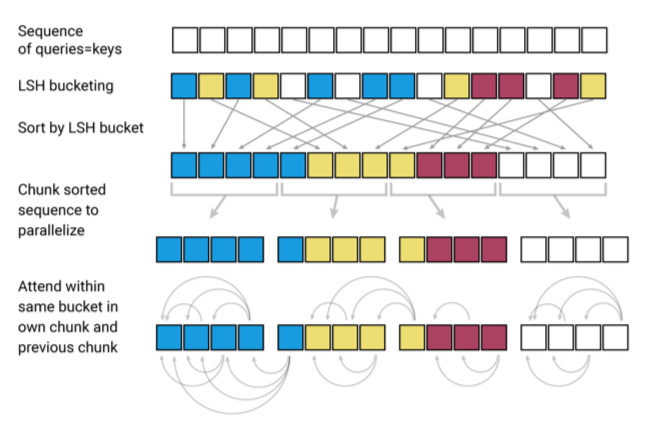
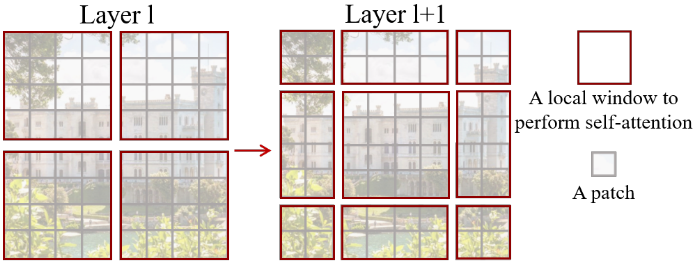
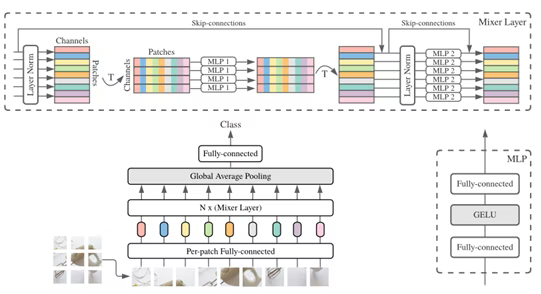
MetaFormer is Actually What You Need for Vision MetaFormerはモデルを抽象化したもの 重要なのはToken mixing であるという主張 AttentionやMLP-mixerはtokenをごちゃまぜにしてる 例えばMLP なら, 全結合によってごちゃごちゃになる Attentionではなく, Poolingでもいいんじゃね? → PoolFormer https://twitter.com/sei_shinagawa/status/1472115254171947009 @sei_shinagawa MetaFormerの論文でも表6 ...