ReLUは如何に関数を近似するか? 📅 2022/4/4 · ☕ 2 min read #* 関数近似 NNは基本的に関数近似器 活性化関数があることで非線形なものも近似することができる 活性化関数がなければ, ただの線形変換にしかならない + 層を重ねる意味がない ReLUはほとんど線形関数と変わらないけど, どのように関数を近似するのか? 大前提 : ReLUは折りたたみを表現できる なので, カクカクで任意の関数を近似できる $$f(x) = ... #ReLU #機械学習 #post
共変量シフト 📅 2022/3/15 · ☕ 1 min read BatchNormによって減らすことができる BNは学習対象のパラメタを持つので注意 共変量シフトを抑えながら, レイヤの表現量を維持するためにパラメタ $\gamma, \beta$ が使われる https://gyazo.com/b54205f667854ac7219c5f7eb002c761 後で読む https://zenn.dev/takoroy/scraps/b26c76a9f94069 ... #機械学習 #post
重みの初期化 📅 2022/3/12 · ☕ 1 min read nn.init.hogehoge() で初期化できる 例 nn.init.xavier_uniform_(ln.weight) # Xavierの初期値 PyTorchの場合, デフォルトはHe ... #機械学習 #PyTorch #post
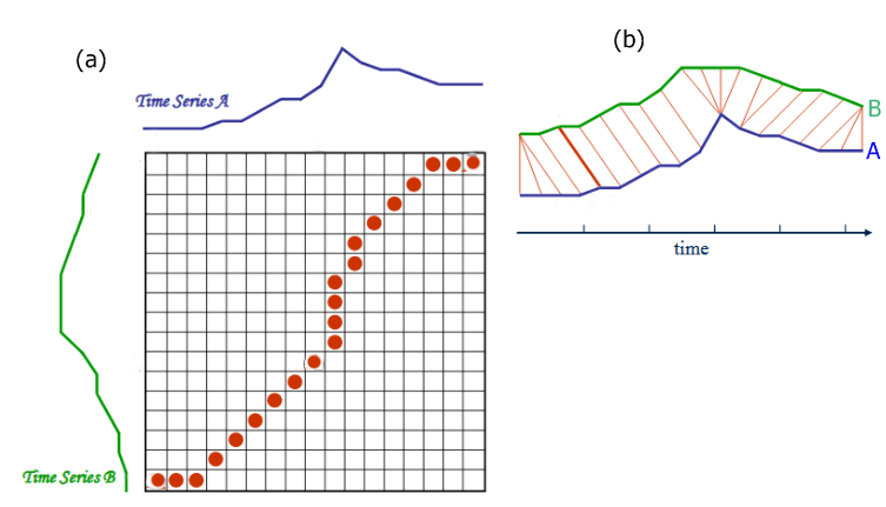
DTW距離 📅 2022/3/10 · ☕ 1 min read 2つの時系列データ $\boldsymbol{s}, \boldsymbol{t}$の類似度を計算 $\boldsymbol{s}, \boldsymbol{t}$をそれぞれ軸としたグリッドに対して, 最小のパスをDTWとする ... #機械学習 #時系列予測 #post
機械学習の解釈性 📅 2022/3/7 · ☕ 1 min read 特徴量の重要度 重要度を測るには, その特徴量を使えない状態を近似的に作り出せば良い PFI Permutation Feature Importance 特徴量 $X_i$ だけをシャッフルして, シャッフル前と後とで予測結果を比較 ( $X_j (j \neq i)$は固定) 本当に特徴量 $X_i$ が重要なら, シャッフルによって予測結果がブレるはず SHAP SHapley Additive exPlanations 特徴量 $X_i$があるときと無いときとで予測結果を比較 ... #機械学習 #post
協調フィルダリング 📅 2022/2/4 · ☕ 1 min read https://qiita.com/ogi-iii/items/ebfd77003d2dd18af13a https://qiita.com/ynakayama/items/ceb3f6408231ea3d230c ピアソン相関係数 → データが正規化されていないような状況でユークリッド距離よりも良い結果を得られることが多いとされています。 → なぜなら、ある評価者 A が辛口の評価を、評価者 B が甘口の評価をする傾向があったとします。しかしそれぞれのアイテムに対する評価の差に相関があった場合、これが高い相関係数を示すという特徴があるためで ... #機械学習 #post
キャリブレーションについて 📅 2021/12/31 · ☕ 1 min read https://data-analysis-stats.jp/機械学習/キャリブレーション(calibrated-classifiers)/ ... #機械学習 #post