はじめに
-
Transformerをベースとしたグラフ学習手法 (NeurIPS 2021)
-
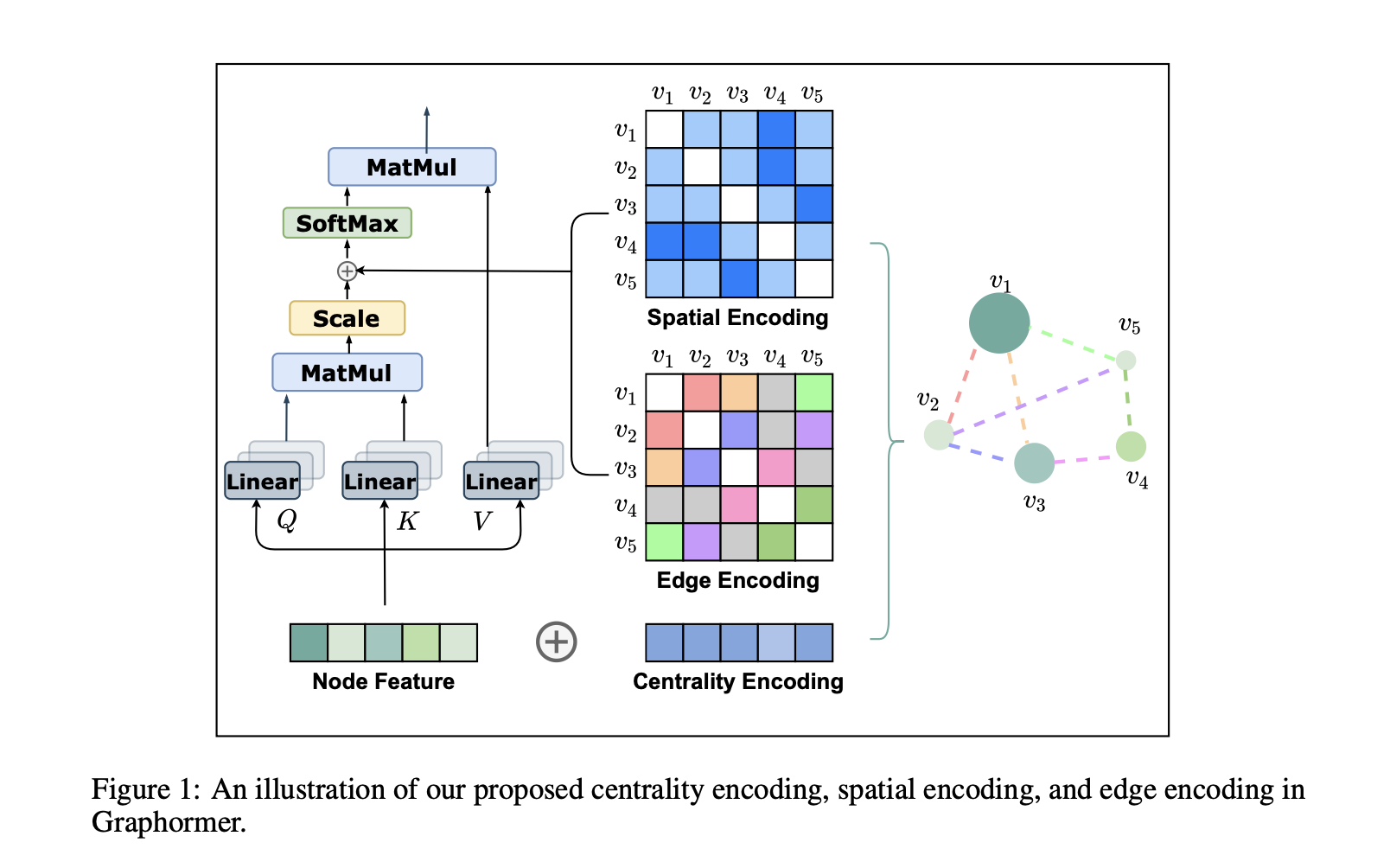
構成要素は三つ
- Centrality Encoding
- Spatial Encoding
- Edge Encoding (in the Attention)
-
特筆すべき点として, この手法はGINやGCN, それからGraphSAGEといったGNN手法を一般化したものとなっているらしい
Do Transformers Really Perform Bad for Graph Representation?
