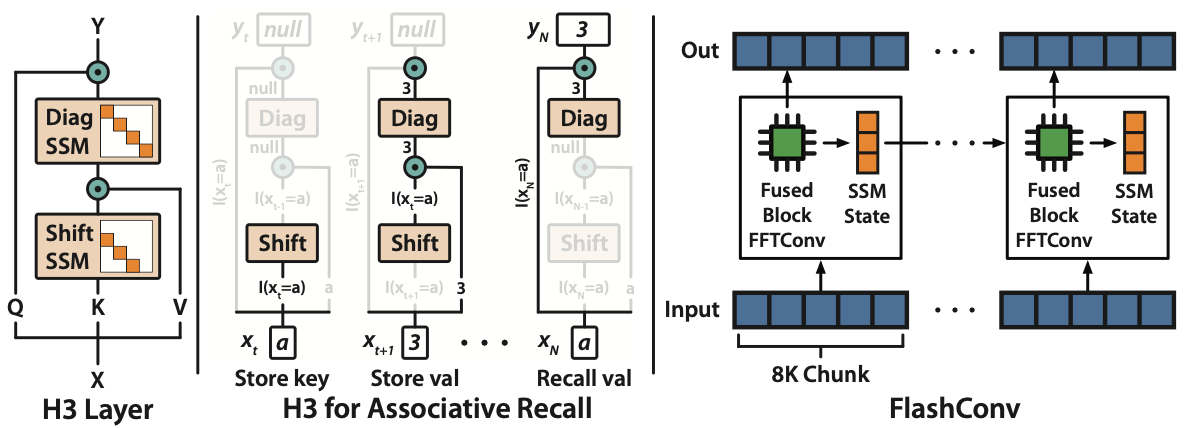
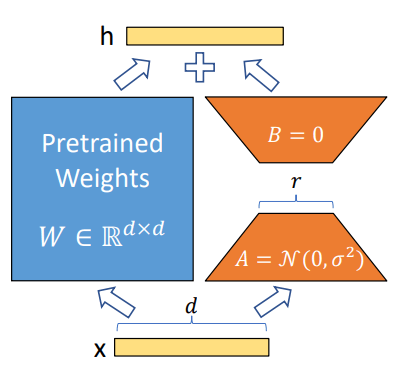
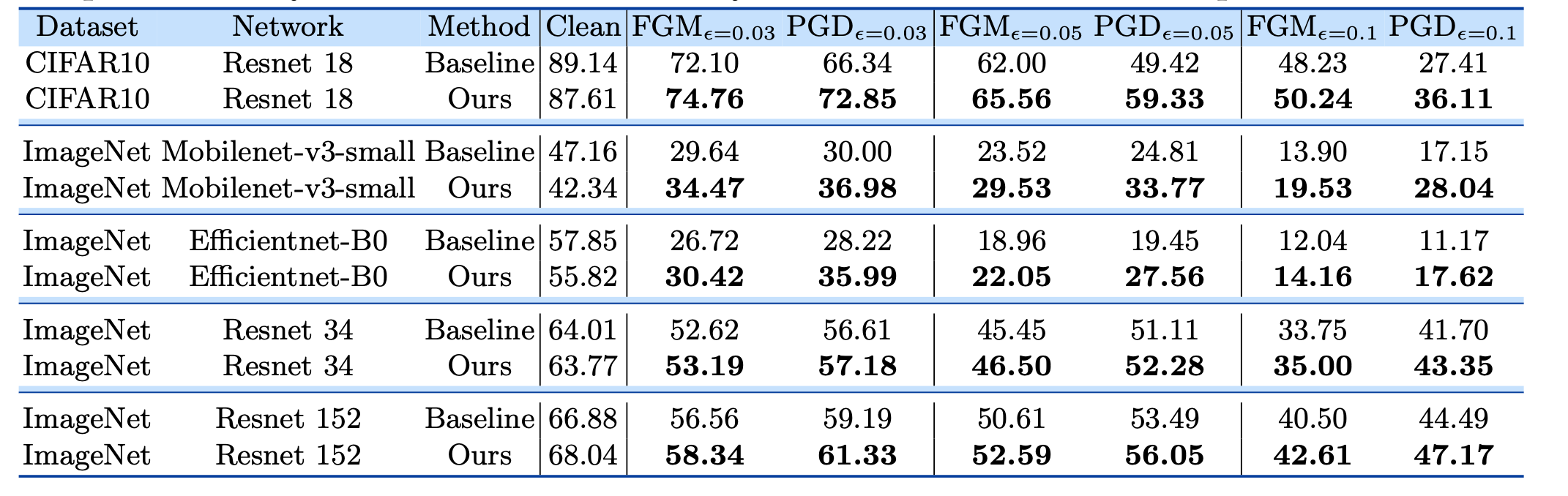
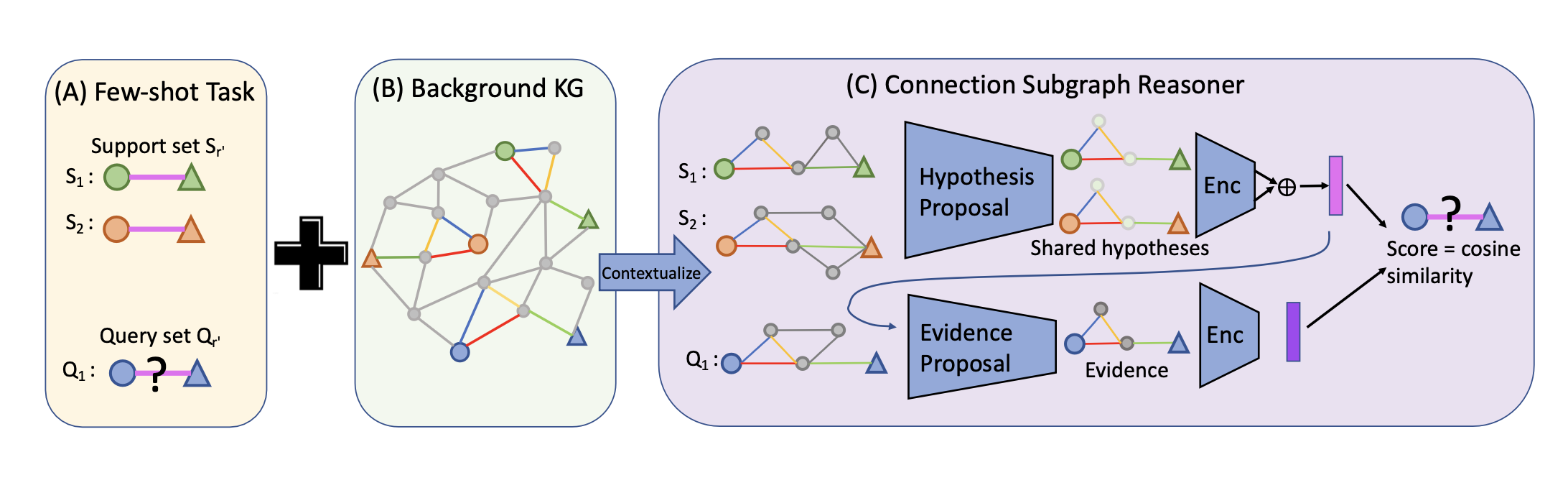
