はじめに
- ECCV22のbest paper
#ECCV2022 Paper Awards pic.twitter.com/u9awGVCgSr
— European Conference on Computer Vision (ECCV) (@eccvconf) October 27, 2022
概要
-
二つのモデルの挙動を比較することは極めて重要
- しかし, それぞれが異なるアーキテクチャにおけるモデルの比較方法は依然として研究が不十分.
-
そこで, この論文では(Partial) Distance Correlationを機械学習に応用する手法を提案.
-
(Partial) Distance Correlationを用いることで様々な応用が期待される.
-
論文中では以下の3つが提案されている.
- モデルの条件付け
- 敵対的サンプルへの防御
- Disentangledな表現の学習
-
(Partial) Distance Correlationについては
- 輪講スライド
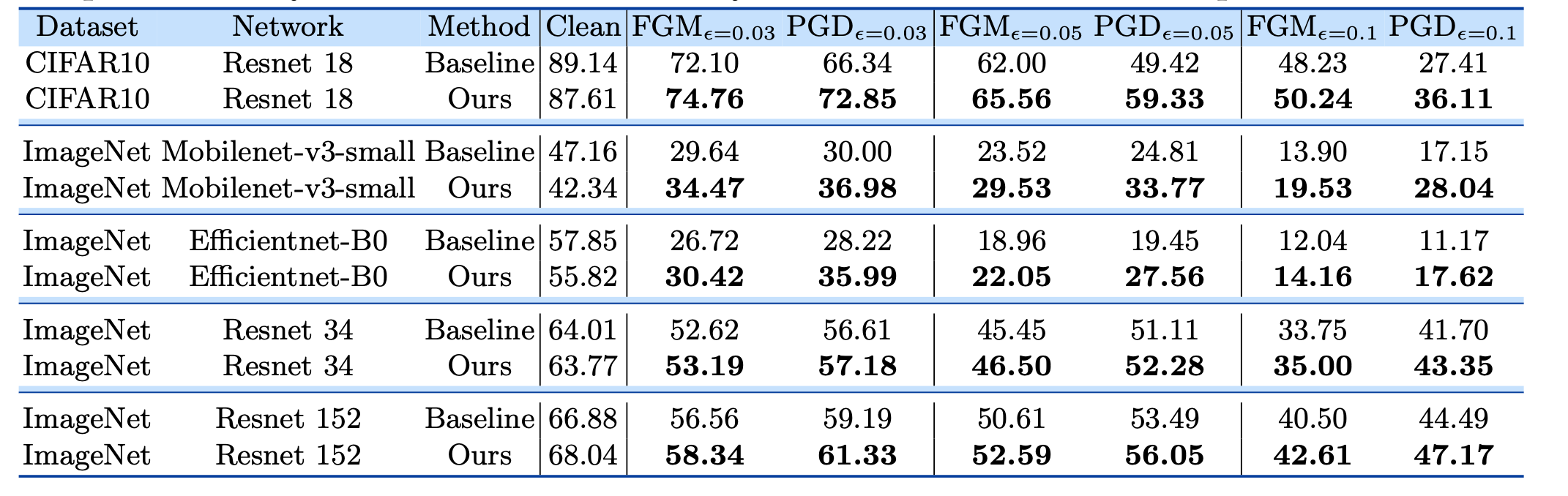
敵対的サンプルへの防御
- あるモデルXにおいて有効な敵対的サンプル $\tilde{x}$が存在する場合, 同じ構造のモデルYにおいても $\tilde{x}$が有効であることが多い.
- したがって, 二つのモデル $f_1, f_2$に対して, ある中間層をそれぞれ $g_1, g_2$とすると, $g_1, g_2$の相関を下げれば, 敵対的サンプルへの防御につながると考えられる.
- そこで, 以下のような損失を定義
$$\text{Loss}_{\text{total}} = \text{Loss}_{\text{CE}}(f_2(x),y) + \alpha \cdot \text{Loss}_{\text{DC}}(g_1(x), g_2(x))$$
-
ここで, $g_1, g_2$の次元は一致しなくても良いことに注意
-
結果は以下の通り.