論文メモ
- 構成要素1. Centrality Encoding
- モチベーション
- Node Centrality, つまりノードがどれほど別のノードとつながっているかはノードが如何に重要かを示しており, とても有益となり得るので, Encodeしたい
- 例えばTwitterにおいて, 有名人はフォローが少なくてフォロワーが多い→ノードの次数は直感的にも重要
- どうするの?
- ノードの埋め込み表現 $h^{(0)}_i$について
$$h ^{(0)}_i = x_i + z ^−_{deg^-_{(v_i)}} + z^+_{deg^+_{(v_i)}}$$ - ただし, 入次数と出次数をそれぞれ, $deg^-, deg^+$とする
- 最初だけ( $h^{(0)}_i$)なので計算コストもそれほどかからない
- $z^-, z^+ \in \mathbb{R}^d$は学習可能パラメタとなっていて, Centralityの埋め込みを行う
- ただし無向グラフなら, $deg^-, deg^+$を一つのパラメタ $deg$としても良い
- ノードの埋め込み表現 $h^{(0)}_i$について
- モチベーション
- 構成要素2. Spatial Encoding
- モチベーション
- Transformerの強さは受容野の広さだが, 一方でPositional Encodingが必要
- どうにかGlobal-Attentionのまま位置情報を保存する形の写像がほしい
- → GNNは隣接ノードしか見ない(AGGREGATE)なので, GNNよりも広い受容野を獲得できる
- どうするの?
