ar5ivのコードを読む 📅 2022/7/7 · ☕ 1 min read https://github.com/dginev/ar5iv 前提: arxivは投稿時, texをアップロードしなければならない ar5iv: 裏でクローラを回して, latexmlをキャッシュしてるだけっぽい 最終的にHTMLに変換されたものをzipで固めてサーバ上で管理 レンダリング時はzipを展開して独自のCSSで書き換えたものを表示 Rust製 ... #misc #論文 #Rust #post
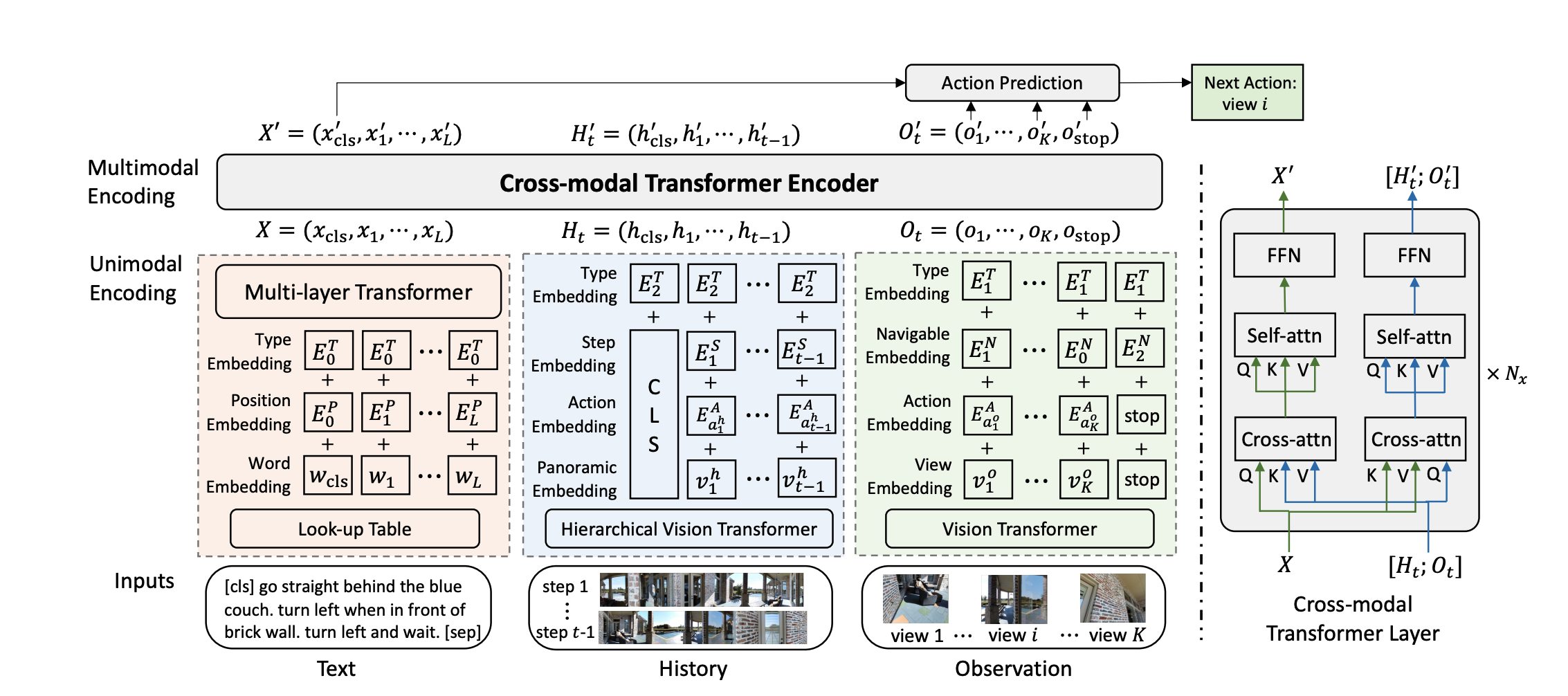
【論文メモ】Think Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language Navigation 📅 2022/7/7 · ☕ 1 min read VLN-DUET 概要 localな情報とグラフを用いたglobalな情報の両方を統合してactionを決定する