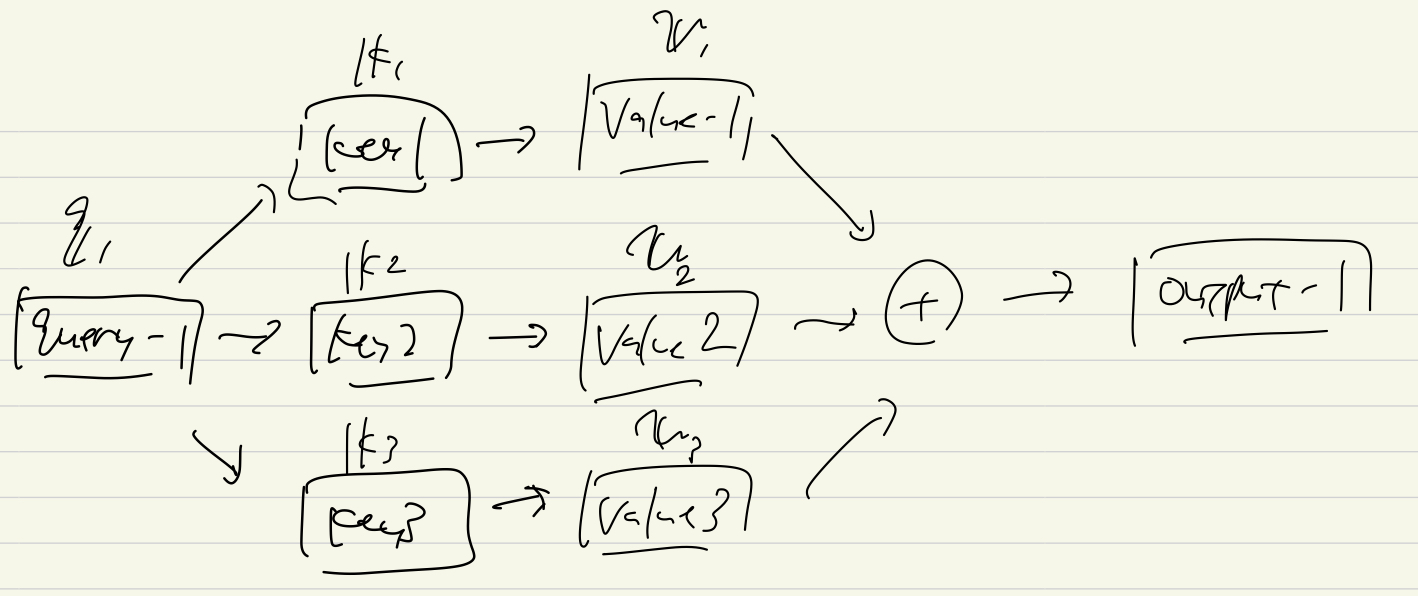
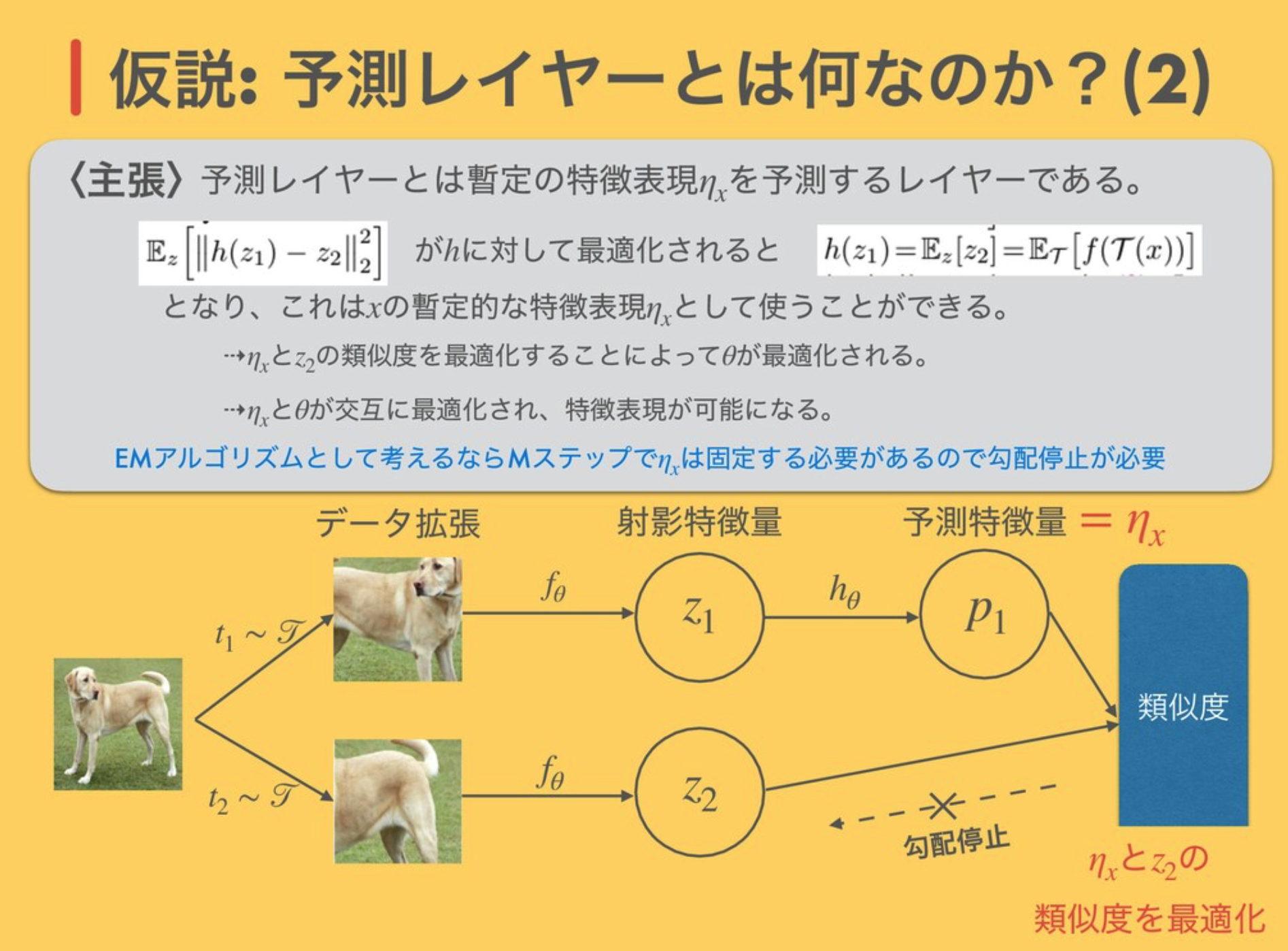
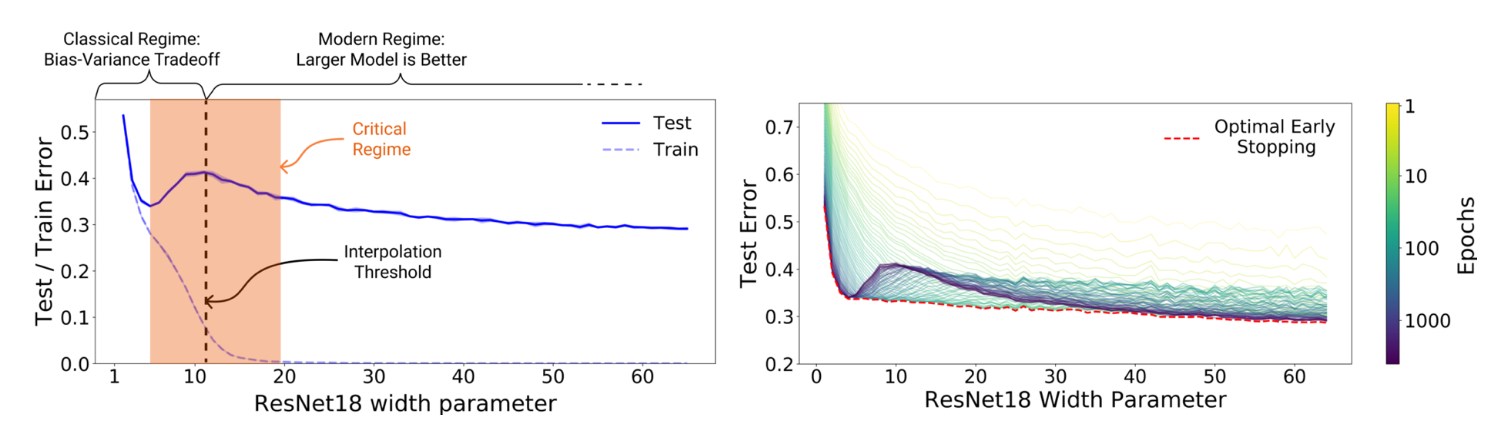
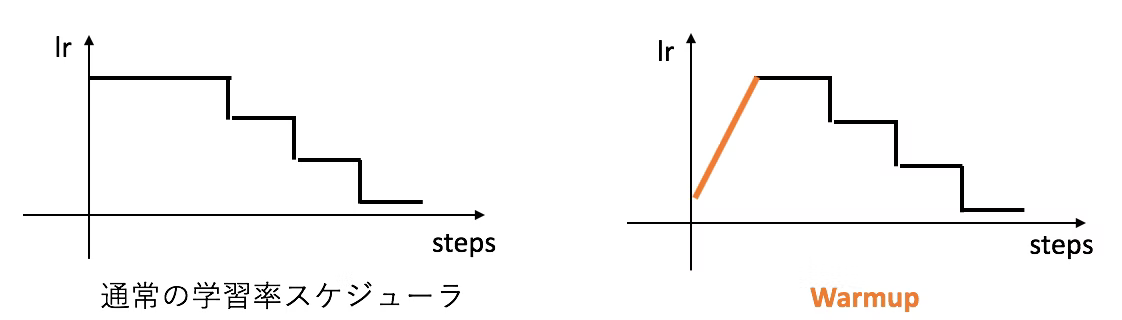
Decoupling Representation and Classifier for Long-Tailed Recognition を引用 新規性は以下の2つ Adaptive Calibration Function Alignment with Generalized Re-weighting Adaptive Calibration Function 分類器の出力 $\boldsymbol{z}$を線形変換して重み付け + marginを加える Alignment with Generalized Re-weighting targetの確率に重み付け https://openaccess.thecvf.com/content/CVPR2021/papers/Zhang_Distribution_Alignment_A_Unified_Framework_for_Long-Tail_Visual_Recognition_CVPR_2021_paper.pdf ...