post
SimSiam
· ☕ 1 min read
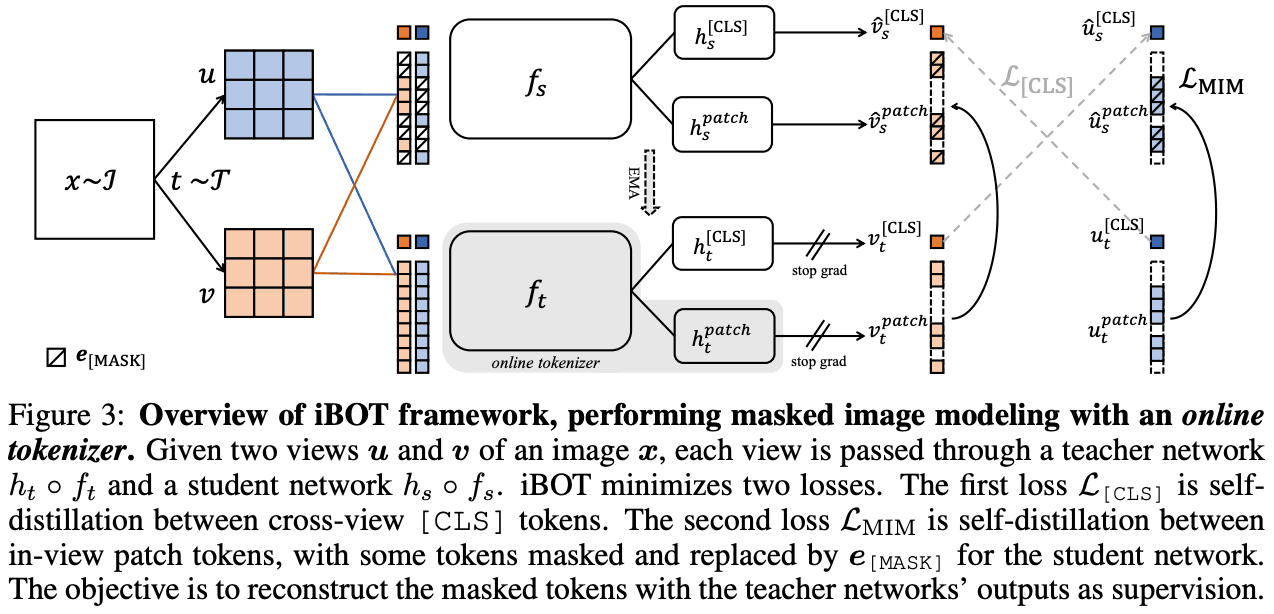
EMアルゴリズムとの関連 ↓ どうやらEMアルゴリズムと深い関係があるらしいことが論文中にも書いてある https://speakerdeck.com/sansandsoc/simsiam-exploring-simple-siamese-representation-learning?slide=17 ...
warmup
· ☕ 1 min read
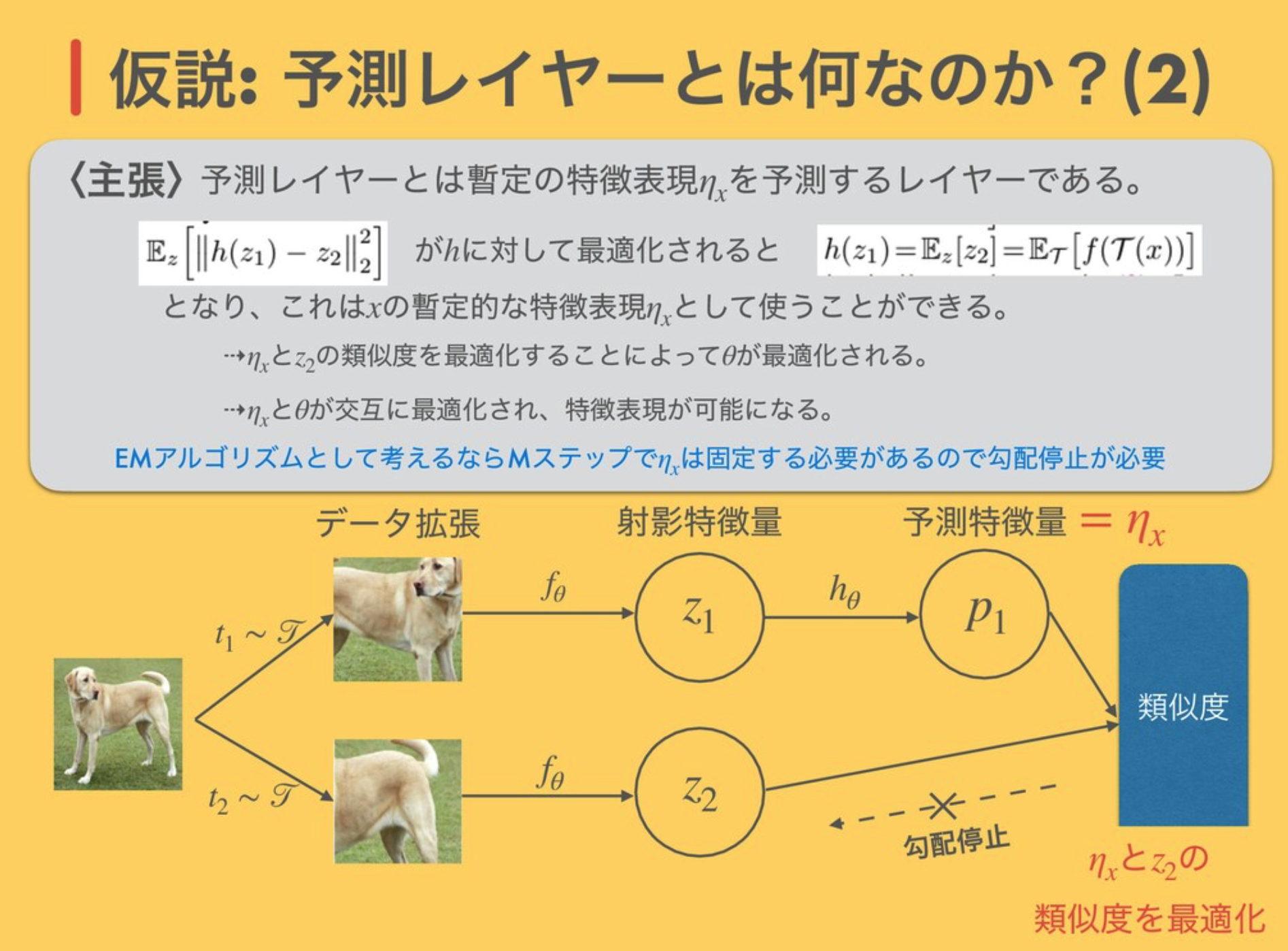
MomentumやAdamといった移動平均を使うオプティマイザーなら、移動平均を取るための勾配の蓄積が足りないと, 学習の初期段階において値の信頼度が低い(よって変な値が出て精度を損ねる)ということも考えられます。 https://qiita.com/omiita/items/d24568a835da6911b01e ...
学習率
· ☕ 1 min read
cosアニーリング warm-restart cyclical-learning rate バッチサイズと深い関係がある 学習率の決め方 https://www.slideshare.net/TakujiTahara/20190713-kaggle-tokyo-meetup-lt-nn-no-gokigentori-tawara-155334755 ...

重み共有
· ☕ 1 min read
基本的にはsumを取れば良いらしい PyTorchだと普通に呼び出せばそのまま重みの共有になるらしい https://vasteelab.com/2022/01/31/post-1951/ http://neural.vision/blog/deep-learning/backpropagation-with-shared-weights/ ...

