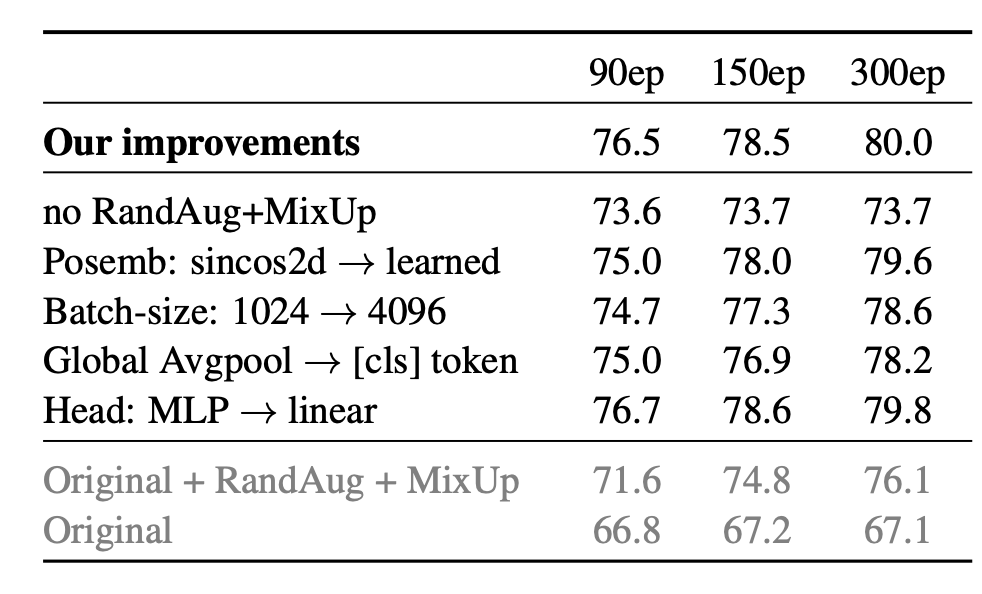
-
The main differences from [4, 12 are a batch-size of 1024 instead of 4096, the use of global average-pooling (GAP) instead of a class token [2, 11 , fixed 2D sin-cos position embeddings [2, and the introduction of a small amount of RandAugment [3 and Mixup [21 (level 10 and probability 0.2 respectively, which is less than [12). These small changes lead to significantly better performance than that originally reported in [4.