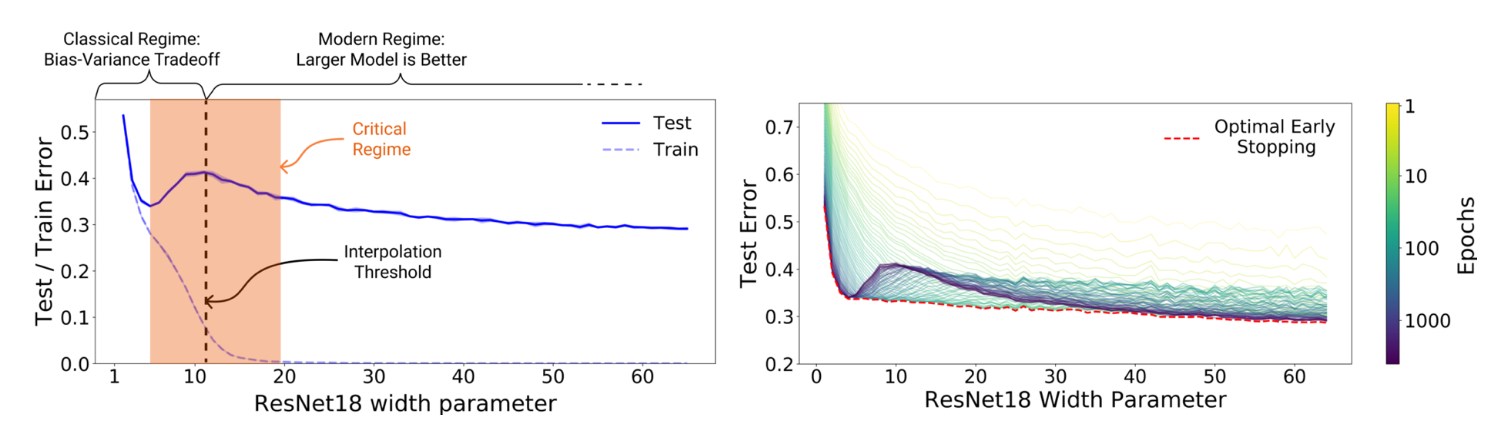
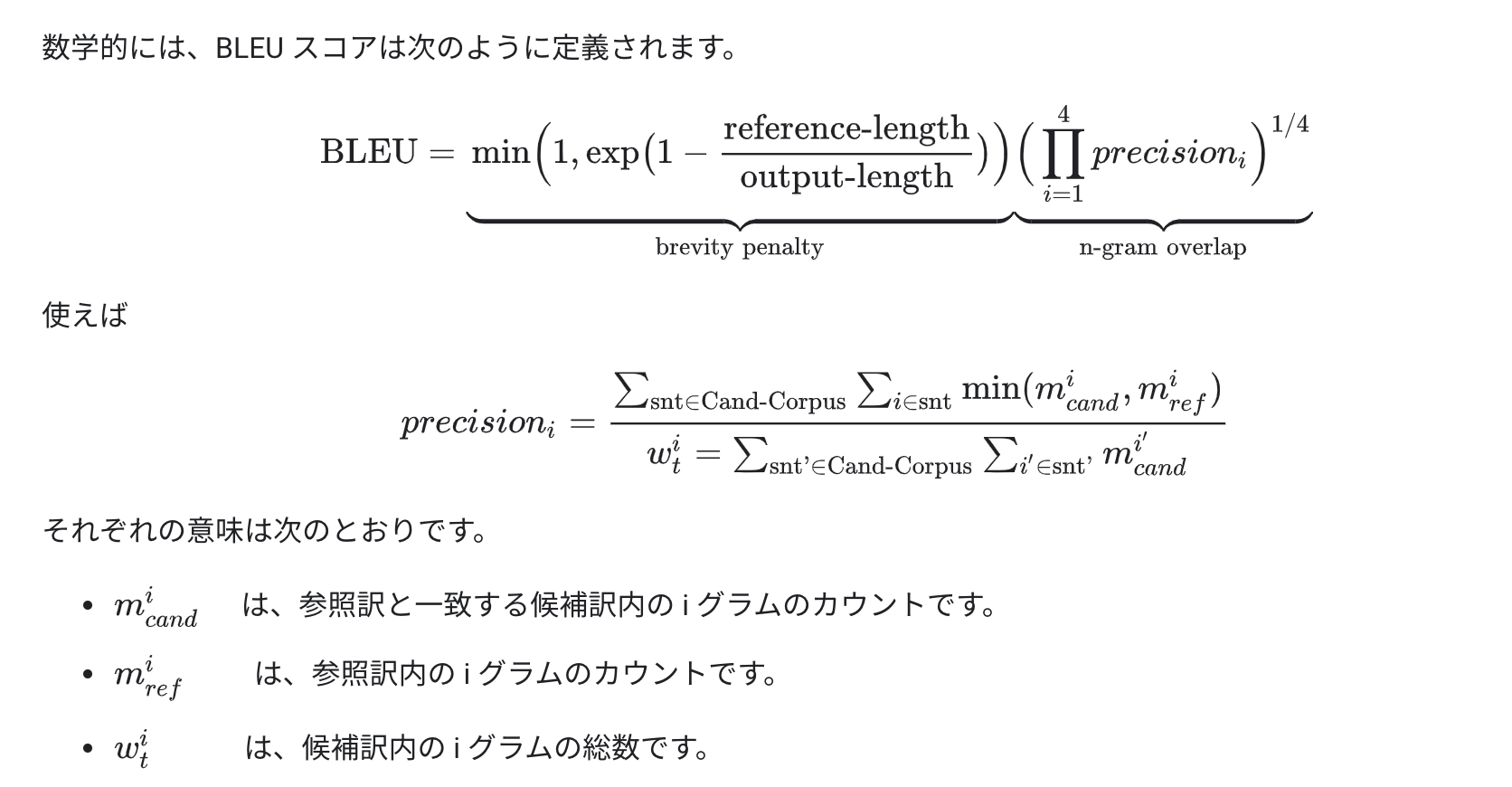
【論文メモ】Double Descent 📅 2022/4/15 · ☕ 1 min read U字からlossが落ちていく減少 例えばシンプルな構造のニューラルネットワークと複雑なニューラルネットワークがあったとします。前者については従来から言われているように"under-fitting"と"over-fitting"からなるU字型の特性が観測できますが、後者は複雑にしてい ... #論文
【論文メモ】Deformable Conv 📅 2022/4/14 · ☕ 1 min read [**** https://gyazo.com/e4c2ed2a441c686afa02f2e0625b373f ] https://arxiv.org/abs/1703.06211 ... #論文
