本記事ではなく動画の視聴の方を推奨します.
概要
- ICLR23
- 状態空間モデル(state-space model; SSM)は様々なモダリティにおいて有用性が検証されてきたが,未だ言語系においては確認できていない.
- また,SSMは $\mathcal{O}(L)$であるにも拘らず, $\mathcal{O}(L^2)$であるTransformerよりも遅い
- 実験によって,SSMが①前方にあるトークンの記憶と②トークン間の比較が苦手なことを発見し,この二つの難点を乗り越える新たなSSMとしてH3 (Hungry Hungry Hippos)を提案する.
- Transformerに替わるモデルとも言われている(要出典)
SSMにおける二つの問題点
- 問題点①②を検証するために,二つのタスクInduction HeadとAssociative Recallを実施
- Induction Head : 特殊なトークン
|-で囲まれた部分文字列の先頭の文字を出力させるタスク- 前方のトークンを如何に覚えているかを測ることができる
- Associative Recall : key-valueでセットになってるアルファベットと数字の組に対して,与えられたkeyに対応するvalueを出力させるタスク
- この場合
a 2 c 4 b 3 d 1に対して入力がaなので2が答え (間違ってたら教えてくれ) - トークン間の関係を覚えているかどうかを測ることができる
- この場合
- Induction Head : 特殊なトークン

- 結果は以下の通り
- Attentionは100%成功しているが,従来手法はほとんどできていない
- 提案手法であるH3はほぼ100%成功
- Attentionは $QK^\top$によりトークン間の関係を記憶可能であり(②), $\mathrm{softmax}(QK^\top)V$によりトークン自体を直接記憶可能(①)

先行研究について
- 具体的な手法に入る前にH3の系譜について述べる必要がある.
- H3は以下のような経緯で提案された
- HiPPO論文→LSSL→S4→H3
- 次章より,まずはHiPPOについて,それからLSSL / S4について軽く紹介する.
HiPPO (higher-order polynomial projection operators)
-
HiPPO: Recurrent Memory with Optimal Polynomial Projections (Gu+., NeurIPS20)
-
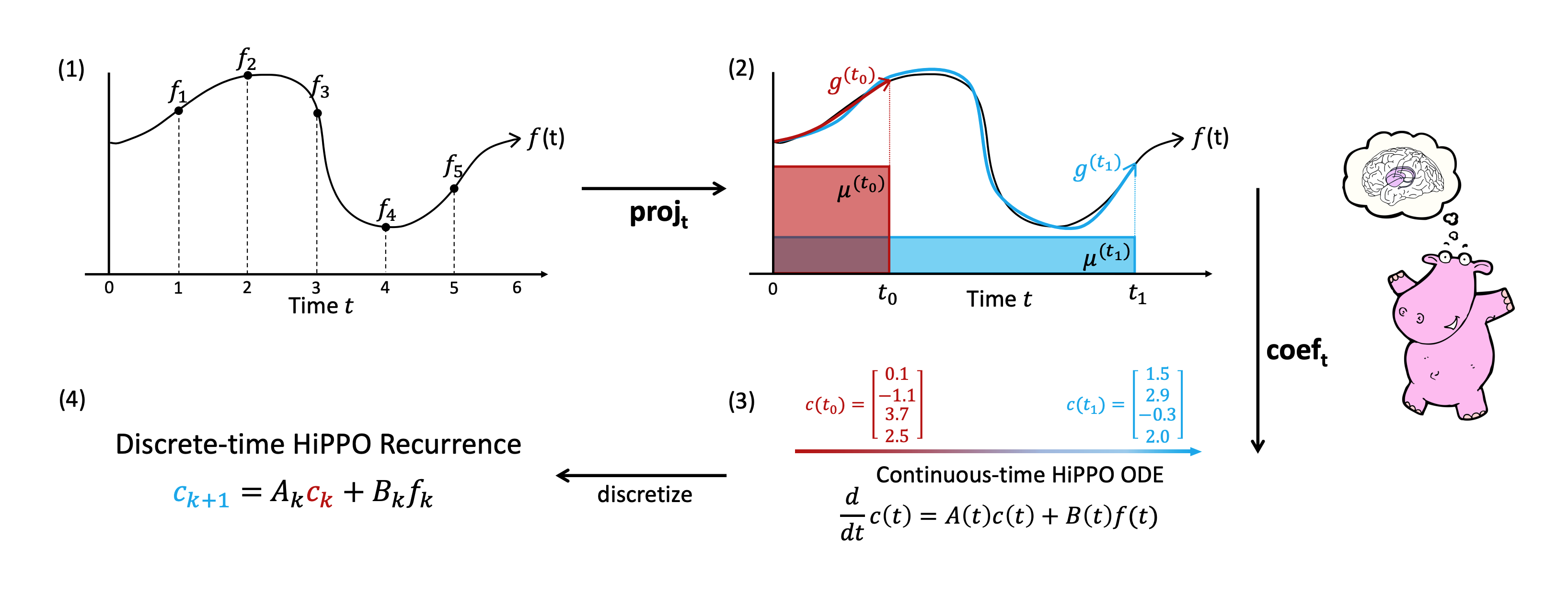
HiPPOは複数の直交多項式によって入力信号を近似する手法
-
(1)入力信号に対して,(2)で直交多項式(基底) $g$と測度(重み) $\mu$へと分解する
- この処理を $\mathrm{proj}_t$とする
- 入力信号 $f$に対して,近似誤差 $||f - g^{(t)}||_{L_2(\mu^{(t)})}$を最小化するような直交多項式 $g^{(t)} \in \mathcal{G}$へと $f$を写像する.
