JaSPICE: Automatic Evaluation Metric Using
Predicate-Argument Structures for Image
Captioning Models
Yuiga Wada
,
Kanta Kaneda ,
Komei
Sugiura
Keio University
CoNLL 2023
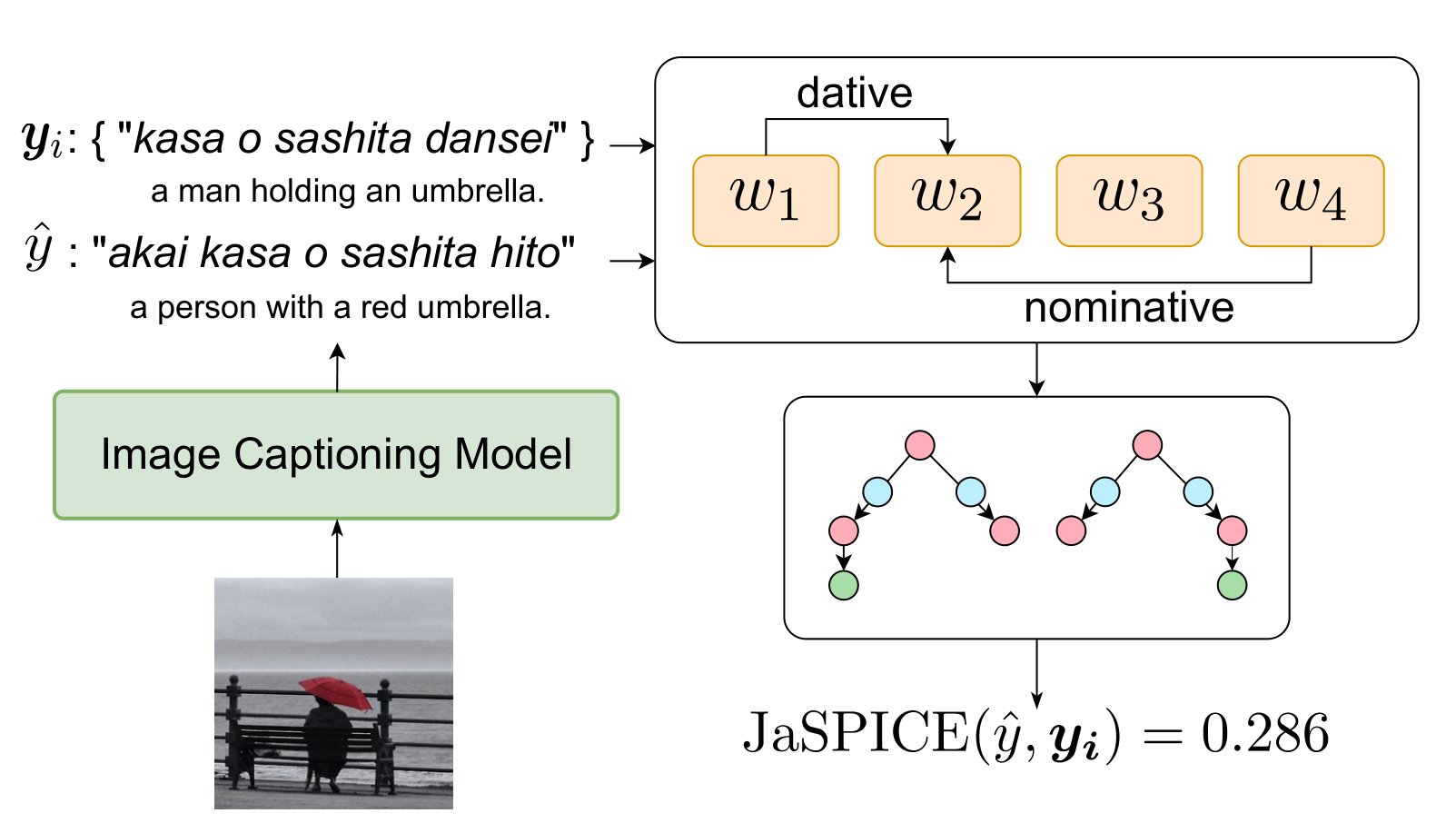
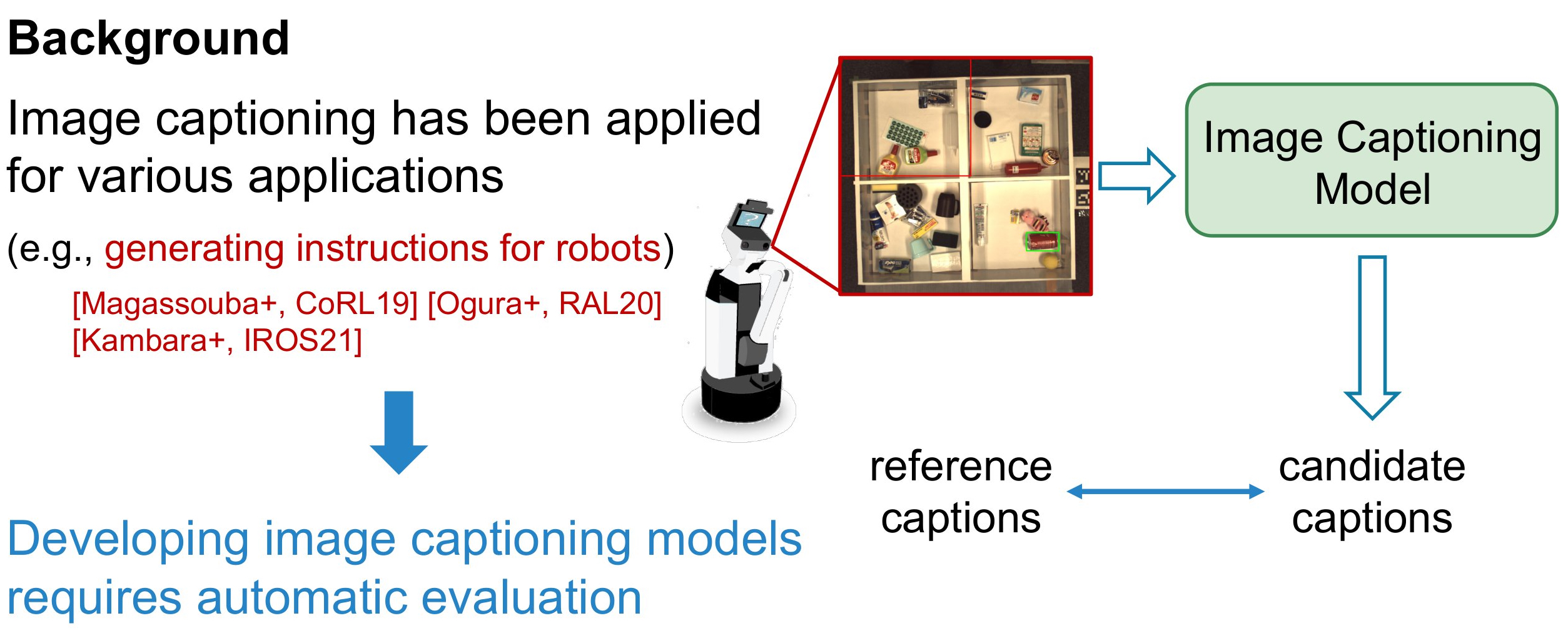
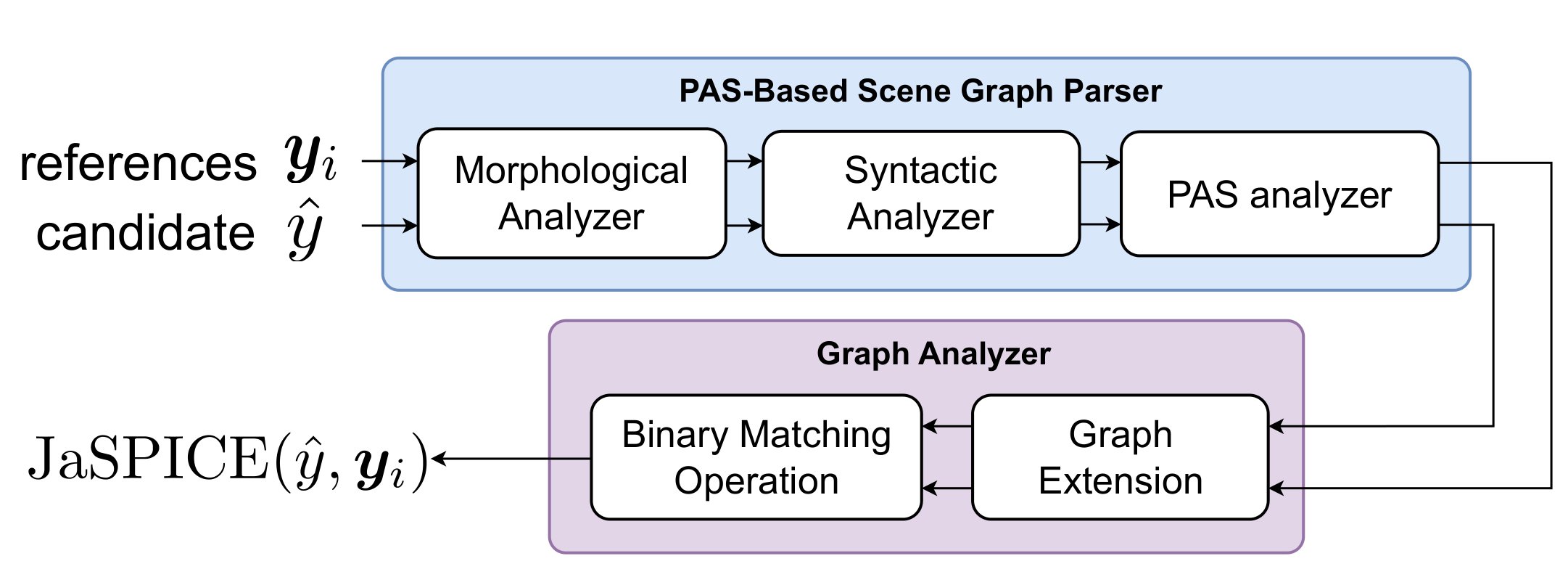

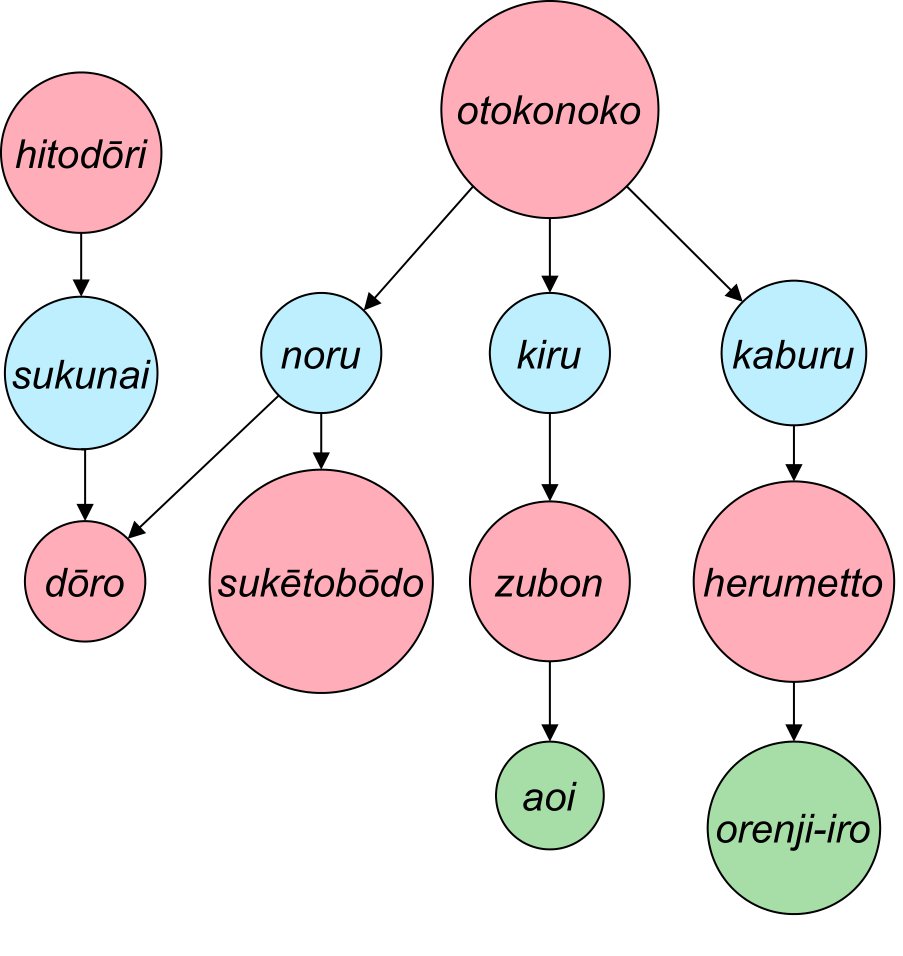
Fig 1. Example of an image and corresponding scene graph. The pink, green, and light blue nodes represent objects, attributes, and relationships, respectively, and the arrows represent dependencies.
