【論文メモ】ConvNext
· ☕ 1 min read
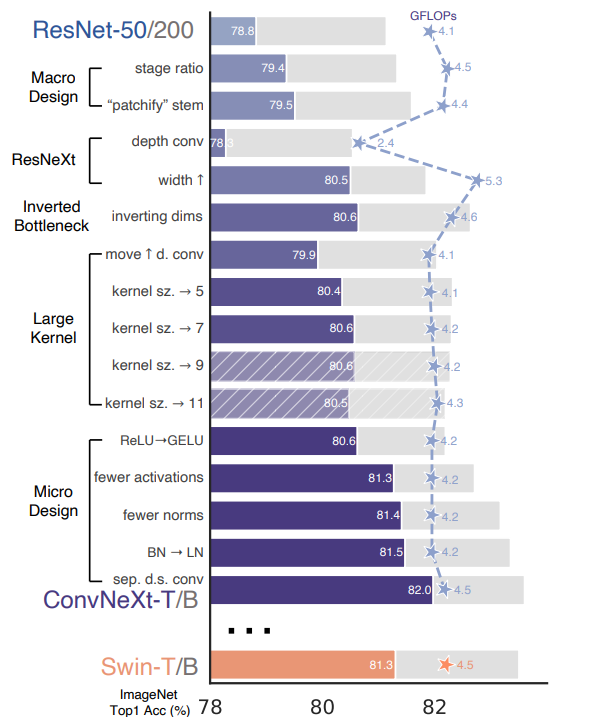
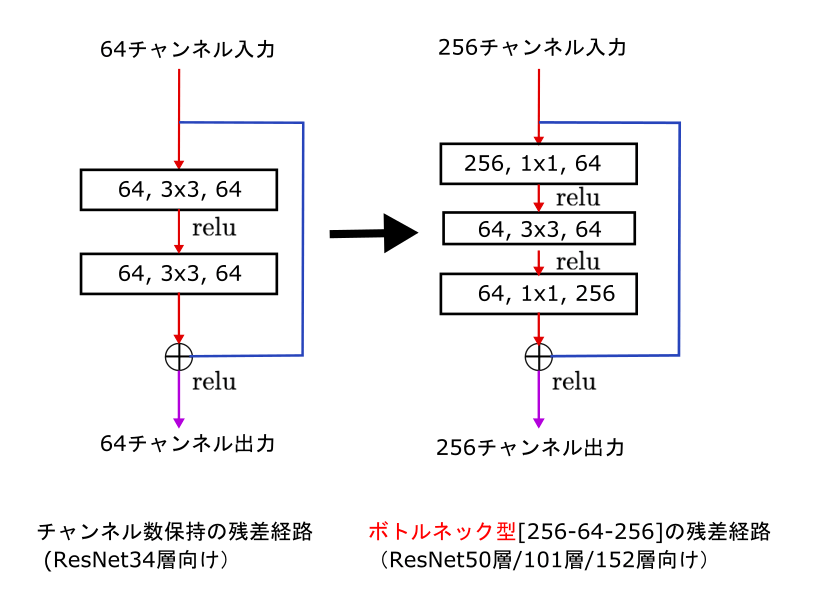
ResNetを現代風に DepthWiseにしたり (PointWise・Depthwise) カーネルサイズ変えたり bottleneck内のレイヤーの順番を変えたり BNからLNにしたり 地味に実装でtimmつかてますねん https://github.com/facebookresearch/ConvNeXt/blob/d1fa8f6fef0a165b27399986cc2bdacc92777e40/models/convnext.py ...