- $\mathcal{G}$は直交多項式の $N$次元部分空間
-
(3)で,ある測度に対する基底 $g^{(t)}$を係数 $c(t) \in \mathbb{R}^N$へと写像する
- この処理を $\mathrm{coef}_t$とする
-
このとき, $\mathrm{coef}_t \circ \mathrm{proj}_t$を $\mathrm{hippo}$関数と呼ぶ
- つまり, $f: \mathbb{R}→\mathbb{R}$を $c: \mathbb{R}→\mathbb{R}^N$へと変換する関数
- $\mathrm{hippo}$は関数を関数に写像しているので注意
-
この時,係数 $c(t)$は以下のODE(常微分方程式)を満たす.
$$\frac{d}{dt}c(t) = A(t)c(t) + B(t)f(t)$$ -
ただし, $A(t) \in {\mathbb R}^{N \times N}, B(t) \in {\mathbb R}^{N \times 1}$
-
実験では,測度 $\mu$は一様分布の場合が最も性能が良かったため,以降一様分布であると仮定.
-
このとき,連続空間では以下が成り立ち,
$$\frac{d}{dt}c(t) = -\frac{1}{t}A(t)c(t) + \frac{1}{t}B(t)f(t)$$
- 離散空間では以下が成り立つ.
$$c_{k+1} = \left(1 - \frac{A}{k}\right)c_k+\frac{1}{k}Bf_k$$
- ただし, $A, B$は以下の通り.
$$A_{nk} = \begin{cases}(2n+1)^{1/2}(2k+1)^{1/2} && \mathrm{if}; n > k \ n+1 && \mathrm{if}; n=k \ 0 && \mathrm{if}; n < k \end{cases}$$
$$B_{nk} = (2n+1)^{1/2}$$
- このとき, $A$をHiPPO行列と呼ぶ.
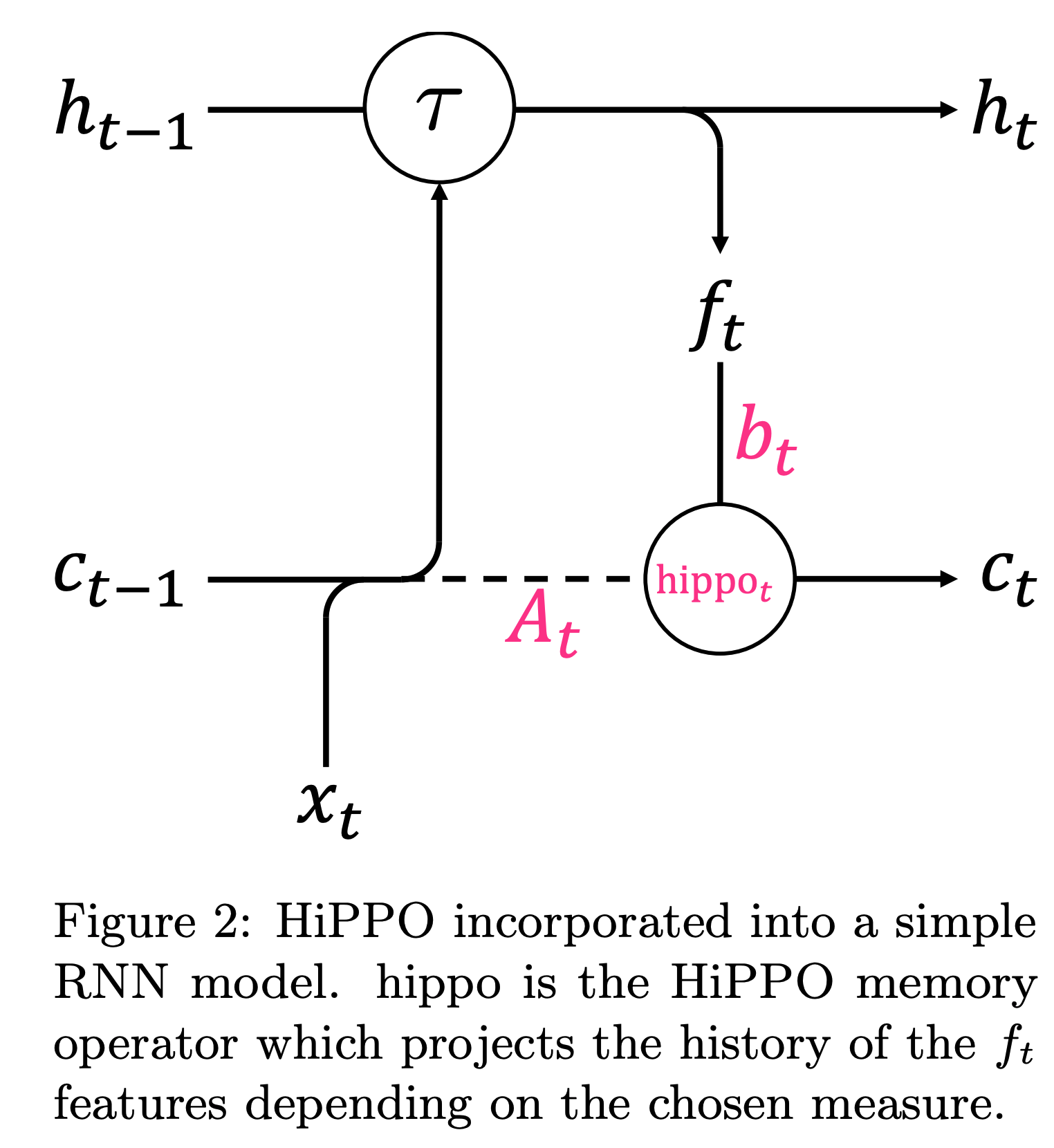
- $\mathrm{hippo}_t$はRNNに容易に組み込むことが可能
- hippoを組み込むだけで,劇的に精度が向上する
LSSL

-
Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers (Gu+., NeurIPS21)
-
状態空間モデルにHiPPOを導入し,recurrent + conv. の両方で処理できる手法LSSLを提案
- RNNs: 系列データの学習に向いているが,勾配消失などの問題より長距離系列の学習に限界あり
- CNNs: 高速かつ並列可能だが,系列データの学習に向いていない