GemPooling
· ☕ 1 min read
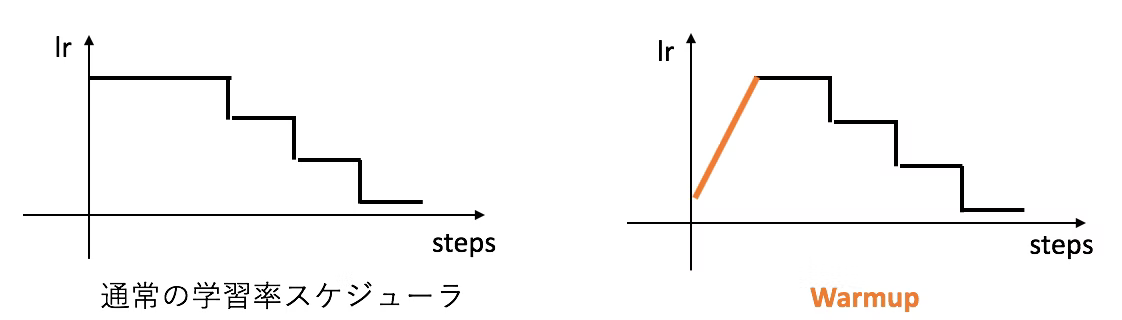
初出 Fine-tuning CNN Image Retrieval with No Human Annotation そもそも, チャネルごとのPoolingがなぜうまく行くのか ...
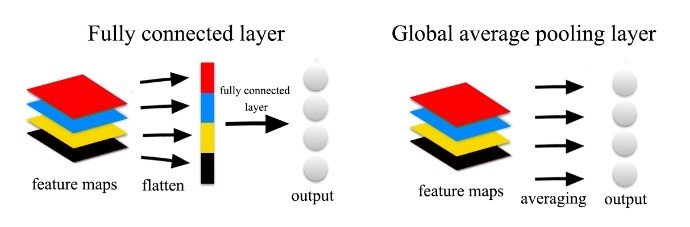
Global Average Pooling
· ☕ 1 min read
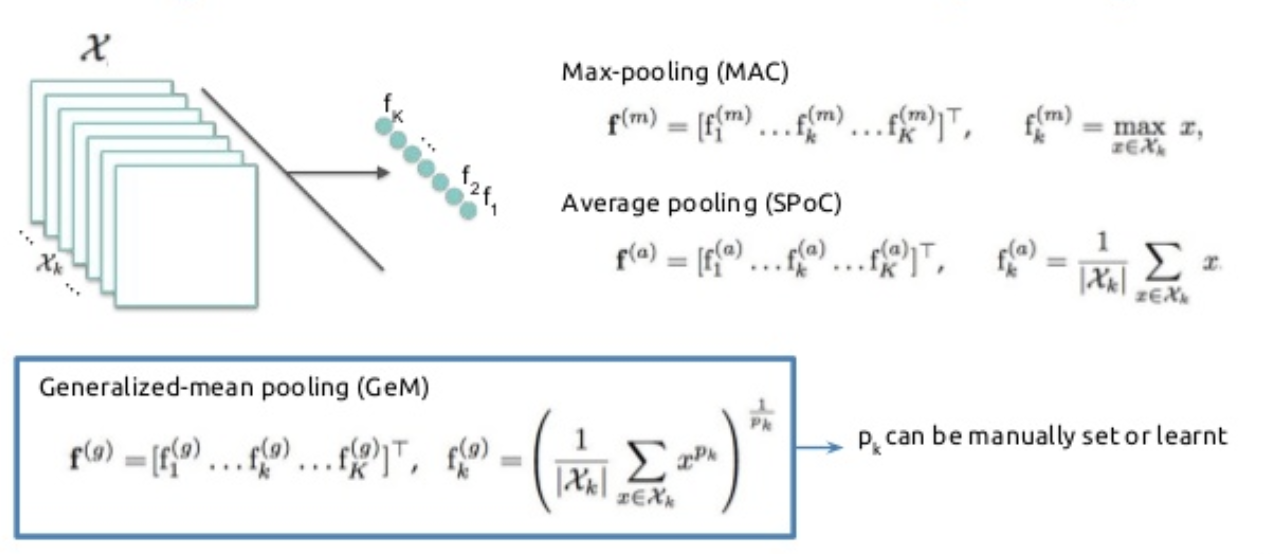
例えばVGG-16を考えてみると, 最後の全結合って計算量やばいよね VGG-16だと, $7 \times 7 \times 512 → 1 \times 1 \times 4096 $ で全結合 パラメタ数は $(7 \times 7 \times 512) \times (1 \times 1 \times 4096) $ → エグい チャネル方向に平均をとって, そいつらをconcatしてあげればOKじゃない? → Global Average Pooling 性能は普通にflattenした場合とさほど変わらないらしい https://qiita.com/mine820/items/1e49bca6d215ce88594a ...
