ReferItGame
· ☕ 1 min read
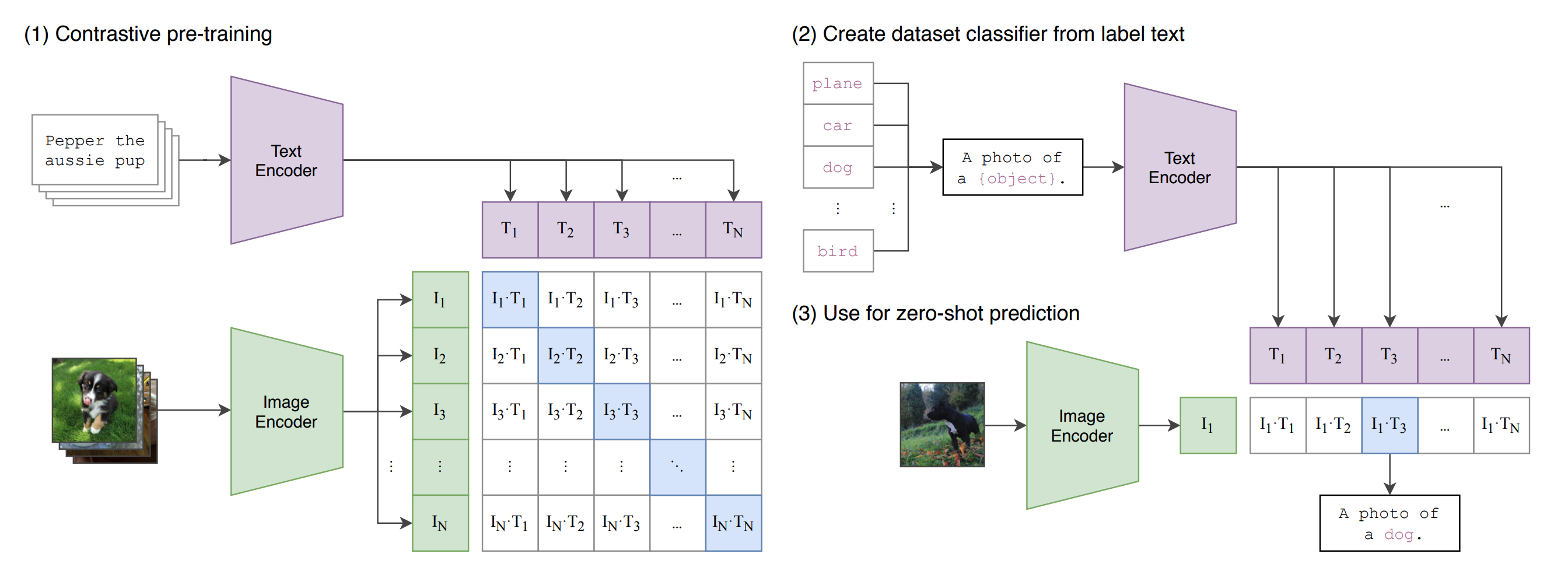
画像-参照表現におけるデータセット 割と大きいデータセットみたい the game has produced a dataset containing 130,525 expressions, referring to 96,654 distinct objects, in 19,894 photographs of natural scenes. ゲーム形式でアノテーションされる アノテータは二人 二人でアノテーションを行う まずプレイヤーAがキャプションを考える 次にもうひとりのプレイヤーBがそのキャプションが正しいかを当てる BはAのキャプションが指している物体をクリ ...