【論文メモ】Fine-tuning CNN Image Retrieval with No Human Annotation 📅 2022/4/11 · ☕ 1 min read todo https://arxiv.org/abs/1711.02512 ... #論文
【論文メモ】CvT 📅 2022/4/11 · ☕ 1 min read Convは高いロバスト性を持つ 例えば画像のシフトに強かったり ⇒ ViTにConvを導入 Conv自体はパッチ分割 & 線形変換と同じ CvTはパッチ同士が重なり合う Positional Encodingは行わない Convが同じことをやってるらしい … ? How Much Position Information Do Convolutional Neural Networks Encode? ... #論文
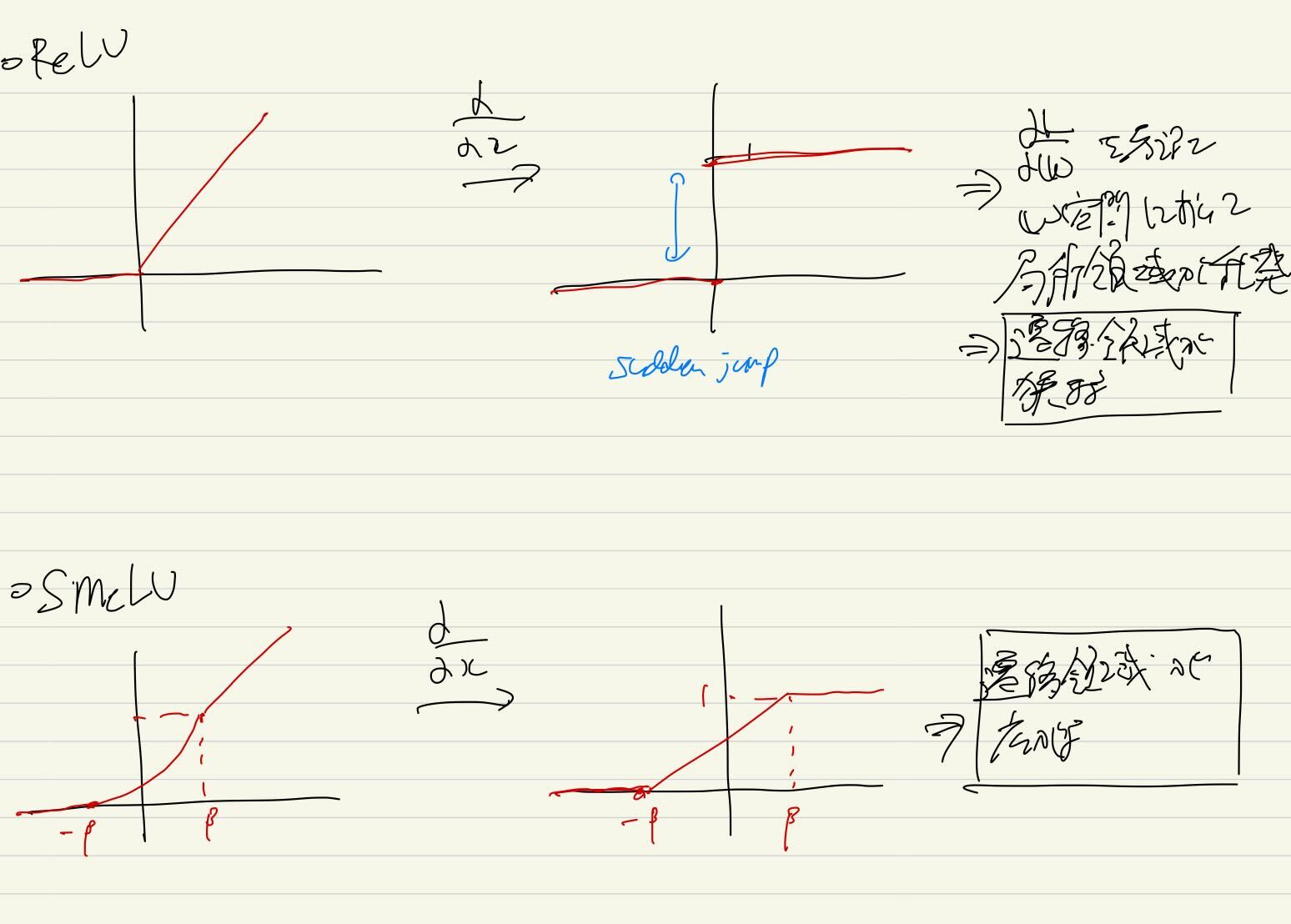
【論文メモ】SmeLU 📅 2022/4/7 · ☕ 1 min read ReLUの原点での急な変化を, 2次関数で補完することでスムーズにした活性化関数 SmeLU (Smooth ReLU)を提案 リコメンデーションシステムにおいては, 