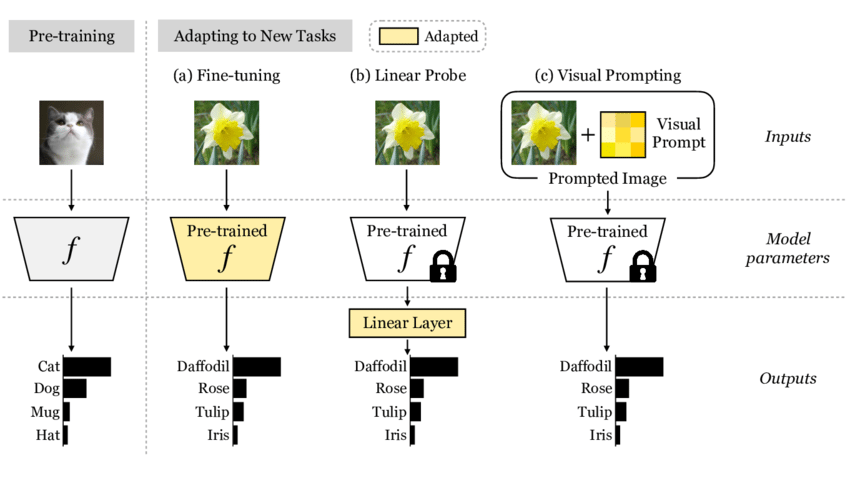
intermediate fine-tuning
· ☕ 1 min read
普通にpre-train data-richなデータセットで学習 fine-tuning NLPにおいては, 結構よく使われる手法らしい by BeiT ...
linear probe
· ☕ 1 min read
linear probingだけでは, 有用だが非線形な特徴量は扱えない そこで, partial fine-tuningと呼ばれるものがある 最後の何層かだけを再び学習対象として, それら以外はfreezeさせる intermediate fine-tuning というものもある 結構よく使われる手法らしい ...
CLS
· ☕ 1 min read
普通のtransformerモデルだとCLSをそのままMLPに通して分類器を構築する 本当にそれで良いの?? BERT系だと CLSを使うパターン BERT / ViT の画像分類タスク 後続のトークンの先頭と最後だけ使うパターン BERTのQAタスク Global Average Poolingで全トークンを圧縮するパターン BeiT の画像分類 がある https://www.ai-shift.co.jp/techblog/2145 todo ...
alienware
· ☕ 1 min read
ls -l /sys/class/leds alienware::global_brightness /sys/class/leds/alienware::global_brightness/brightness https://forum.manjaro.org/t/keyboard-rgb-light-on-off/45028/25 ...
torch.view
· ☕ 1 min read
同じ順序でメモリ上に展開されてないとダメだから注意 1 2 3 4 >>> torch.t(x).view(-1, 2) Traceback (most recent call last): File "<stdin>", line 1, in <module> RuntimeError: invalid argument 2: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Call .contiguous() before .view(). at /Users/soumith/code/builder/wheel/pytorch-src/aten/src/TH/generic/THTensor.cpp:237 1 2 3 4 5 6 x = torch.Tensor([[[ 1., 5., 9.], [ 2., 6., 10.], [ 3., 7., 11.], [ 4., 8., 12.]]]) x = x.unsqueeze(0) print(x.transpose(-1,-2).view(1,-1,2)) ↑ これだとメモリ上に展開されてないからダメ 1 2 3 x = torch.Tensor([[1,2,3,4],[5,6,7,8],[9,10,11,12]]) x = x.unsqueeze(0).transpose(-1,-2) print(x.transpose(-1,-2).view(1,-1,2)) ↑こっちだとOK ...
Influenced-Balanced Loss
· ☕ 0 min read
...