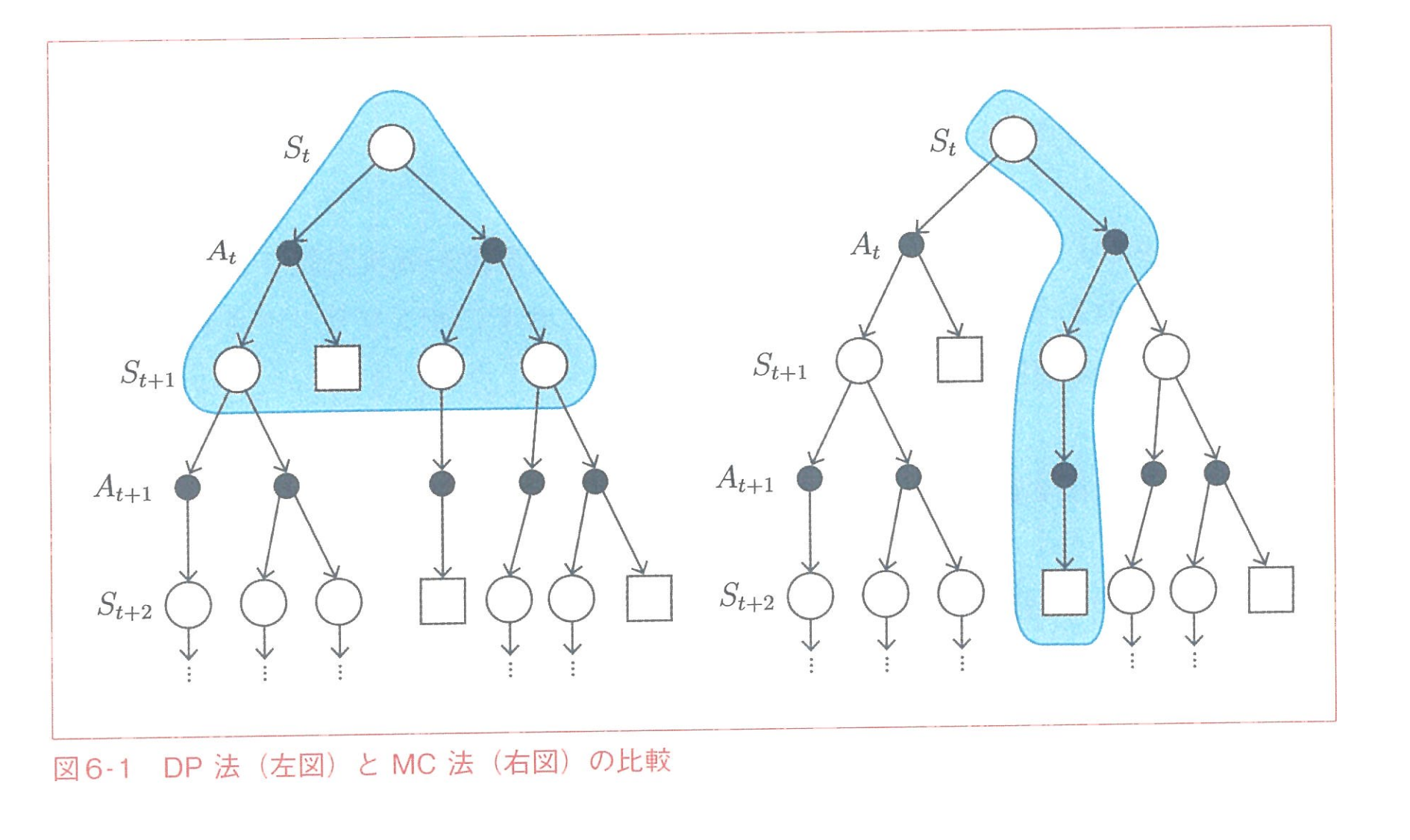
TD法 📅 2022/6/26 · ☕ 1 min read DP法とMC法の中間 MCの場合, 終端までわかってないと使えなかった なので, 1ステップの状態に対してサンプリングを行い, 評価→行動 引用: ゼロから作るDeep Learning ❹ ―強化学習編 ... #強化学習 #post