モデルにおける情報量の比較
-
Distance Correlationは出力の次元に依存しないので, 異なるアーキテクチャのモデル同士を比較することが可能

-
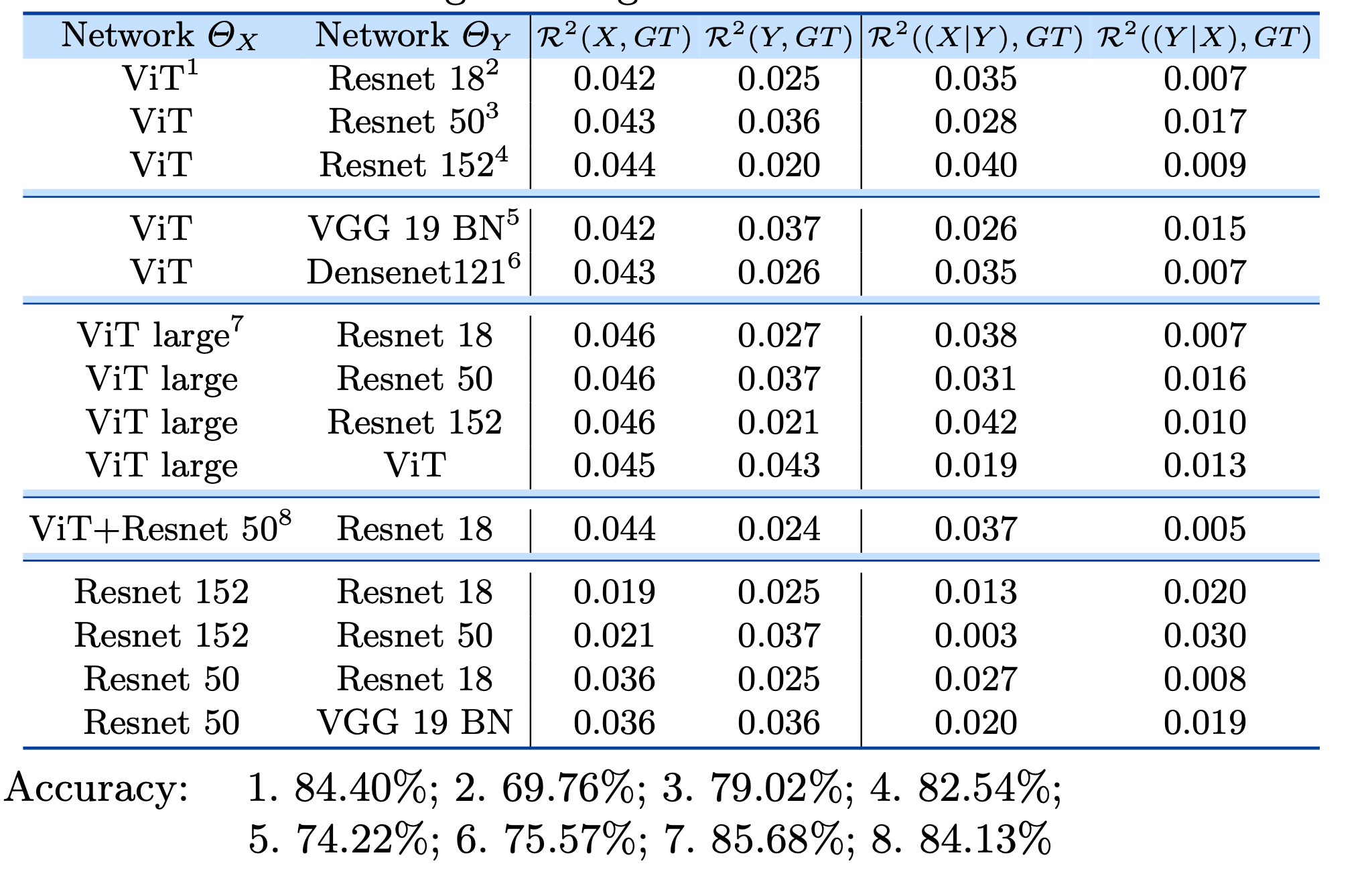
さらに, Partial Distance Correlation(PCD)を用いることで, 「モデルYが学習した情報」以外にモデルXが何を学習しているのかを推測することができる.
-
例えば, $\mathcal{R}^2\left( (X|Y),GT\right)$を計算すれば, Yで条件付けされたXとGTの相関を計算することができる
-
ここで, 「Yで条件付けされたX」とは「Yを前提とするX」に等しいので, 要はモデル $X | Y$は「モデルYが学習した情報」を除いたモデルXの情報のことを指す.
-
GTにはclass名をBERTに通した出力を使用.
- one-hotベクトル等でも良かったが, ベクトル同士の関係性が皆無なのでBERTを採用.
-
モデルYが学習した情報とは異なる情報をモデルXに学習させるために, 以下のような損失を定義
- X, Yをpretrainした後に, Xのみ以下の損失でfine-tuning
-
$$\text{Loss}_{\text{CE}}(f_1(x),y) - \alpha \cdot \text{Loss}_{\text{PDC}}\left( (g_1(x)| g_2(x)), gt \right)$$
- 以下の図はGradCamを用いてモデル $X | Y$の注目領域を可視化した結果
- ViT \ ResNet を見ると, より被写体に注目していることから, ViTはResNetでは捉えられない細かい領域を捉えている可能性が示唆される.