再現性の低さは致命的となる ReLU は勾配がジャンプするので(sudden jump), 損失平面に局所領域ができてしまう そのため, 遷移領域が狭まる 遷移領域が狭まってしまうと局所的な遷移しかしないので, モデ ... #論文
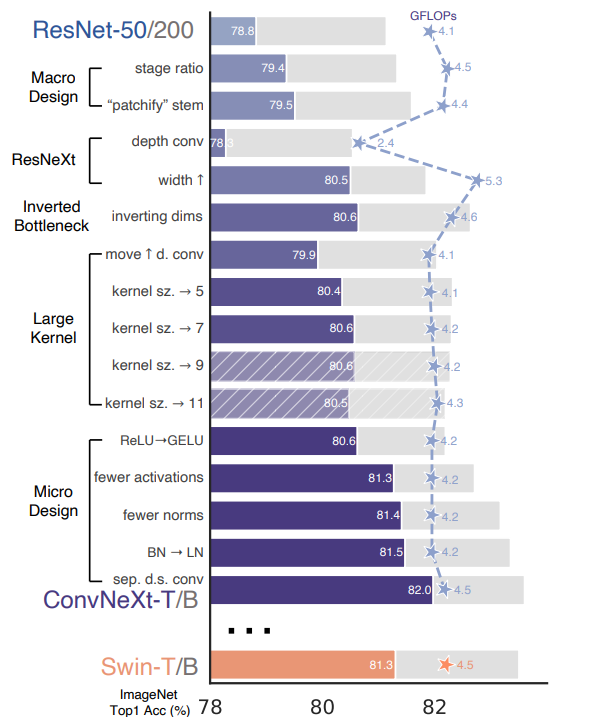
【論文メモ】ConvNext 📅 2022/3/30 · ☕ 1 min read ResNetを現代風に DepthWiseにしたり (PointWise・Depthwise) カーネルサイズ変えたり bottleneck内のレイヤーの順番を変えたり BNからLNにしたり 地味に実装でtimmつかてますねん https://github.com/facebookresearch/ConvNeXt/blob/d1fa8f6fef0a165b27399986cc2bdacc92777e40/models/convnext.py ... #論文
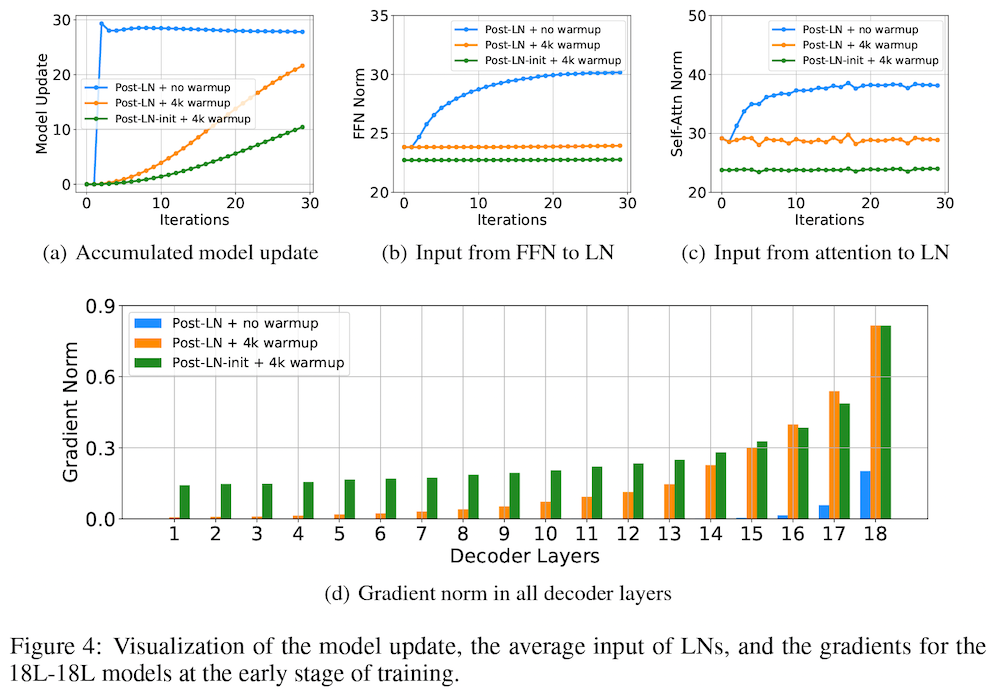