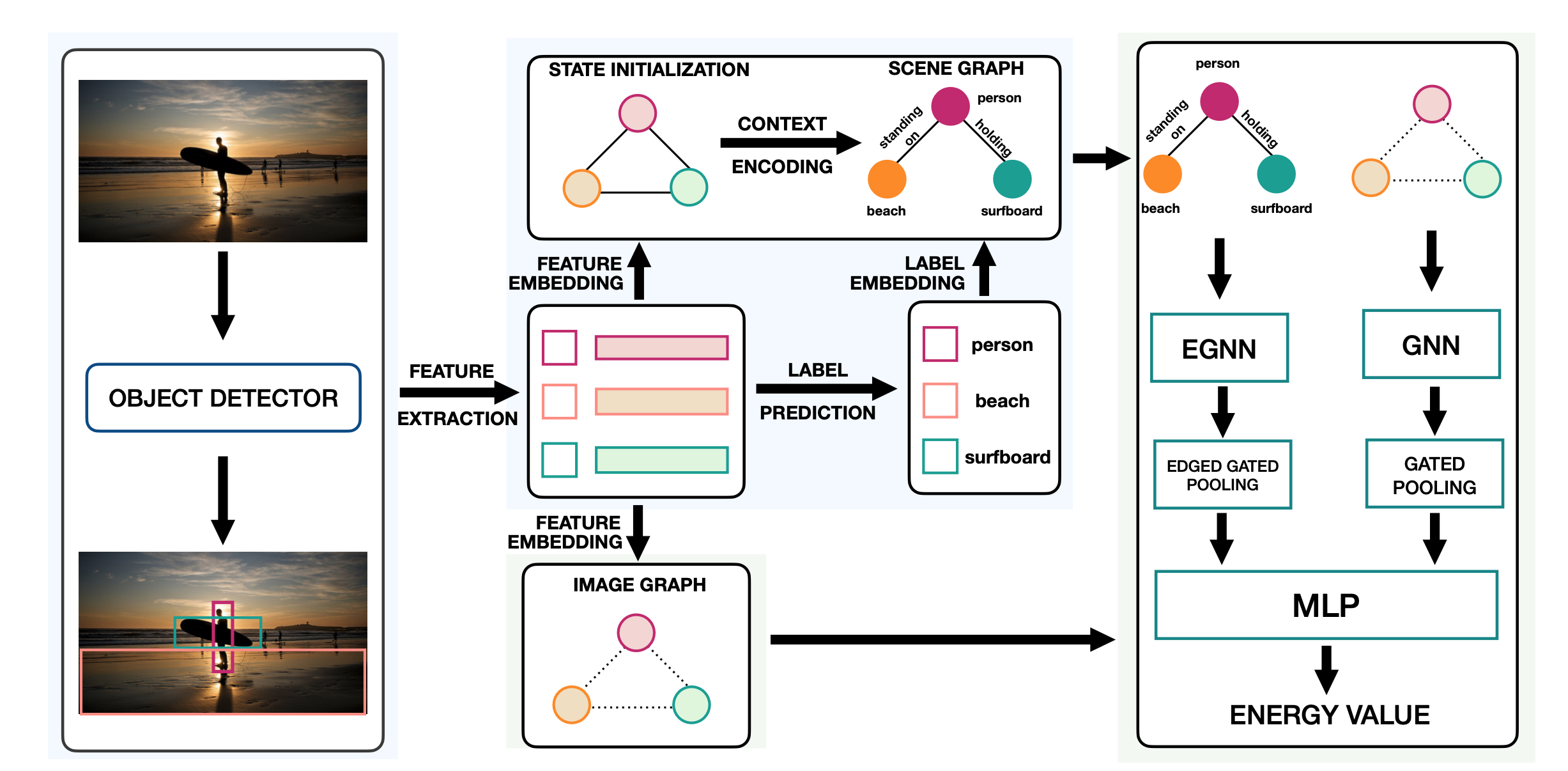
【NeRF】動画から点群・メッシュ・任意視点動画を生成してみる
· ☕ 4 min read
NeRFを使えば,点群・メッシュ・任意視点動画が作れるのでやってみた 今回は愛飲するRedBullを被写体にしてみるヨ! 任意視点動画 (GIF版) 任意視点動画 (動画版) Your browser does not support the video tag. 点群 NeRFとnerfstudioについて簡潔に説明 ボリュームレンダリング ある点 $x$と方向 $d$を入力として $(c,\sigma)$を出力 ...