- ViT \ ResNet を見ると, より被写体に注目していることから, ViTはResNetでは捉えられない細かい領域を捉えている可能性が示唆される.
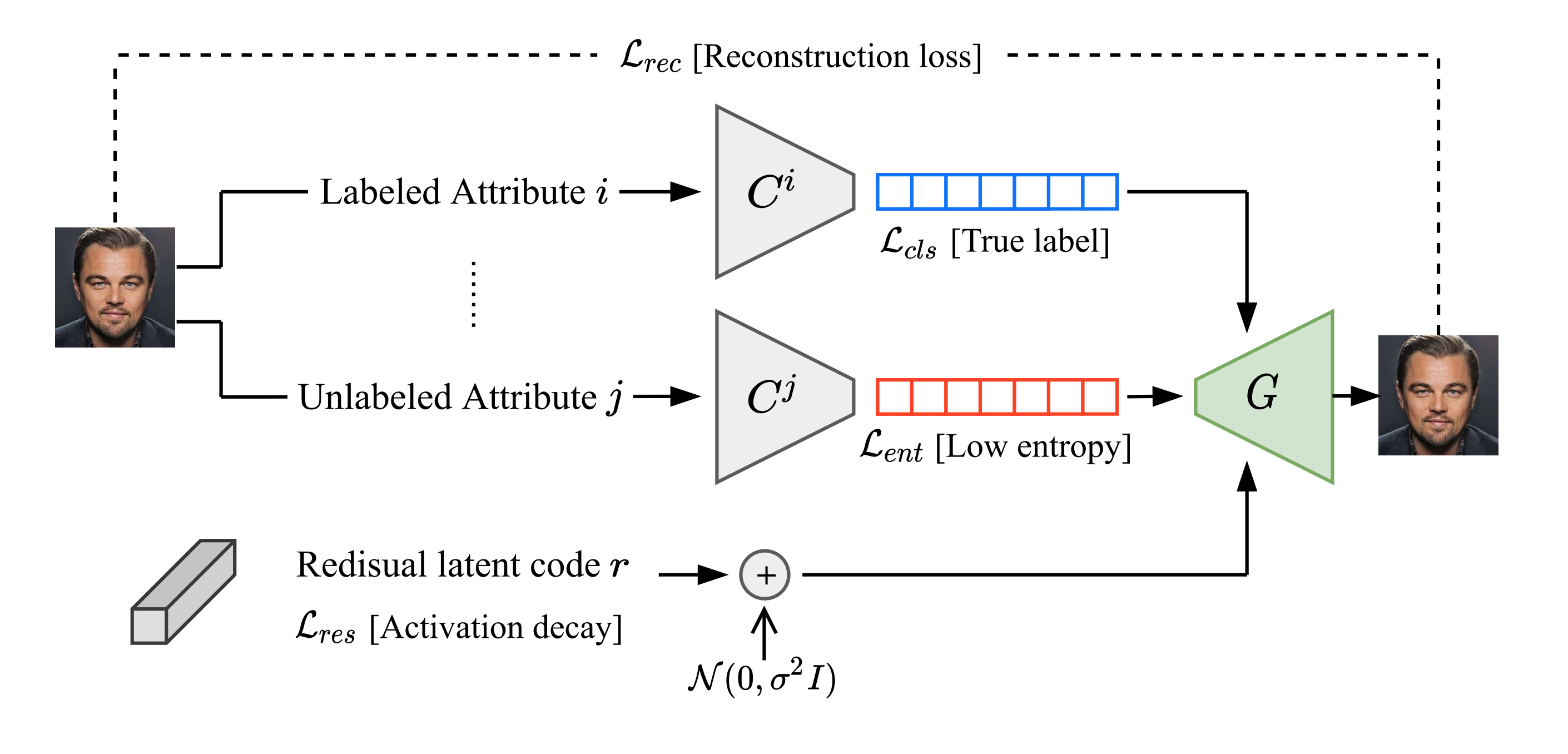
Disentanglement
- GeneratorにStyleGAN2を使い, (Gabbay+, NeurIPS21)の要領で学習
- データセットはFFHQ
- (Gabbay+, NeurIPS21)での本来の損失 $\text{L}_{\text{res}}$は $\text{L}_{\text{res}}=\sum_{i=1}^n ||r_i||^2$だが,
- 本論文では属性 $f^1,f^2,…,f^k$に対して, $\text{L}_{\text{res}}=dCor([f^1;f^2;…;f^k\rbrack, r)$を使用