- NDEs: 連続時間かつ長距離依存を扱うことができるが,効率が悪い
-
これら3つのパラダイムを状態空間モデルによって統合的に扱うことを目標とする.
-
状態空間モデル
$$\dot{x}(t) = Ax(t) + Bu(t)$$
$$y(t) = Cx(t)+Du(t)$$ -
GBTにより離散化 (GBT; generalized bilinear transform)
$$x(t + \Delta t) = (I - \alpha \Delta t \cdot A)^{-1}(I + (1 - \alpha) \Delta t \cdot A) x(t) + \Delta t (I - \alpha \Delta t \cdot A)^{-1} B \cdot u(t) $$
$$x_{i} = \bar{A}x_{i-1} + \bar{B}u_{i}$$
$$y_{i} = Cx_i+Du_i$$
$$\bar{A} := (I - \alpha \Delta t \cdot A)^{-1}(I + (1 - \alpha) \Delta t \cdot A)$$
$$\bar{B} := \Delta t (I - \alpha \Delta t \cdot A)^{-1} B$$
-
$A,B,C,D,\Delta t$はいずれも学習可能パラメタ
-
$\alpha = 0$でオイラー法, $\alpha = 1$でbackwardオイラー法, $\alpha = 1/2$で双一次変換
-
以降, $\alpha = 1/2$とする.(双一次変換)
-
また,LSSLは畳み込みで記述することもできる
- $y_k = C \left( \overline{A} \right)^k \overline{B} u_0 + C \left( \overline{A} \right)^{k-1} \overline{B} u_1 + \dots + C \overline{A} \overline{B} u_{k-1} + \overline{B} u_k + D u_k $より
$$y = \mathcal{K}_L(\overline{A}, \overline{B}, C) \ast u + D u $$
$$\mathcal{K}_L(A, B, C) = \left(C A^i B\right)_{i \in \lbrack L\rbrack} \in \mathbb{R}^L = (CB, CAB, \dots, CA^{L-1}B)$$
- ここで, $A$をHiPPO行列で固定するだけで,長距離依存を扱うことができるようになり,精度が劇的に向上することを確認 (LSSL-fixed)

S4

SSMの改善
-
SSM