actionが決定されたら, Graphを動的に構築して, 移動先までの最短経路をワーシャルフロイドで探索 各ノードには, viewから得られた特徴量を埋め込み表現として保持する 行動 $a^\pi$は各ノードへの尤度によって表現され, ノ ... #論文 #Vision-and-Language
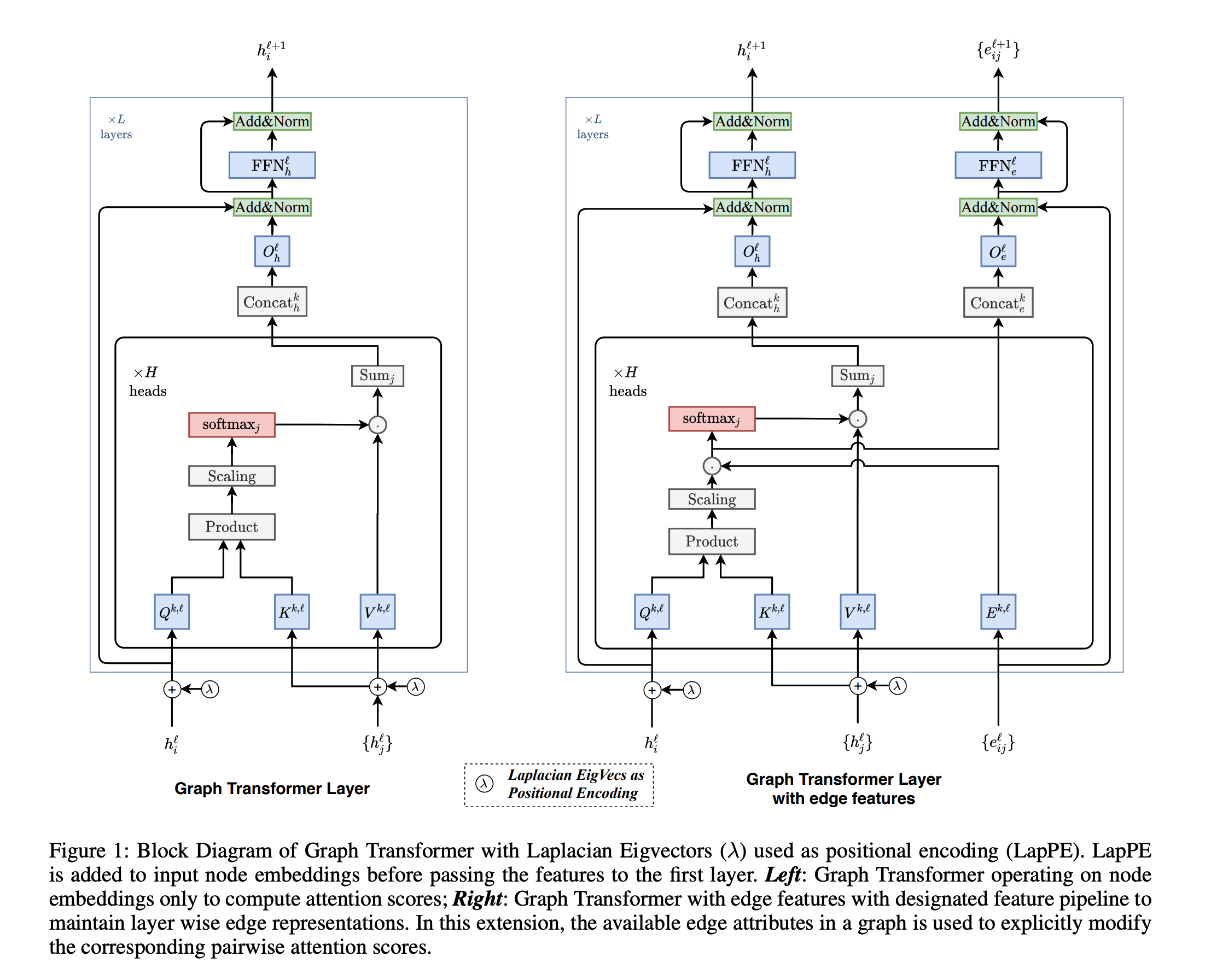
【論文メモ】Graph Transformer: A Generalization of Transformer Networks to Graphs 📅 2022/7/7 · ☕ 1 min read 任意のGraphに適応可能な, 汎用Transformer Positional Encodingがラプラシアン行列の固有値で表現される ラプラシアン行列の固有値 $\lambda$は頻度・周波数的な側面を持つ → グラフ上のフーリエ変換・畳み込みでは $\lambda$が使われる (いつかまとめる→todo) todo https://arxiv.org/pdf/2012.09699v2.pdf ... #論文
