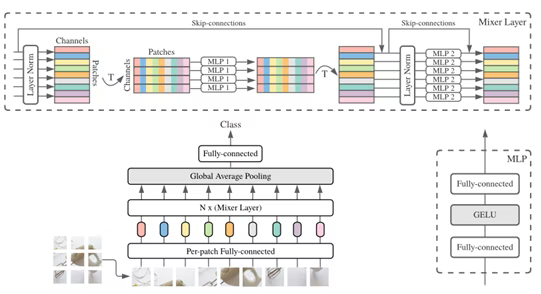
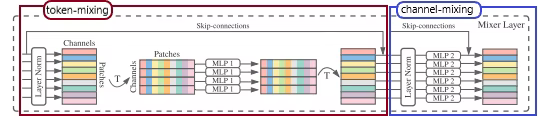
torch.view
同じ順序でメモリ上に展開されてないとダメだから注意 1 2 3 4 >>> torch.t(x).view(-1, 2) Traceback (most recent call last): File "<stdin>", line 1, in <module> RuntimeError: invalid argument 2: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Call .contiguous() before .view(). at /Users/soumith/code/builder/wheel/pytorch-src/aten/src/TH/generic/THTensor.cpp:237 1 2 3 4 5 6 x = torch.Tensor([[[ 1., 5., 9.], [ 2., 6., 10.], [ 3., 7., 11.], [ 4., 8., 12.]]]) x = x.unsqueeze(0) print(x.transpose(-1,-2).view(1,-1,2)) ↑ これだとメモリ上に展開されてないからダメ 1 2 3 x = torch.Tensor([[1,2,3,4],[5,6,7,8],[9,10,11,12]]) x = x.unsqueeze(0).transpose(-1,-2) print(x.transpose(-1,-2).view(1,-1,2)) ↑こっちだとOK