- $x_i, u_i,y_i$をそれぞれ状態信号,入力信号, 出力信号とすると,
$$x_{i} = Ax_{i-1} + Bu_{i}$$
$$y_{i} = Cx_i+Du_i$$
- $x_i, u_i,y_i$をそれぞれ状態信号,入力信号, 出力信号とすると,
-
①前方トークンの記憶
- shift演算(e.g., $(a,b,c) → (0,a,b)$)を使うことで記憶
- 例えば,常に $A$がshift演算として機能するなら, $B=e_1$の時,連鎖的に $m$ステップ前までの $u_i$が $x_i$に格納される.→ $x_i = \lbrack u_i ,… , u_{i-m+1} \rbrack$
-
②トークン間の比較
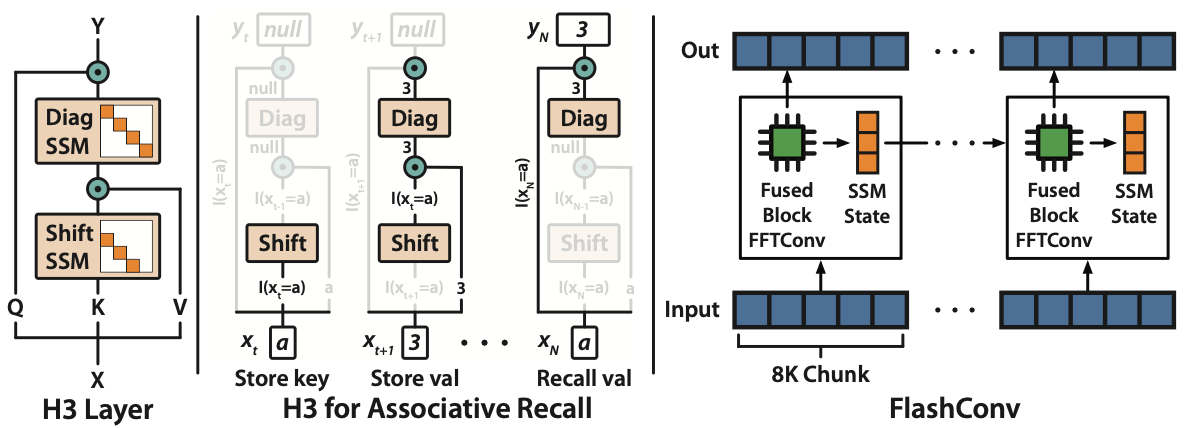
- Attentionと同様, $QK^\top V$のように乗算することで記憶
- $K^\top V$部分はHiPPOの対角行列versionによって初期化された対角行列によるSSMが通される
- 対角行列の初期化はこちらを参照.
- HiPPOについては以下を参照
-
最終的には以下のように設計
- 計算量の観点からEfficient Transformer系列に倣って,以下のように設計
$$Q \odot \mathrm{SSM_{diag}}(\mathrm{SSM_{shift}(K) \odot V})$$ - すなわち, $K^\top V$を先に計算しておく
- 計算量の観点からEfficient Transformer系列に倣って,以下のように設計
The shift SSM can detect when a particular event occurs, and the diagonal SSM can remember a token afterwards for the rest of the sequence

- H3の流れ
- 入力 $u$に対して $Q = uW_Q, K = uW_K, V = uW_v$を得る.
- $K$を $\mathrm{SSM_{shift}}$に通して $\bar{K}$を得る.
- $Q,K,V$をmulti-head化 (すなわちdim方向で分割)
- 各headごとに $KV := \mathrm{SSM_{diag}}(\bar{K}V^\top)$を計算.
- ${Q_i \in \mathbb{R}^d | i = 1,…,N}$ごとに $Q_i(KV)_i$を計算してconcat→ $Q \odot \mathrm{SSM_{diag}}(\mathrm{SSM_{shift}(K) \odot V})$を得る.
- headをconcatして最終的な値を得る.
