-
分類問題について, 生成モデルで用いられるEnergy Based Modelに基づいた学習手法を提案
-
一般的な学習
-
あるNNを $f_\theta(x)$とすると, 出力の $y$番目を $f_\theta(x)[y\rbrack$として, softmaxは以下のように表される
$$p_{\theta}(y|{\bf x}) = \frac{\exp{\left(f_{\theta}({\bf x})[y\rbrack \right)} } { \sum_{y^{\prime}}\exp{\left(f_{\theta}({\bf x})[y^{\prime}\rbrack \right)} }$$ -
ここで, Energy Based Modelでは
$$p_{\theta}(\boldsymbol{x},y) = \frac{\textrm{exp}(-E_{\theta}(\boldsymbol{x},y))}{Z_{\theta}}$$ -
と定義されるので, エネルギー関数 $E_{\theta}(\boldsymbol{x},y)$を
$$E_{\theta}(\boldsymbol{x},y) := -\ln(f_{\theta}({\boldsymbol{x}})[y\rbrack)$$ -
と定義すれば, エネルギー関数 $E_{\theta}(\boldsymbol{x})$は $y$について周辺化して
$$E_\theta(\boldsymbol{x}) := -\sum_y \ln(f_\theta(\boldsymbol{x})[y\rbrack)$$ -
と定義でき, 一般的な分類学習問題はEnergy Based Modelへと再解釈できる
- これをJoint Energy-Based Model (JEM)と呼ぶ
-
-
図にすると下のような感じ
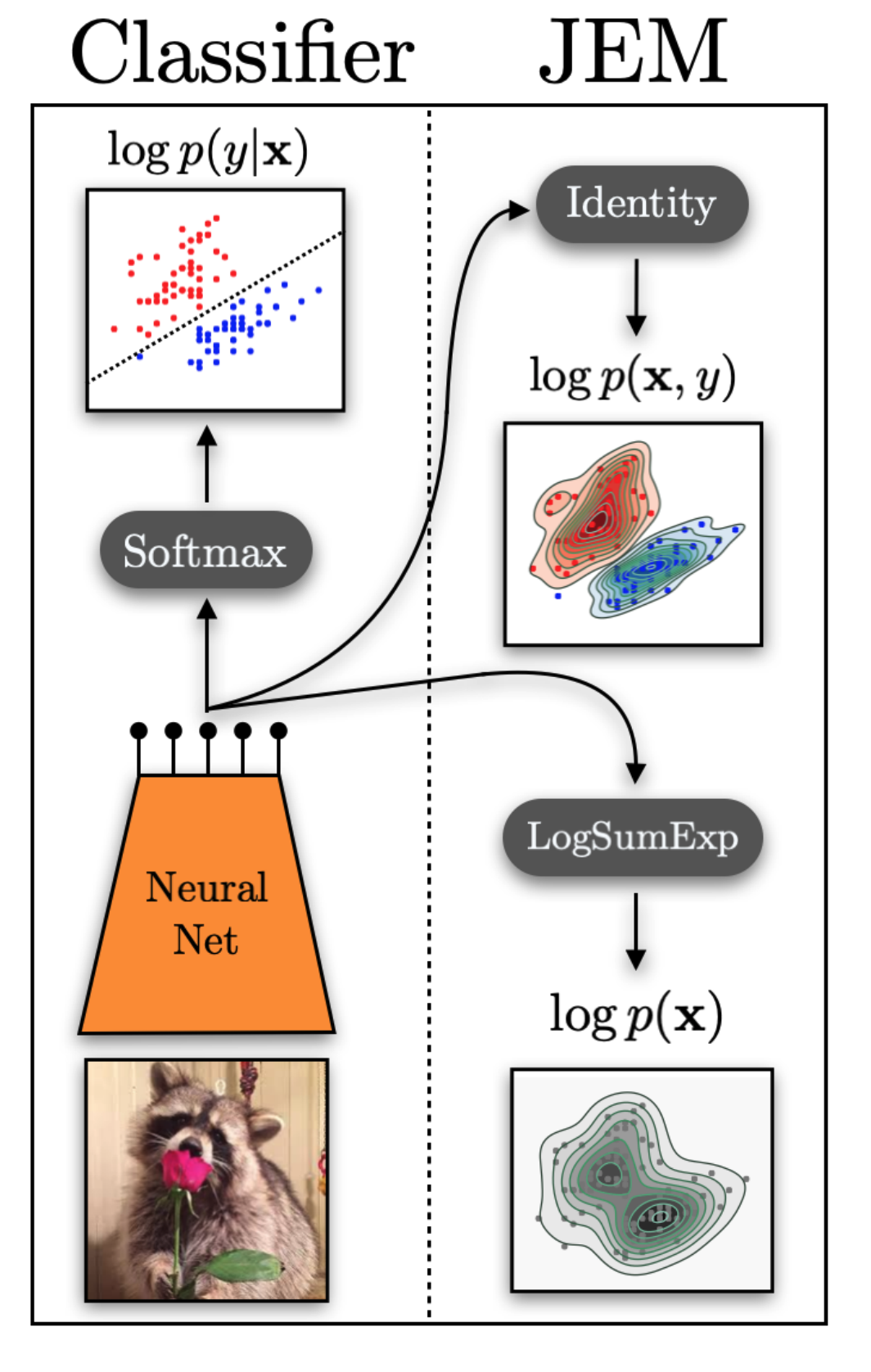
- このとき, 最適化したい対数尤度は
$$\ln(p_\theta(y|x)) = \ln(p_\theta(x)) + \ln(p_\theta(x,y))$$ - 第二項はそのままクロスエントロピーとして最適化すればよいので第二項だけ考える
- 第一項 $\ln(p_\theta(x))$はEnergy Based Modelのページにも書いたとおり, 負の勾配を取ると
$$\nabla_{\theta}E_{\theta}(x_{train}) - \mathbb{E}_{sample}[\nabla_{\theta}E_{\theta}(x_{sample})\rbrack$$ - なので, Stochastic Gradient Langevin Dynamicsによるサンプリングを行えば学習できる
- 第一項 $\ln(p_\theta(x))$はEnergy Based Modelのページにも書いたとおり, 負の勾配を取ると