- 提案手法は主に2つの機構で構成される
-
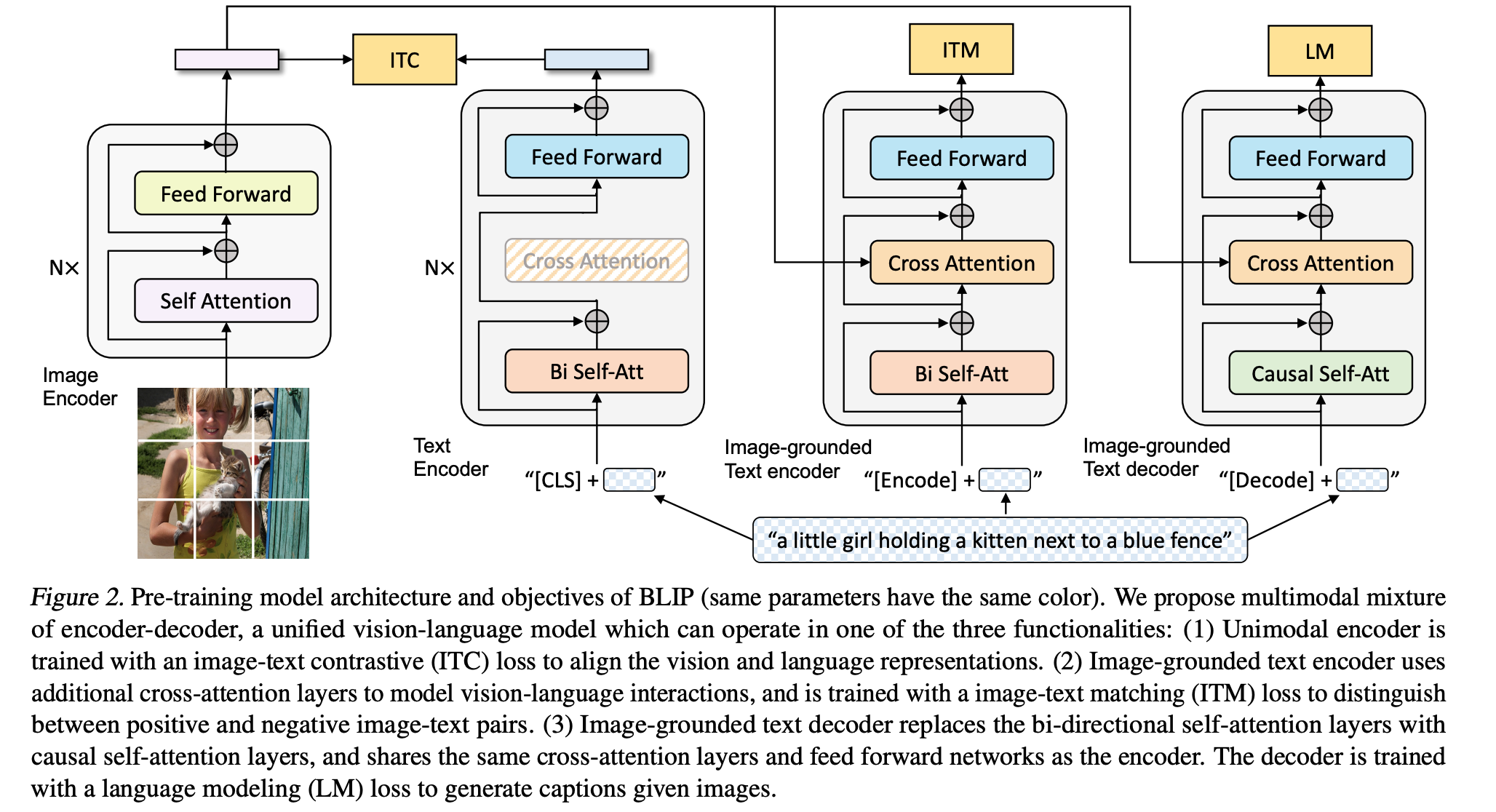
- Multimodal mixture of Encoder-Decoder (MED)
-
-
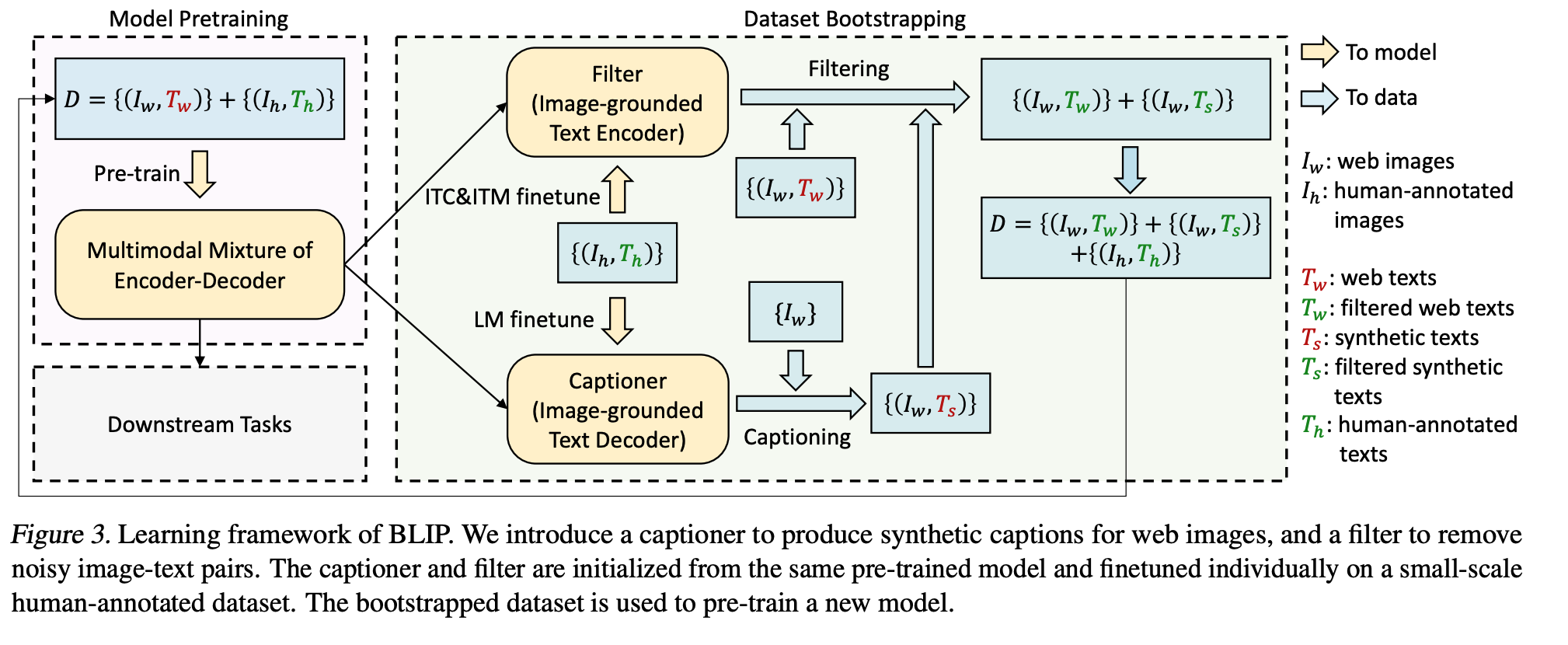
- Captioning and Filtering (CapFilt):

- Captioning and Filtering (CapFilt):
-
CLIPの使用するデータセットはnoisy
- なので, キャプションの取捨選択を自動で行う機構を導入
- 流れ
-
- ノイズを含む元のデータセットでMEDを学習
-
- 事前学習されたMEDを用いてCapFiltを実行
-
- CapFiitによって得られたデータセットを用いて再度MEDを学習
-
MED
- Image-TextContrastiveLoss(ITC)
- 画像特徴量と言語特徴量が近づくように学習
- Image-TextMatchingLoss(ITM)
- 画像とテキスト本当にペアであるかを二値分類
- LanguageModelingLoss(LM)
- 入力画像に対する真のキャプションと, 生成されたキャプションとのクロスエントロピー
- Image-TextContrastiveLoss(ITC)
-
CapFilt
- 上に太文字書いたITMを使って画像とテキストが本当にペアであるかを二値分類
- ペアでないと判定されたものはデータセットから排除することでデータセットをクリーニング