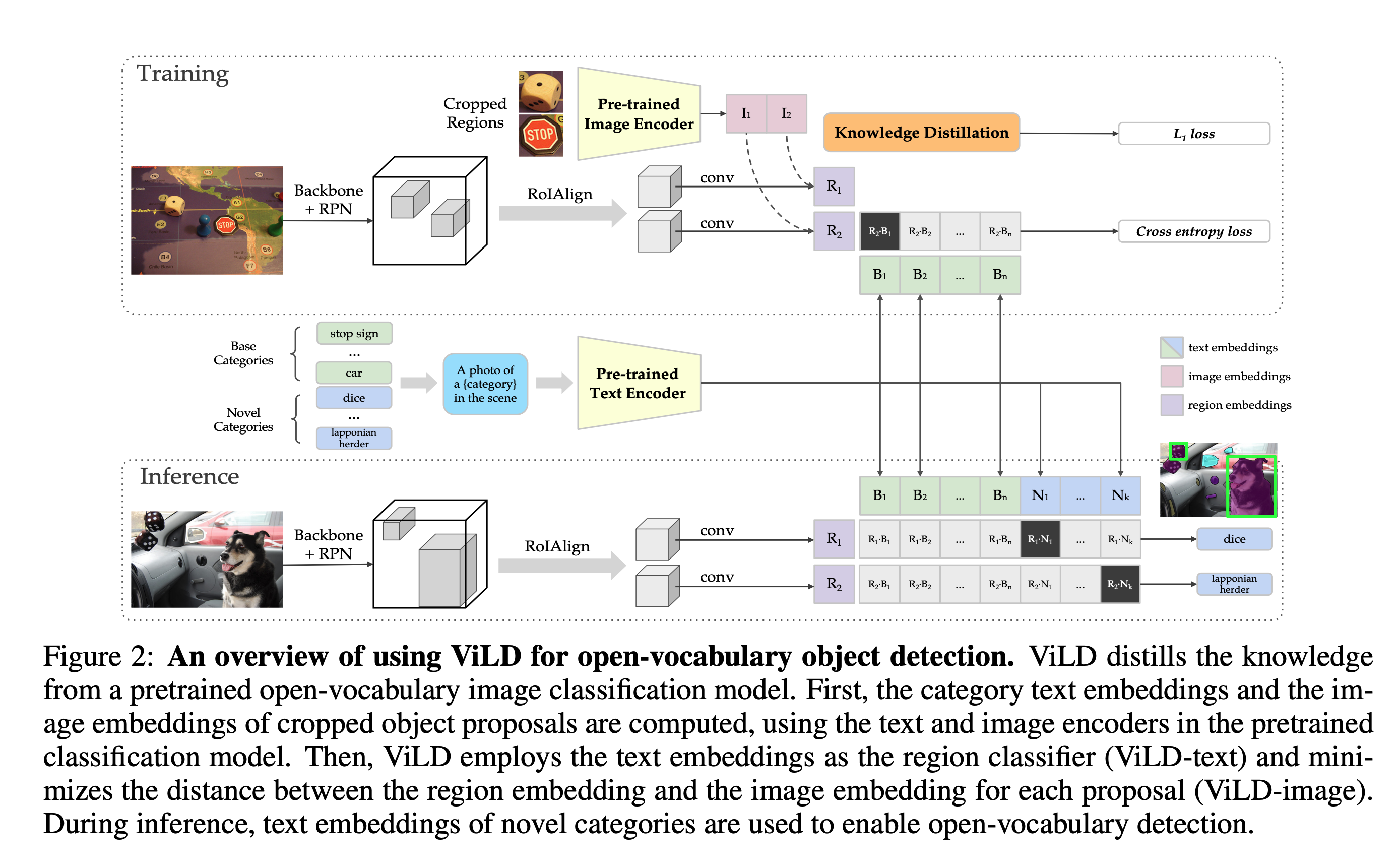
【論文メモ】ViLD: Open-vocabulary Object Detection via Vision and Language Knowledge Distillation 📅 2022/7/7 · ☕ 1 min read Open-Vocabulary (任意テキスト入力)な物体検出モデル classifierがCLIP特徴量になっている ... #論文
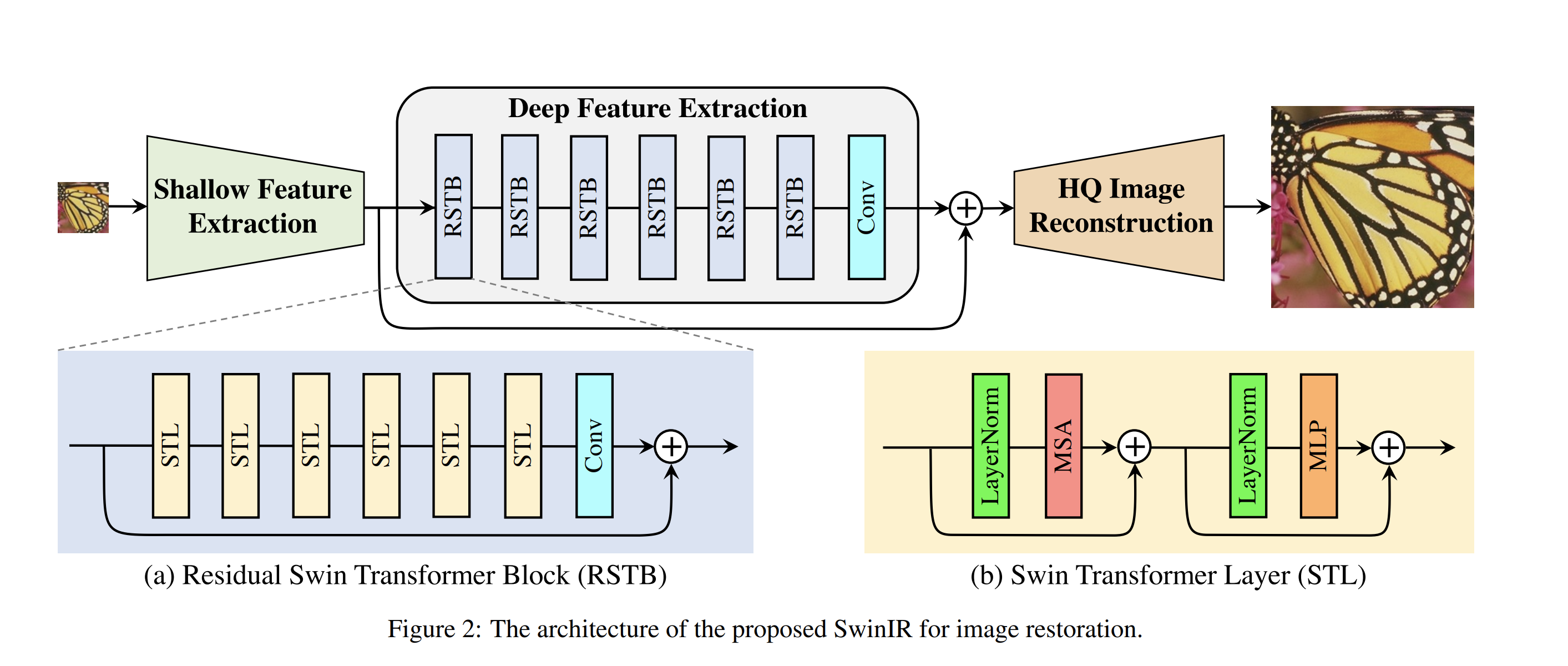
【論文メモ】SwinIR: Image Restoration Using Swin Transformer 📅 2022/7/7 · ☕ 1 min read 残差接続が大量にあるの面白い 多分だけど, 真っ黒から真っ黒への変換みたいな無意味な変換によって重みの学習を引っ張られたくないので, クソデカ残差を入れているのだと思う (オキモチ) SwinTransformerのおかげでパラメタ数はかなり減っている ... #論文
