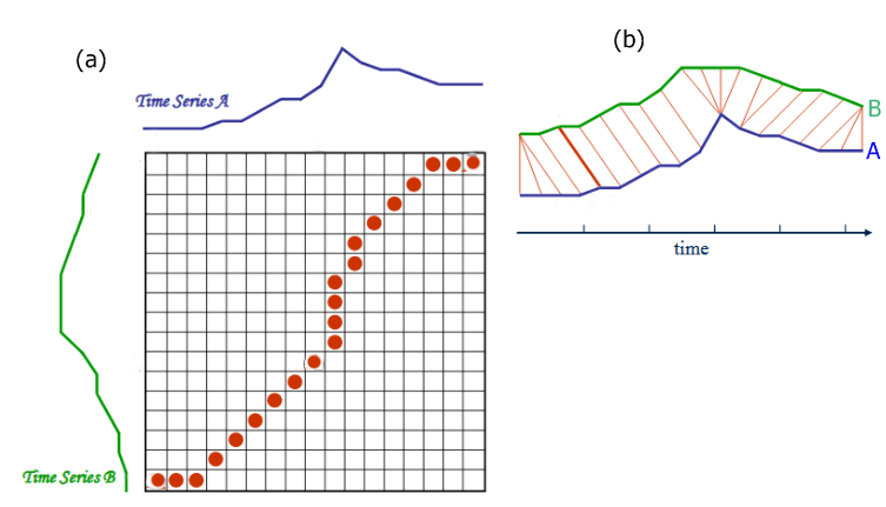
共変量シフト
· ☕ 1 min read
BatchNormによって減らすことができる BNは学習対象のパラメタを持つので注意 共変量シフトを抑えながら, レイヤの表現量を維持するためにパラメタ $\gamma, \beta$ が使われる https://gyazo.com/b54205f667854ac7219c5f7eb002c761 後で読む https://zenn.dev/takoroy/scraps/b26c76a9f94069 ...