【論文メモ】DeepNet 📅 2022/3/30 · ☕ 2 min read モデル更新量を見る モデル更新後, 出力がどの程度変化したか 具体的には、まず、18レイヤーの通常の Post-LN トランスフォーマーを訓練させた場合、訓練が不安定であり、検証セットの損失関数の値(ロス)が収束しないことを示しています。このとき、「モデル更新量 (model update)」、すなわち、初期化時に比べて、モデルの更新後に、出力の値がどの ... #論文
【論文メモ】Attention Bottlenecks for Multimodal Fusion 📅 2022/3/30 · ☕ 1 min read https://arxiv.org/abs/2107.00135 ... #論文
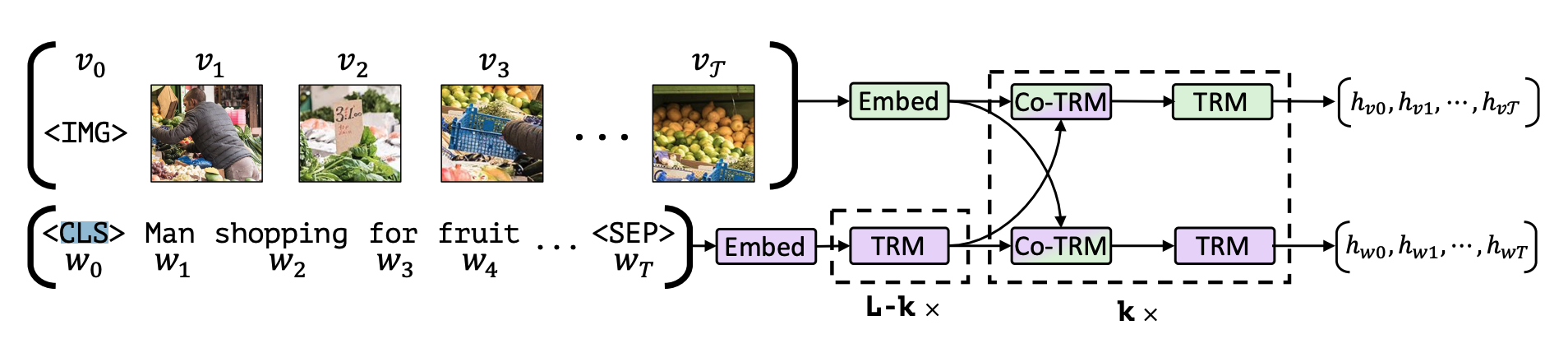
【論文メモ】ViLBERT 📅 2022/3/30 · ☕ 1 min read BERT同様, 転移学習モデル なので, IMGトークンやCLSトークンを導入する 画像の埋め込みはどういう実装…? 例えばViTだと, 普通に行列 $E$を掛け合わせている or ResNetを用いる (これをハイブリット方式と呼ぶ) 各パッチをEで埋め込み、CLSトークンを連結したのち、位置エンコーディングEposを加算して ... #BERT #論文
【論文メモ】gMLP 📅 2022/3/30 · ☕ 1 min read https://ai-scholar.tech/articles/transformer/mlp_transformer ... #論文
Sequence to sequence learning with neural networks(2014) 📅 2022/2/19 · ☕ 2 min read #Computer #機械学習 [*** — 概要 — ] [** どんなもの?] 多層LSTMでML task(Machine-Translation-Task)を解く. LSTMを2回通す(encoder/decoder)ことで, T次元ベクトル→固定長の意味ベクトル→T ’ 次元ベクトル と変換することができる. (入力時に語順を逆さにする) [** どういう系譜?先行研究との ... #論文 #post