Impact Factor 📅 2022/7/6 · ☕ 1 min read 学術雑誌の影響力を測る指標らしい (そんなのあるんだ) 今年の被引用数を過去2年分のPublicationで割る $\displaystyle {\text{IF}}_{y}={\frac {{\text{Citations}}_{y}}{{\text{Publications}}_{y-1}+{\text{Publications}}_{y-2}}}.$ ... #論文 #post
【論文メモ】Do Transformer Modifications Transfer Across Implementations and Applications? 📅 2022/6/27 · ☕ 1 min read Transformerの改善案は大量にあるが, 本当に有効なのはどれだけあるの?という論文 結論 (有効な改善方法) 活性化関数: GLU+GeLU/Swish 正規化: RMS Norm パラメタ共有: デコーダの入出力における埋め込み表現を共有すると良い アーキテクチャ Mixture of Experts Transformer Synthesizer Product Key Memory ... #論文
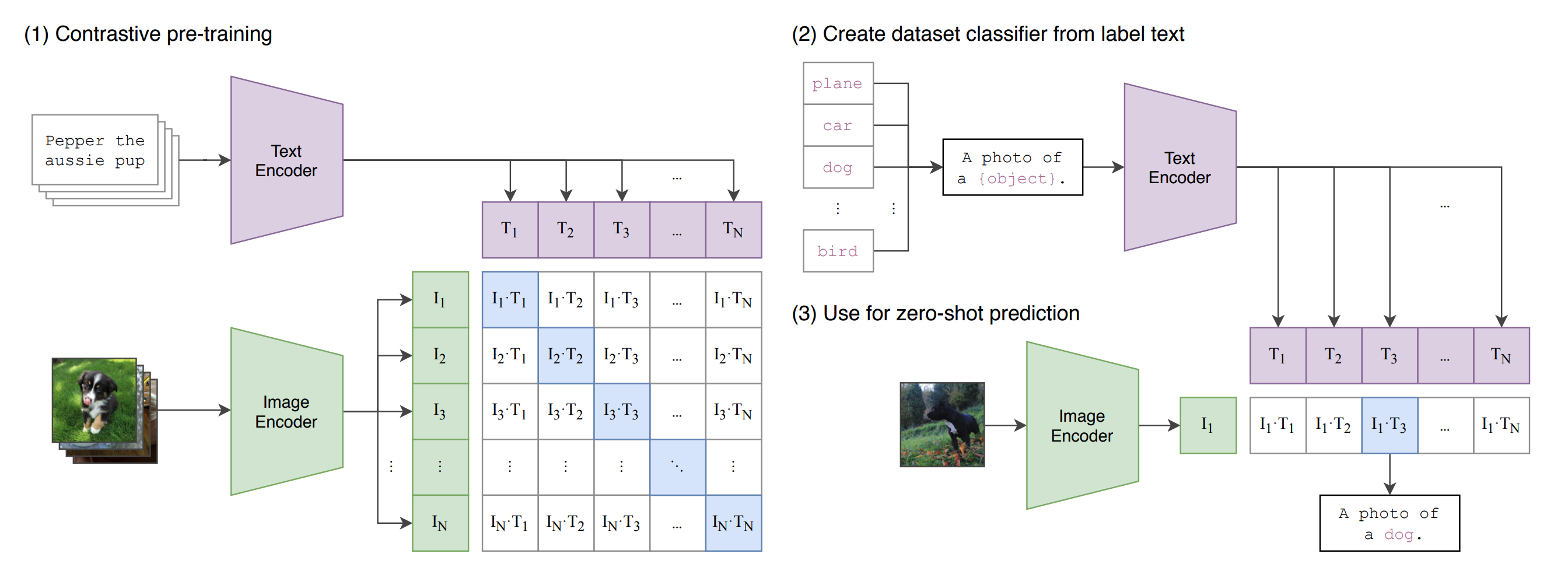
【論文メモ】CLIP 📅 2022/6/27 · ☕ 1 min read CLIPによって, image↔textの特徴量変換が容易になったと言える → ViLD: Open-vocabulary Object Detection via Vision and Language Knowledge Distillation ... #論文 #機械学習
【論文メモ】HAMT - History Aware Multimodal Transformer for Vision-and-Language Navigation 📅 2022/6/26 · ☕ 1 min read パラメタの更新にActor-Criticを使用 強化学習と模倣学習の両方を組み込んでいる ... #論文
