-
ICLR22
-
大規模モデルを高速かつ低消費メモリでfine-tuningする新たな手法
-
HypernetworksのようにTransformerの各層に学習可能なパラメタを挿入する (Adaptation層)
- しかし,重みを固定するにしてもAdaptation層を学習させるためにはGPUに載せないと意味ないので,結局時間が掛かってしまう
- そこで,新たな学習手法としてLoRAを提案
-
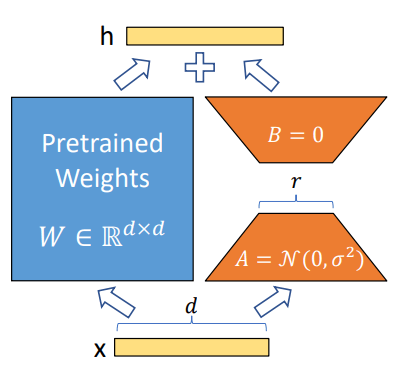
LoRAでは,重み $W\in \mathbb{R}^{d\times k}$の差分 $\Delta W$を学習させる.
-
また $\Delta W$を低ランクの行列 $B \in \mathbb{R}^{d\times r}$と $A \in \mathbb{R}^{r\times k}$に分解する. (どちらも学習対象)
$$y = (W+\Delta W)x = (W + BA)x$$ -
encoder-decoderのイメージに近い
- 特定タスクに関して言えば,重みに無駄なものがあるだろうという推測
-
When adapting to a specific task, Aghajanyan et al. (2020) shows that the pre-trained language models have a low “instrisic dimension” and can still learn efficiently despite a random projection to a smaller subspace.
- (Intrinsic dimensionのtypoでは…)
-
別の利点として,重みを全取っ替えしないで良いので,タスクごとに $BA$だけを差し替えるだけで簡単にモデルを切り替えることができる.
-
Another benefit is that we can switch between tasks while deployed at a much lower cost by only swapping the LoRA weights as opposed to all the parameters.