- AttentionとDepthwise-Conv(DwConv)は似ているよ, という論文
-
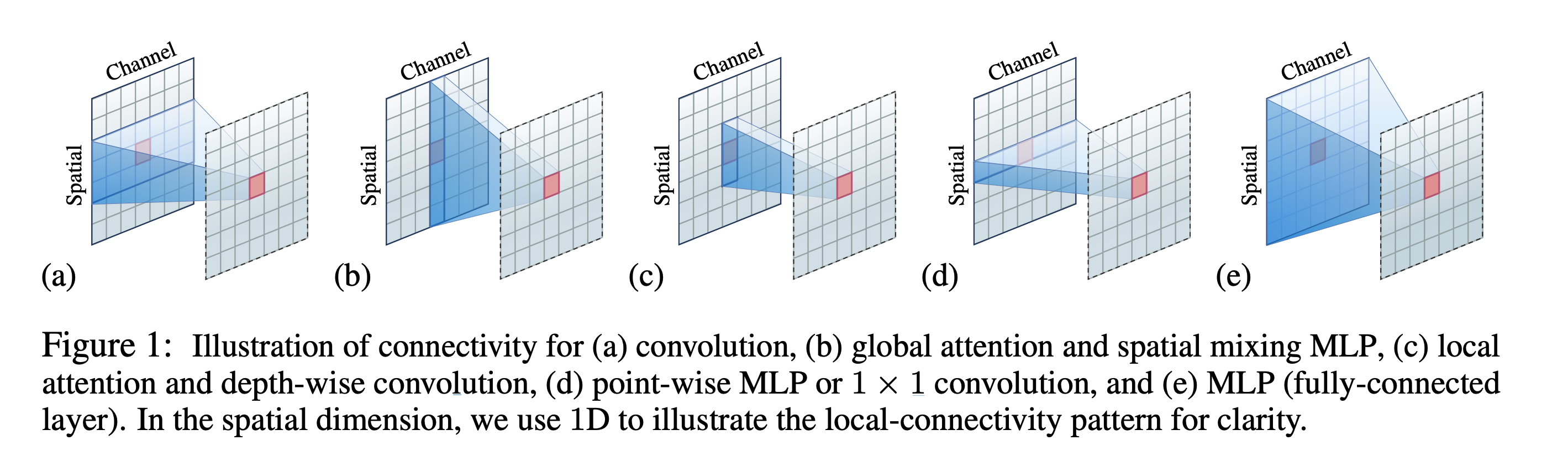
上図は画像をflatten or patchifyしたものがspatial方向であると捉えればOK
- (a): 畳み込み
- ある区間の画素値と複数チャネルを使って一つの埋め込みを生成
- (c): DepthWise と local attention
- ある一つのチャネルに対して, 区間の画素値のみから生成 (PointWise・Depthwise)
- (a): 畳み込み
-
AttentionとDepthwise-Conv(DwConv)は似ているよ
-
同じとこ
- 上図 (c) のように, “sparse connectivity"として同じ様式を取る
- すなわち, ある一つのチャンネルに対して加重和が実行される
- 上図 (c) のように, “sparse connectivity"として同じ様式を取る
-
違うとこ
-
1つ目: DwConvは空間方向に重み共有を行い, Local Attentionはチャネル方向に重みを共有
- DwConvの重み共有 → 計算量削減・ネットワークの表現力向上
- Local Attentionの重み共有 → proper weight sharing across channels to get better performance. (properとは…)
-
2つ目: DwConvはStatic Weight であり, Local AtentionはDynamic weight である
-
