【論文メモ】MuKEA: Multimodal Knowledge Extraction and Accumulation for Knowledge-based Visual Question Answering
· ☕ 1 min read
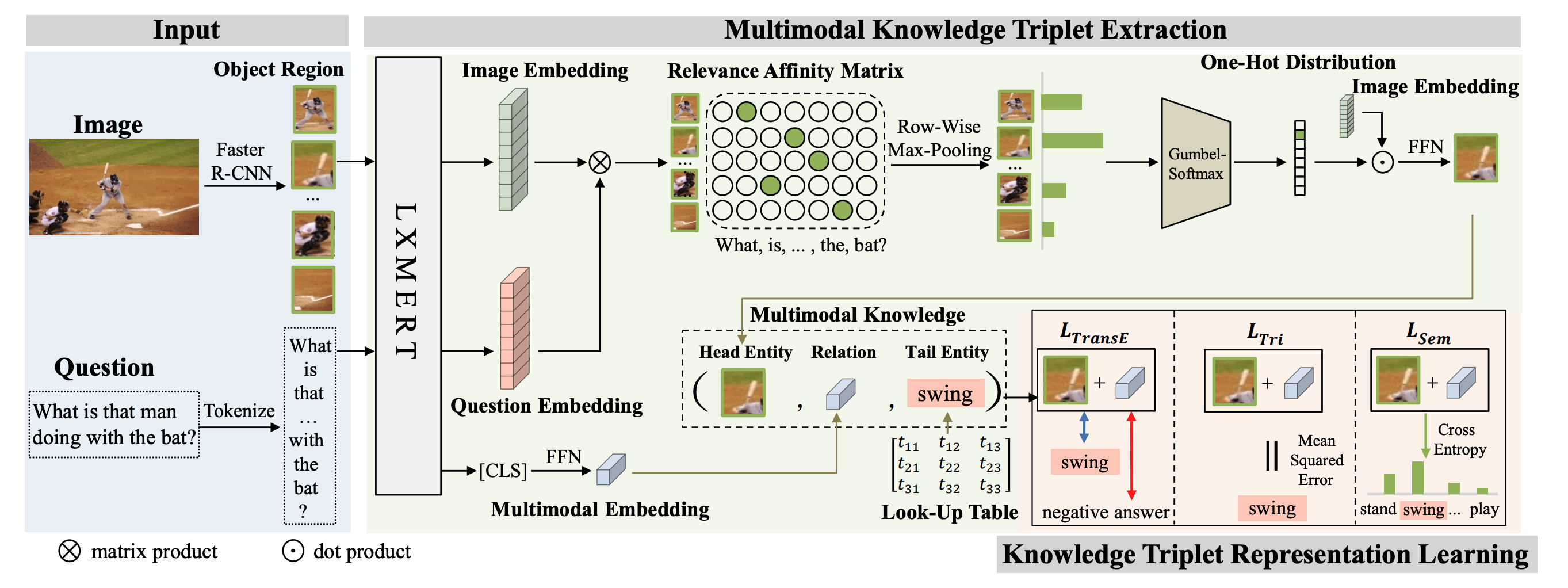
CVPR22 タスク: KB-VQA 質問画像に含まれていない知識を要する質問に回答するタスク 例えば, 以下のVQAでは, 外部知識=kawasakiを使わないと回答できない 新規性 知識グラフの構築は行わない scene graphを作るのではなく, 画像由来のHead Entity (領域画像)と, 言語由来のTail Entity (後述)について, (entity, relation, entity)のtripletを用い ...