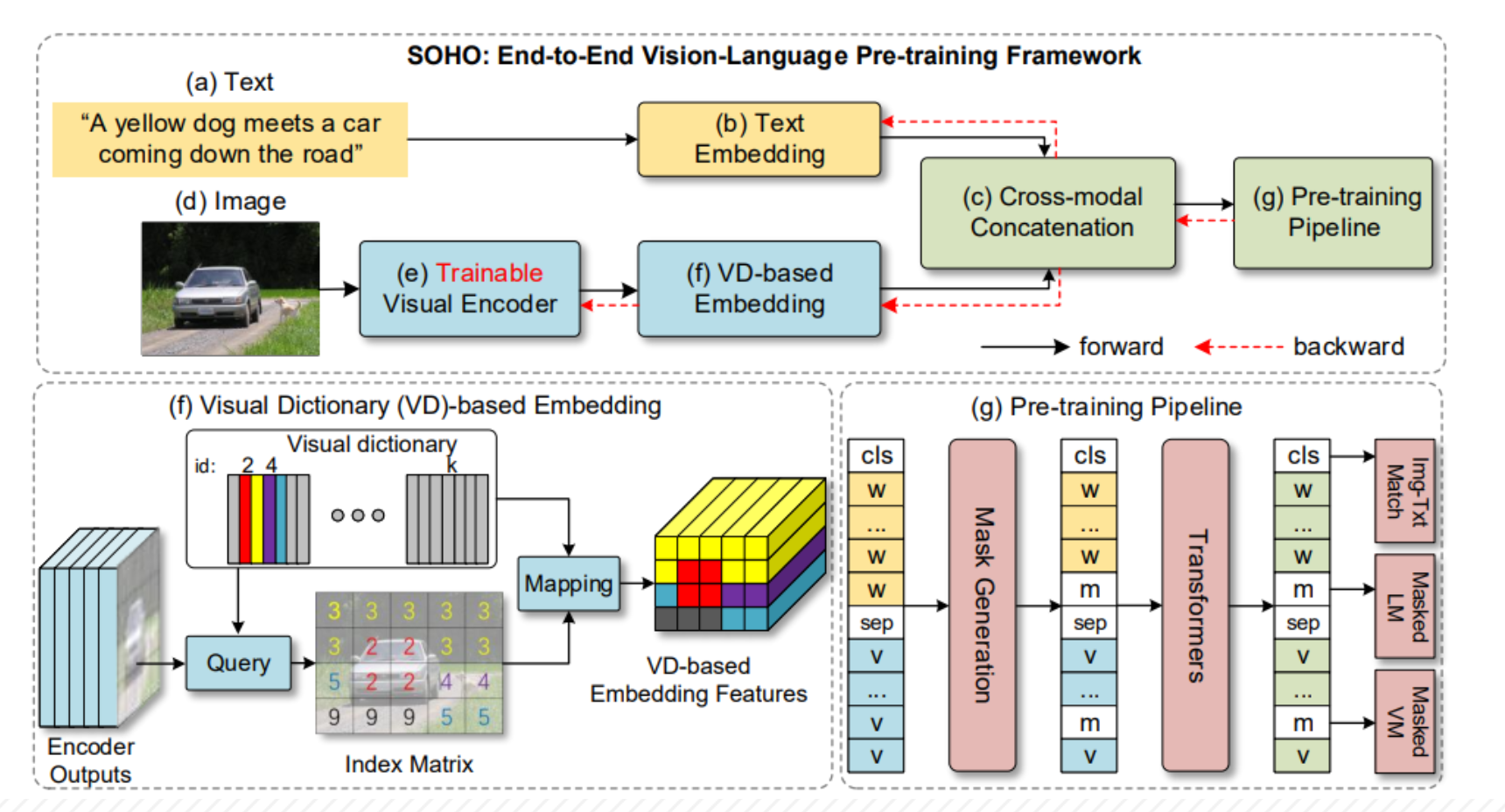
【論文メモ】SOHO - Seeing Out of tHe bOx : End-to-End Pre-training for Vision-Language Representation Learning 📅 2022/6/26 · ☕ 1 min read クラスタリングの上位互換みたいなことをする パッチを特徴空間に飛ばす パッチに映る物体が同じ種類の物体なら, その特徴が同じクラスタidに含まれるように学習 ... #論文
【論文メモ】REVERIE - Remote Embodied Visual Referring Expression in Real Indoor Environments 📅 2022/6/26 · ☕ 0 min read ... #論文 #multi-modal #Vision-and-Language