NeRFを使えば,点群・メッシュ・任意視点動画が作れるのでやってみた 今回は愛飲するRedBullを被写体にしてみるヨ! 任意視点動画 (GIF版) 任意視点動画 (動画版) Your browser does not support the video tag. 点群 NeRFとnerfstudioについて簡潔に説明 ボリュームレンダリング ある点 $x$と方向 $d$を入力として $(c,\sigma)$を出力 ...
EMNLP2023に行ってきた ポスター発表の画 面白かった発表 (マイベスト) Accelerating Toeplitz Neural Network with Constant-time Inference Complexity 会場で唯一見つけたSSM論文 (e.g., Hungry Hungry Hippos: Towards Language Modeling with State Space Models) Toeplitz Neural NetworksをSSMに変換し,閉形式で記述→DFTで効率的に解くというめちゃくちゃ胸躍る研究. 著者から直接聞いた話によると,最近Albert Guが出したMambaよりかなり ...
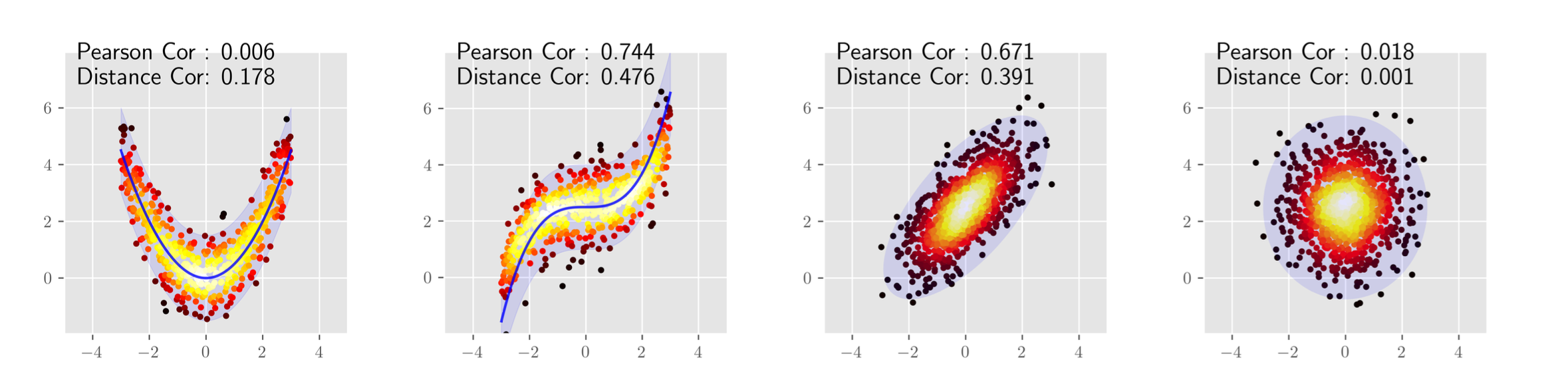
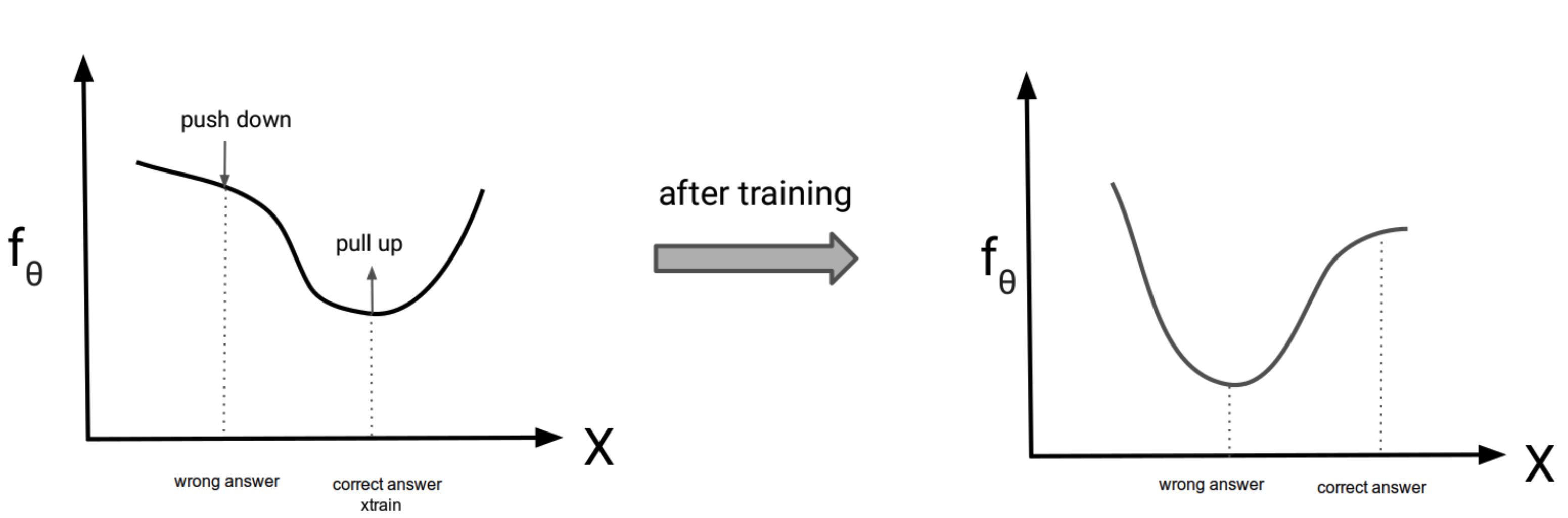
Energy Based Model 生成モデルによく用いられる 拡散モデルとも関係が深い 分類回帰問題についてはYour classifier is secretly an energy based model and you should treat it like oneを参照 GANやVAE同様, データ $x$は何らかの高次元確率分布 $p(x)$からサンプリングされたものと仮定する EBMでは以下のように確率分布 $p(x)$を仮定し, $E_{\theta}(\boldsym ...
STAIR MSCOCOにキャプションを付与 全部で820,310件のキャプション http://captions.stair.center/ Yuya Yoshikawa, Yutaro Shigeto, and Akikazu Takeuchi, “STAIR Captions: Constructing a Large-Scale Japanese Image Caption Dataset”, Annual Meeting of the Association for Computational Linguistics (ACL), Short Paper, 2017. YJ Captions 26k Dataset こちらもMSCOCOにキャプションを付与したもので, ACL2016 キャプション数がSTAIRの1/6程度 https://github.com/yahoojapan/YJCaptions Takashi Miyazaki and Nobuyuki Shimizu. 2016. Cross-Lingual Image Caption Generation. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1780 ...