The caption is “hitodo ̄ri no sukunaku natta do ̄ro de, aoi zubon o kita
otokonoko ga orenji-iro no herumetto o kaburi, suke ̄tobo ̄do ni notte iru.”
(“on a deserted street, a boy in blue pants and an orange helmet rides a skateboard.”)
Table Ⅰ. Correlation coefficients between each automatic evaluation metric
and
the human evaluation for STAIR Captions [Yoshikawa+, ACL17].
| Metric | Pearson | Spearman | Kendall |
|---|---|---|---|
| BLEU | 0.296 | 0.343 | 0.260 |
| ROUGE | 0.366 | 0.340 | 0.258 |
| METEOR | 0.345 | 0.366 | 0.279 |
| CIDER | 0.312 | 0.355 | 0.269 |
| JaSPICE | 0.501 | 0.529 | 0.413 |
Table Ⅱ. Correlation coefficients between each automatic evaluation metric
and
the human evaluation for PFN-PIC [Hatori+, ICRA18].
| Metric | Pearson | Spearman | Kendall |
|---|---|---|---|
| BLEU | 0.484 | 0.466 | 0.352 |
| ROUGE | 0.500 | 0.474 | 0.365 |
| METEOR | 0.423 | 0.457 | 0.352 |
| CIDER | 0.416 | 0.462 | 0.353 |
| JaSPICE | 0.572 | 0.587 | 0.452 |
Table Ⅲ. Results of the ablation study
| Condition | Parser |
Graph Extension |
Pearson | Spearman | Kendall | M |
|---|---|---|---|---|---|---|
| (i) | UD | 0.398 | 0.390 | 0.309 | 1465 | |
| (ii) | UD | ✔ | 0.399 | 0.390 | 0.309 | 1430 |
| (iii) | JaSGP | 0.493 | 0.524 | 0.410 | 1417 | |
| Our Metric | JaSGP | ✔ | 0.501 | 0.529 | 0.413 | 1346 |
@inproceedings{wada2023,
title = {{JaSPICE: Automatic Evaluation Metric Using Predicate-Argument Structures for Image Captioning Models}},
author = {Wada, Yuiga and Kaneda, Kanta and Sugiura, Komei},
year = 2023,
booktitle = {Proceedings of the 27th Conference on Computational Natural Language Learning (CoNLL)}
}1. Download and build docker image.
git clone [email protected]:keio-smilab23/JaSPICE.git
cd JaSPICE
pip install -e .
docker build -t jaspice .
docker run -d -p 2115:2115 jaspice
2. Add the following code. (like pycocoevalcap.)
from jaspice.api import JaSPICE
batch_size = 16
jaspice = JaSPICE(batch_size,server_mode=True)
_, score = jaspice.compute_score(references, candidates)
references
[Magassouba+, CoRL19] A. Magassouba et al., “Multimodal Attention Branch Network for Perspective-Free
Sentence Generation,” in CoRL, 2019, pp. 76–85.
[Ogura+, RAL20] T. Ogura, et al., “Alleviating the Burden of Labeling: Sentence Generation by Attention
Branch Encoder- Decoder Network,” IEEE RAL, vol. 5, no. 4, pp. 5945–5952, 2020.
[Kambara+, IROS21] M. Kambara and K. Sugiura, “Case Relation Transformer: A Cross- modal Language
Generation Model for Fetching Instructions,” IROS, 2021.
[Yoshikawa+, ACL17] Y. Yoshikawa et al., “STAIR Captions: Constructing a Large- Scale Japanese Image
Caption Dataset,” in ACL, 2017, pp. 417–421.
[Hatori+, ICRA18] J. Hatori, et al., “Interactively Picking Real-World Objects with Unconstrained Spoken
Language Instructions,” in ICRA, 2018, pp. 3774–3781.