【論文メモ】Hungry Hungry Hippos: Towards Language Modeling with State Space Models
· ☕ 6 min read
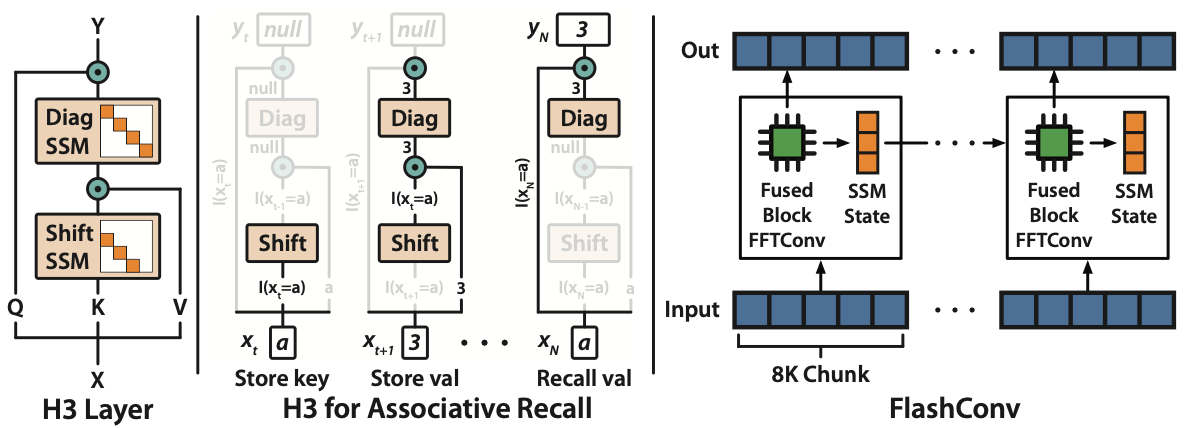
この度,SONY様のnnablaチャンネルにH3の解説動画を寄稿しました. 本記事ではなく動画の視聴の方を推奨します. 概要 ICLR23 状態空間モデル(state-space model; SSM)は様々なモダリティにおいて有用性が検証されてきたが,未だ言語系においては確認できていない. また,SSMは $\mathcal{O}(L)$であるにも拘ら ...