- ノード間の関係を $\phi(v_i,v_j)$と記述し, QueryとKeyの内積=Attentionを以下のように変更
$$A_{ij} = \frac{(h_iW_Q)(h_jW_K)^\top}{\sqrt{d}} + b_\phi(v_i,v_j)$$ - Attention自体を修正している点に注意
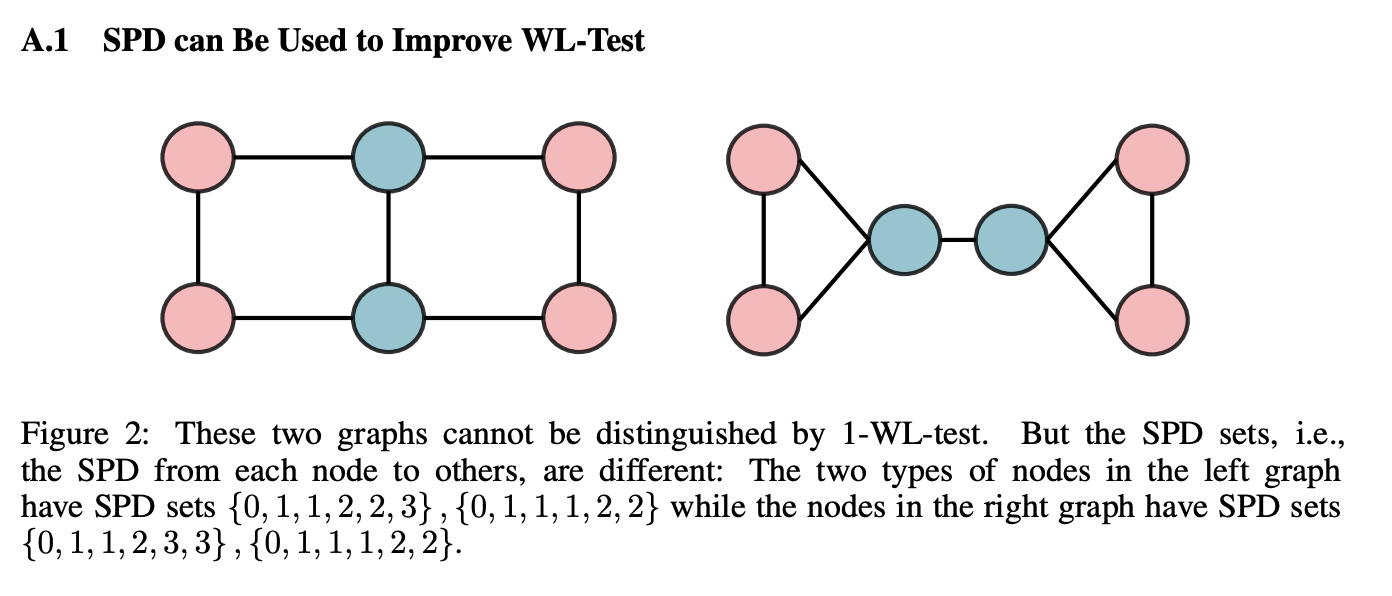
- 本論文では $\phi(v_i,v_j)$を最短経路距離(SPD)とする
- $b_\phi(v_i,v_j)$は学習可能パラメタ (スカラ)
- これにより, Attentionを $\phi(\cdot)$で調整できる
- 例えば $\phi(\cdot)$に対して $b_\phi$が単調減少ならば, より周囲にAttentionを掛ける=隣接周囲を注視するようになる
- ノード間の関係を $\phi(v_i,v_j)$と記述し, QueryとKeyの内積=Attentionを以下のように変更
- モチベーション
-
構成要素3. Edge Encoding
- モチベーション
- エッジの情報はもちろん重要. たとえば分子の解析などではエッジに結合情報が存在する
- なので, エッジ $e \in \mathcal{E}$の特徴量 $x_e$も埋め込みたい
- どうするの?
- モチベーション
-
その他
-
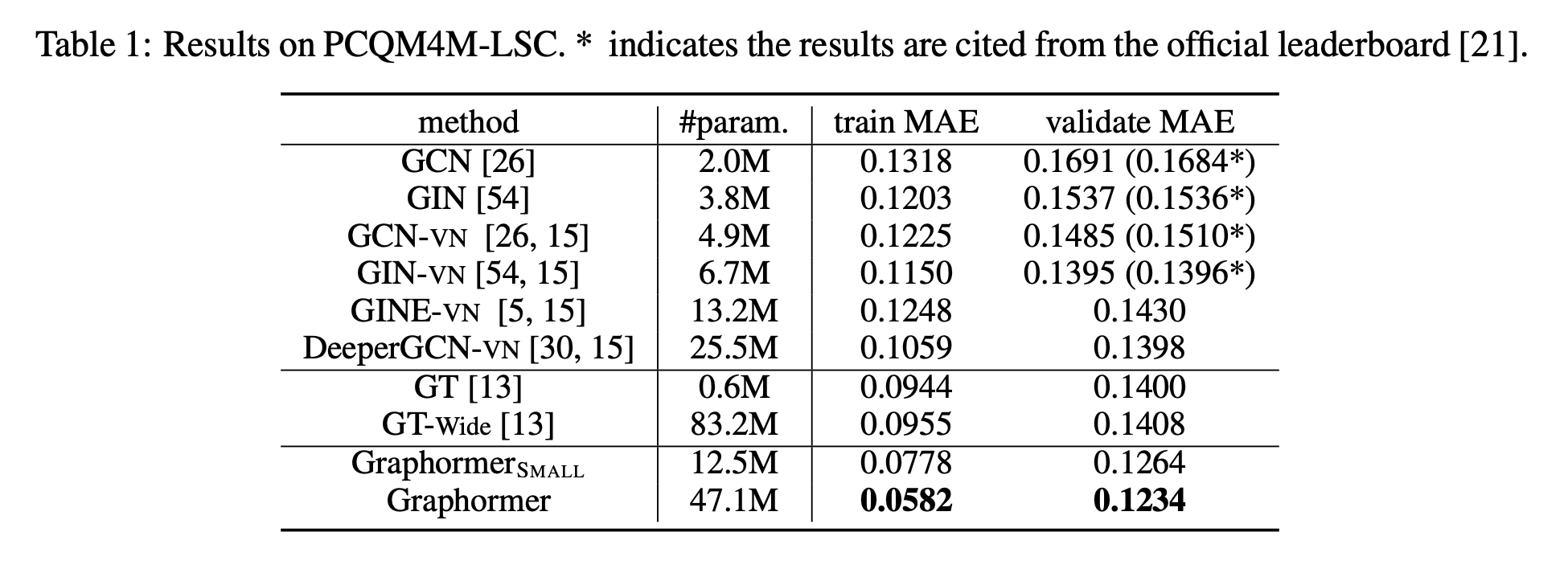
結果
- TokenGT (TokenGT: Pure Transformers are Powerful Graph Learners)と同じデータセットぽい?
