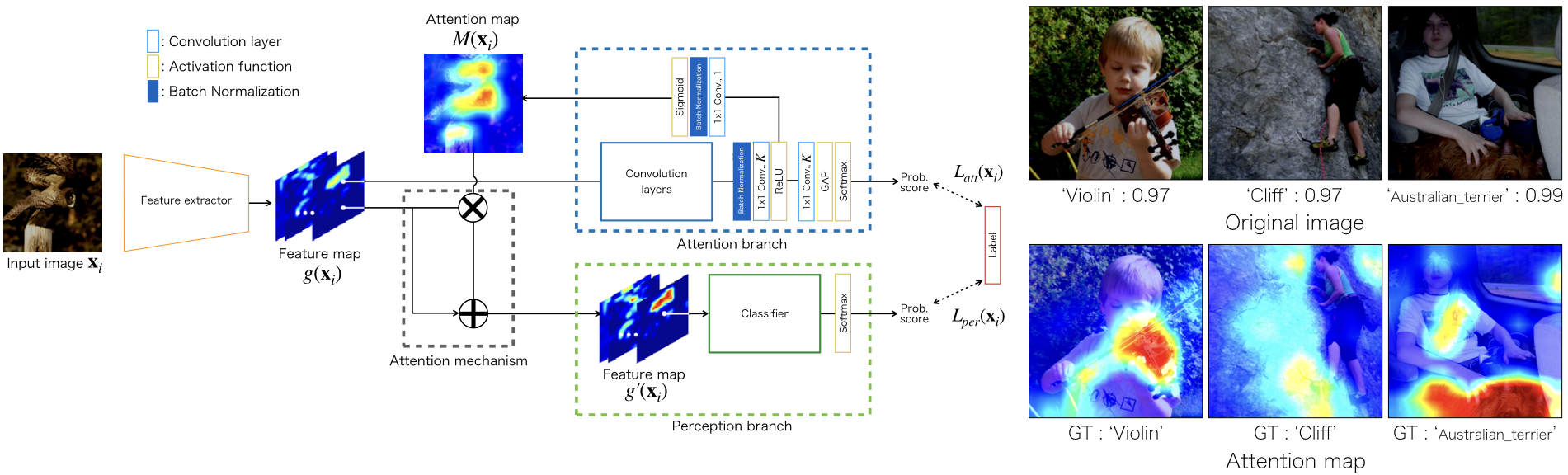
ABN: Attention Branch Network 📅 2022/2/19 · ☕ 1 min read ベースモデルをfeature extractorとperception branchに分割して, その間にattentionを計算するattention branchを挟む ... #post
ViT 📅 2022/2/19 · ☕ 1 min read モデルは「ViT-(1)/(2)」という名前で表され(1)にはモデルサイズB/L/Hが入ります。(2)にはパッチの大きさの16や14などが入ります。ViT-L/16であればViT-Largeで入力画像のパッチの1つの大きさが16であるモデルのことです。 https://qiita.com/omiita/items/0049ade809c4817670d7 ... #post
SAM : Sharpness-Aware Minimization 📅 2022/2/19 · ☕ 1 min read Optimizerの一つ ImageNetやCIFARを含む9つの画像分類データセットでSoTAを更新 SAMは損失が最小かつその周りも平坦となっているパラメータを探す $$\min_{\mathbf{w}} L_\mathcal{S}^\text{SAM}(\mathbf{w})+\lambda|\mathbf{w}|_2^2$$ $L_\mathcal{S}^\text{SAM}(\mathbf{w})$ は以下のように定義. $L_\mathcal{S}$ は通常の損失関数. 何でもOK $$L_\mathcal{S}^\text{SAM}(\mathbf{w}) \triangleq \max_{|\mathbf{\epsilon}|_p\leq\rho} L_\mathcal{S}(\mathbf{w}+\mathbf{\epsilon})$$ ↑ 要はwの近傍まで考慮して最適化するので, 上図のように最小かつ周囲が平坦になる 最大化するεは ... #post
Sequence to sequence learning with neural networks(2014) 📅 2022/2/19 · ☕ 2 min read #Computer #機械学習 [*** — 概要 — ] [** どんなもの?] 多層LSTMでML task(Machine-Translation-Task)を解く. LSTMを2回通す(encoder/decoder)ことで, T次元ベクトル→固定長の意味ベクトル→T ’ 次元ベクトル と変換することができる. (入力時に語順を逆さにする) [** どういう系譜?先行研究との ... #論文 #post
自動微分 📅 2022/2/19 · ☕ 1 min read https://gyazo.com/3e268654e8e64ed6859f39e3c9b3d951 w1, w2 を出発点として, w5までを連鎖律を用いて計算するのが「自動微分」(ボトムアップ) 数式微分・数値微分とも異なる 自動微分には「ボトムアップ」と「トップダウン」がある 具体的に求めてみるとこんな感じ もしフルスクラッチで実装するなら, 初等関数を表現するクラスで導関数を定義すればOK? 下の図はボトムアップの自動微分を図式化し ... #post
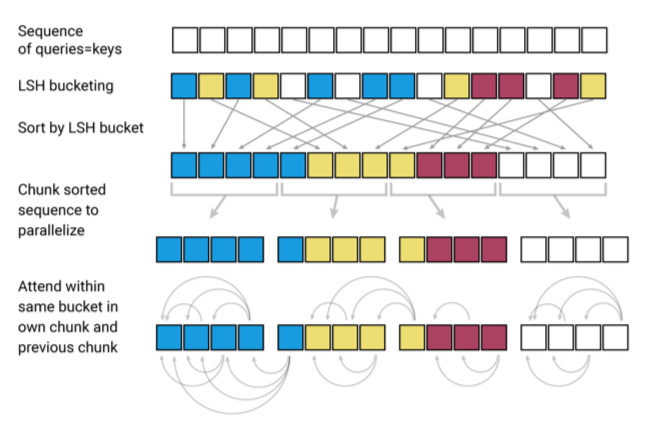
Reformer 📅 2022/2/17 · ☕ 1 min read Attentionの計算量をO(NlogN)に 従来のTransformerだと内積計算がネック 類似度を計算しさえすれば良い ベクトルを回転させてバケツにブチこむ バケツごとに処理 バケツ内は互いに近いベクトルのはず https://gyazo.com/9a2bf1939cfd7fd3bea5864b9664eed2 Reversible Residual layers Transformerを多層化するとそれだけの途中の状態を保存する必用がありますが、Reformerでし ... #post
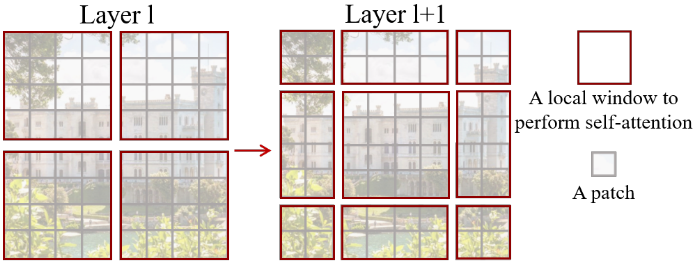
SwinTransformer 📅 2022/2/14 · ☕ 2 min read 認識する対象は画像中で様々な大きさを取る → パッチは対象物体をぶつ切りにする可能性があるのでまずい 画像の解像度が高くなると計算量が膨大になる SwinTransformerの解決策 pooling-likeに, 画像の縦横を小さくしていく 局所的なattentionを取る Swin Transformer Block ほとんどTransformerと同じ 違うのはShif ... #post