Efficient Transformer
· ☕ 1 min read
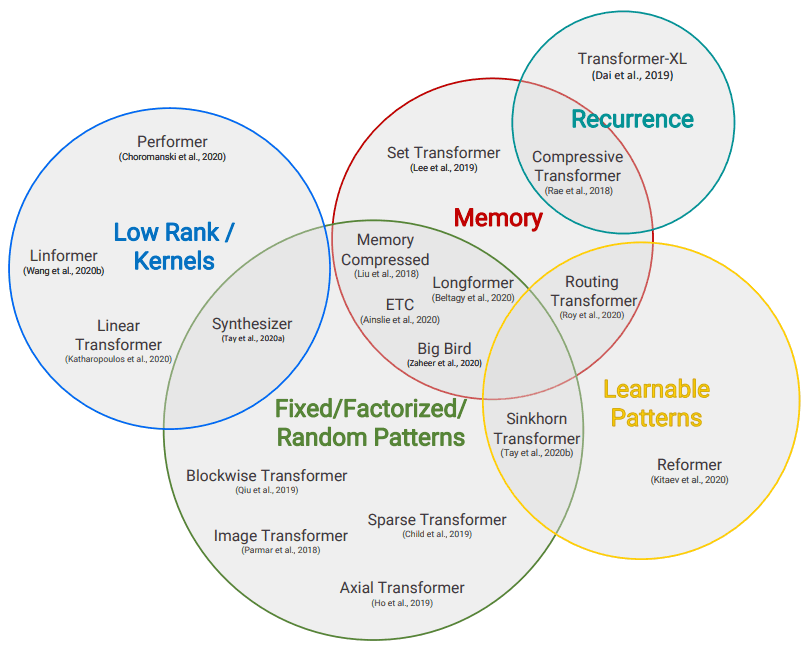
サーベイ→ https://arxiv.org/abs/2009.06732 Fixed Patterns Blockwise Patterns シーケンスを局所的なサイズにクロップ Strided Patterns ストライドで計算 Compressed Patterns poolingなどでダウンサンプリング Combination of Patterns Learnable Patterns ReformerやRouting Transformer など 重要度が高いもののみ使用 Memory Set Transformerなど Low-Rank Methods Kernels Recurrence ...