-
BERT同様, 転移学習モデル
- なので, IMGトークンやCLSトークンを導入する
-
画像の埋め込みはどういう実装…?
- 例えばViTだと, 普通に行列 $E$を掛け合わせている or ResNetを用いる (これをハイブリット方式と呼ぶ)
-
各パッチをEで埋め込み、CLSトークンを連結したのち、位置エンコーディングEposを加算しています。ちなみに EEの代わりにResNetで各パッチを埋め込んでも良さそうです。この場合、パッチはFlattenさせずにResNetへと入力し、その出力に対してFlattenを行います。論文中ではパッチの最初の埋め込みにResNetを用いる手法のことをハイブリッドと呼んでいます。
- https://qiita.com/omiita/items/0049ade809c4817670d7
-
- 例えばViTだと, 普通に行列 $E$を掛け合わせている or ResNetを用いる (これをハイブリット方式と呼ぶ)
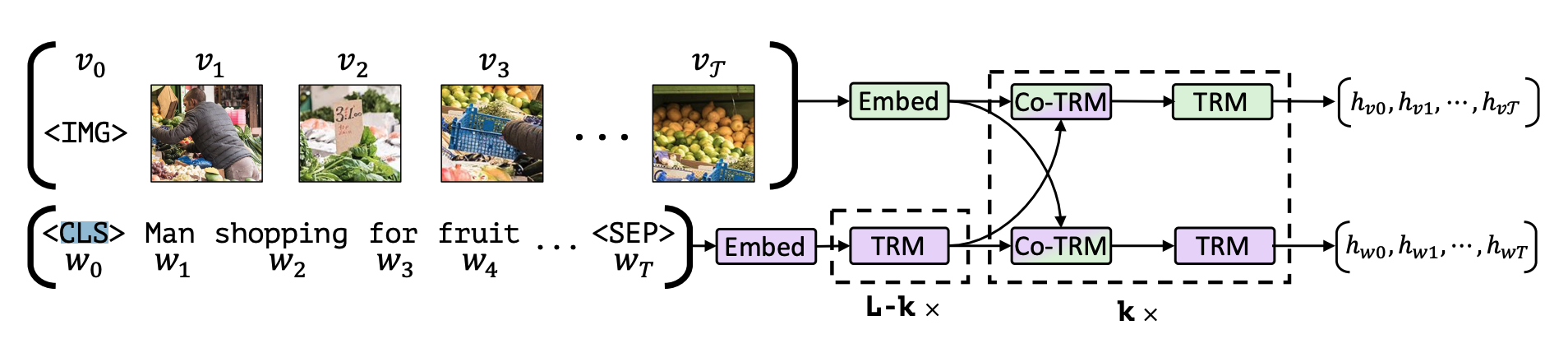
- Co-Attention Transformerにより, 画像と文章をfusionさせる
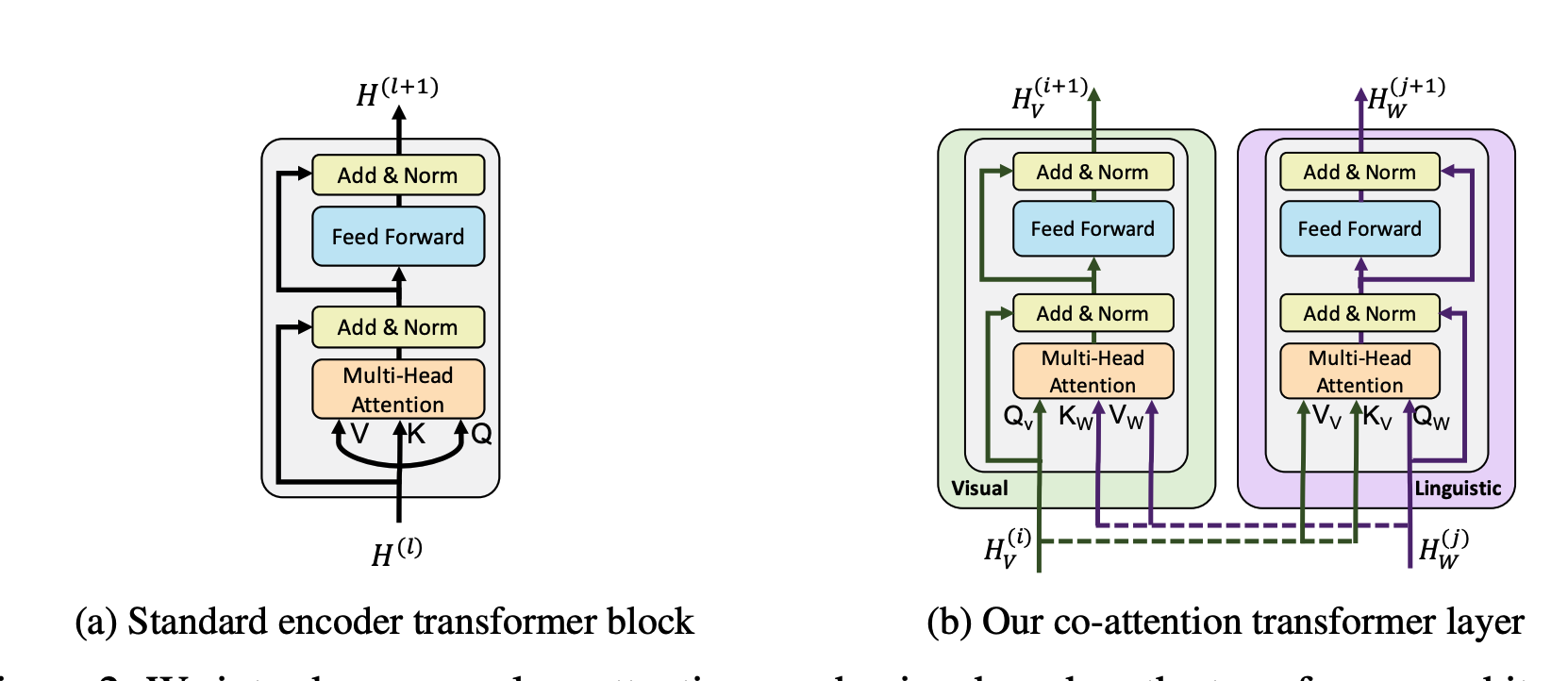
-
どのようにfusionさせるのが最適か?
-
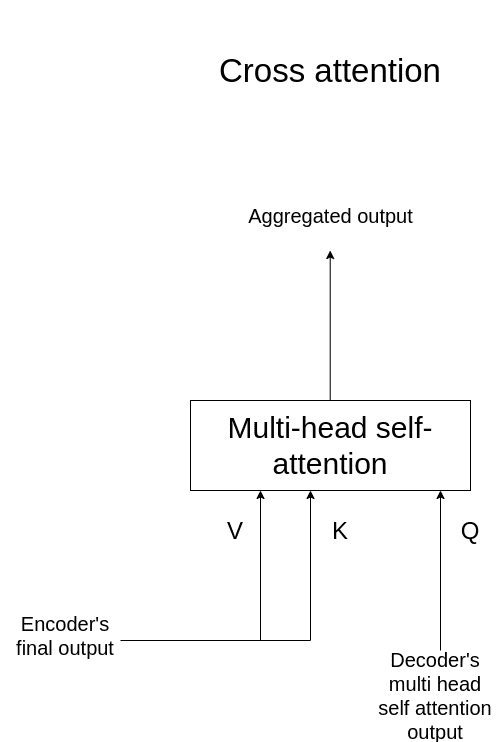
通常のTransformerで, encoderの出力をdecoderに入力する機構は, Cross-Attentionと呼ばれる…? → 要出展 todo