- 確かに表現力は上がってそう
-
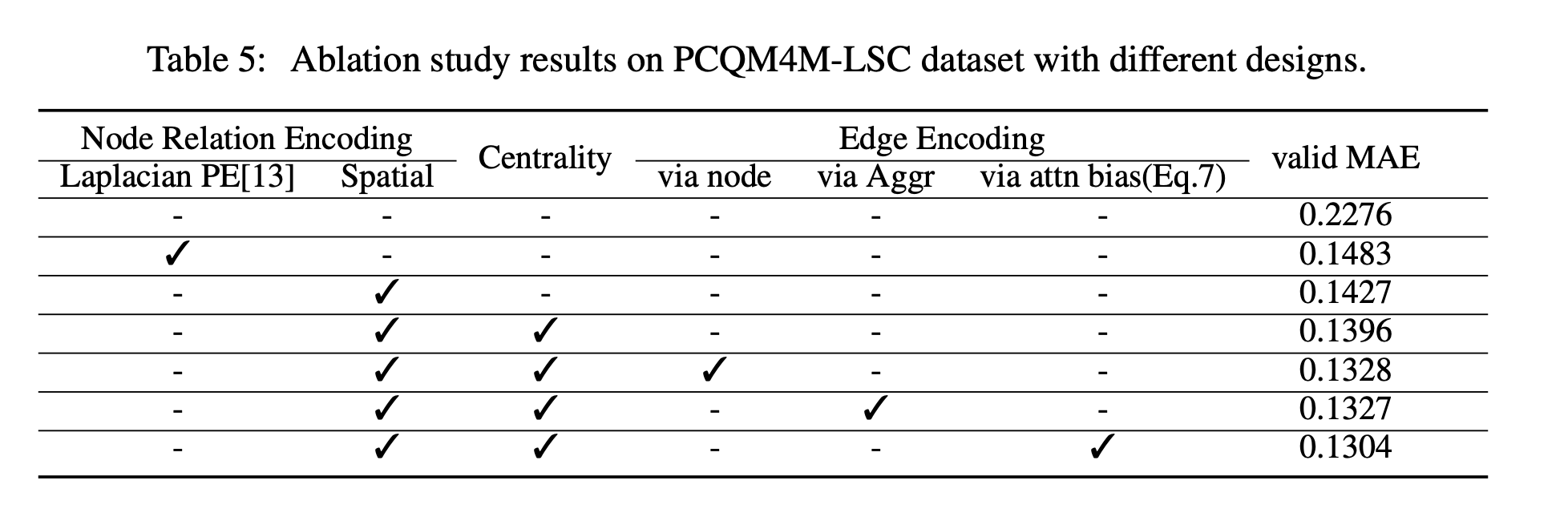
Ablation
Supplementary Material: https://openreview.net/attachment?id=OeWooOxFwDa&name=supplementary_material