DwConvの重みはback propagationによって学習される一つのパラメタであるが, Local Attentionの重みはqueryを入力として得られるものであり, query依存であるからDynamicであり, より高い表現力を持つ (もちろん学習はback propagationだが)
- つまり, Attentionは入力に対して動的にカーネルが変わるConvolutionと考えられる
-
本論文では, DwConvをDynamic weightにする方法について, 2つ提案している
- 一つはhomogeneousな方法
- 提案されてるのは各チャネルごとのテンソル ${\boldsymbol{x}_i}$をGlobal Average Poolingに通したものを入力としてMLPで重みを得る方法
- SE Netはこっちに分類されるらしい (Squeeze-and-Excitation)
チャネルをsqueezeしてexcitationすることで適度にmixされるからある意味Dynamicといえる
- もう一つはnon-homogeneousな方法
- 例えば, 重み共有をせず各チャネル $\boldsymbol{x_i}$ごとにMLPを通して重みを生成
- 一つはhomogeneousな方法
-
-
-
-
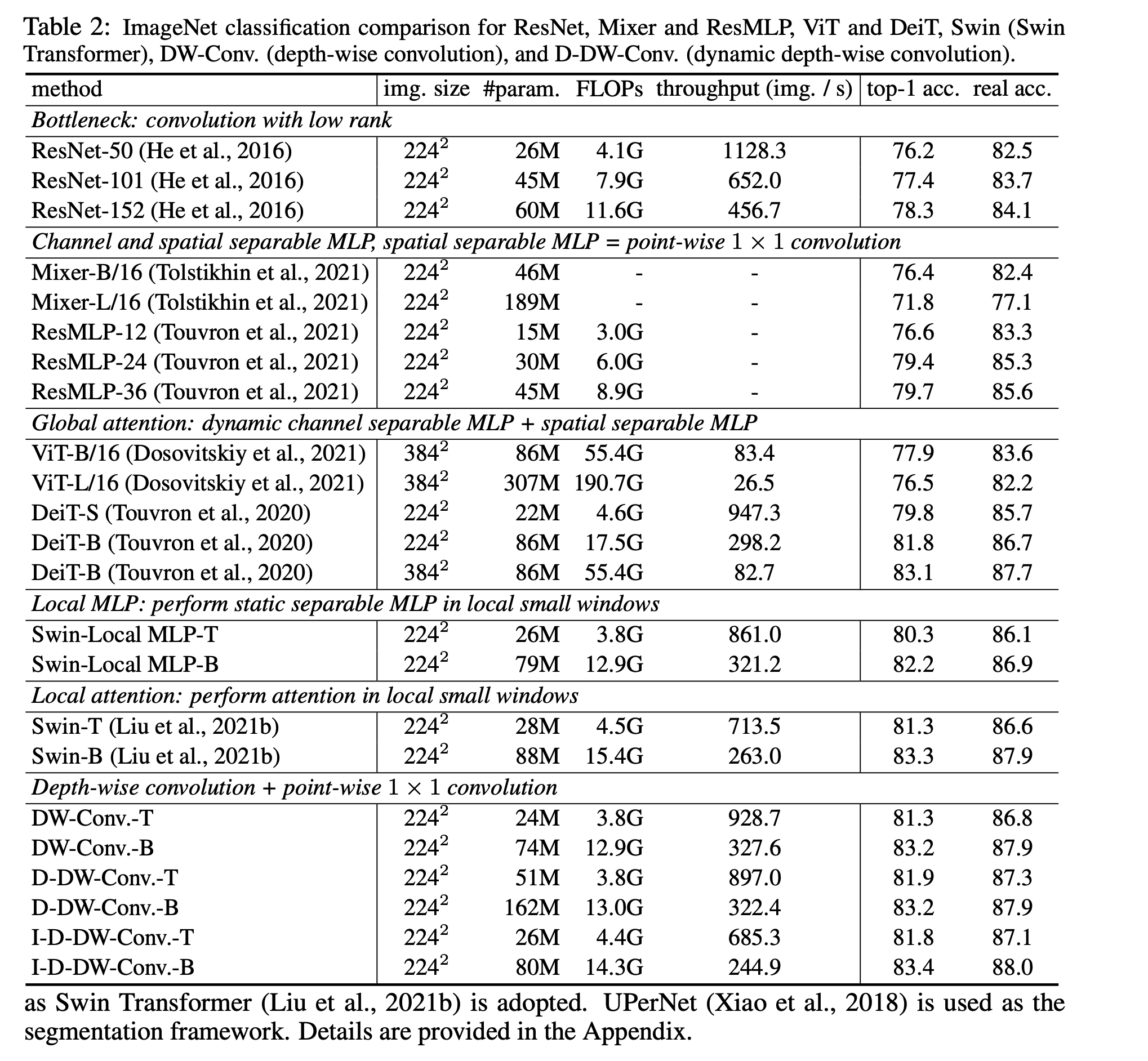
Dynamic weight は意味あるの?
-
-
static version: 80.3% and 82.2%
-
→ dynamic version: 81.3% and 83.3%
-
→ 意味ありといえる
-
-
各手法の違い
