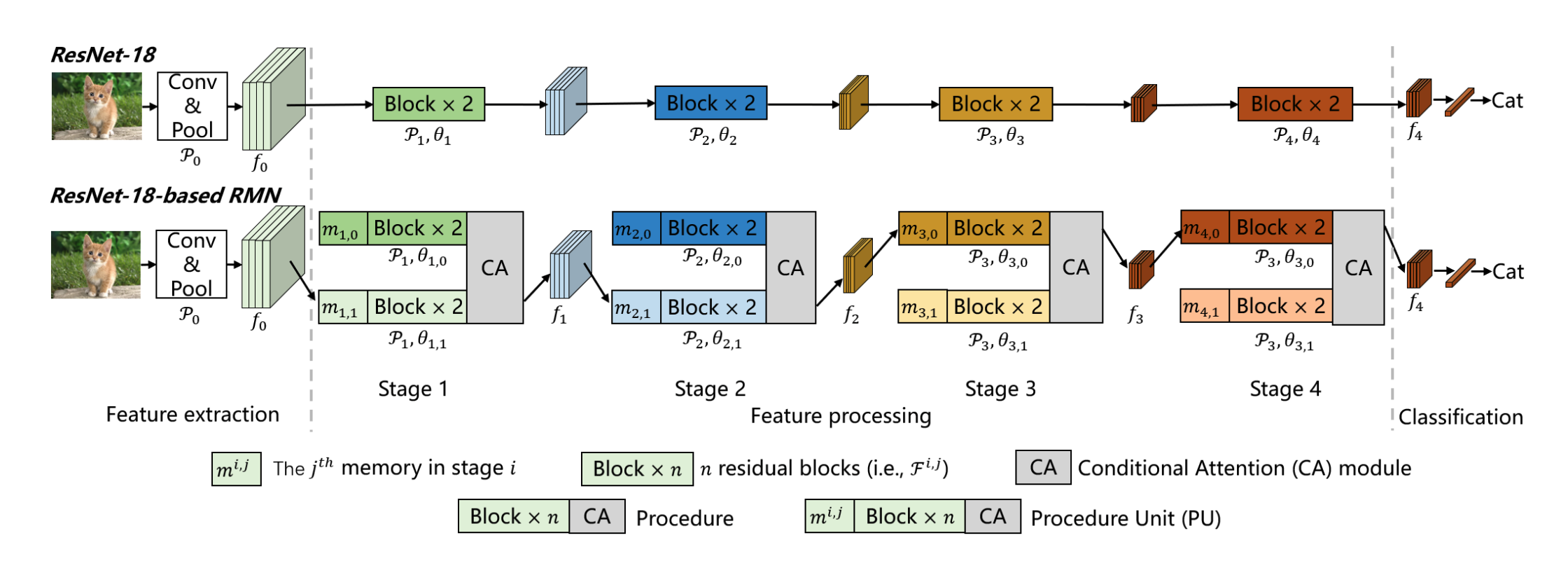
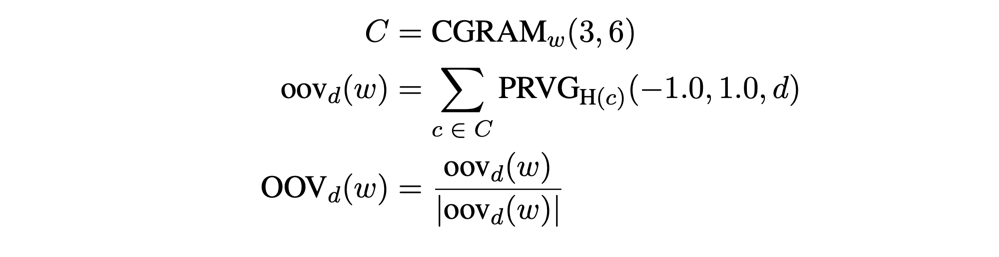Neural Routing by Memory 📅 2022/2/26 · ☕ 1 min read どのようにルーティング? 特徴量 $f$ をGlobal Average Poolingに通したものとメモリ ${\boldsymbol{m}}$とで近傍探索 (論文中ではユークリッド距離) メモリは各ブロックの先頭に配置 メモリはどう初期化するの? クラスタ分析で表現学習 (表現特徴を抽出) 今回はK平均法でクラスタの中心をメモリに採用 パラメタ数が爆増して ... #post
連合学習 📅 2022/2/26 · ☕ 1 min read Federated Learning 学習済みモデルをデバイスに送信 モデルを運用 適宜, デバイス内部で学習 学習差分をサーバに送信 サーバでデバイスから送信されたモデルをマージ ... #post
RNNとチューリング完全性 📅 2022/2/26 · ☕ 1 min read RNNはチューリング完全らしい 関連で Neural Turing Machinesというものもある BPは使えないけど, ノードを動的に増減させるタイプのRNNでもチューリング完全なものが構成できるらしい Turing Completeness of Bounded-Precision Recurrent Neural Networks https://openreview.net/forum?id=IWJ9jvXAoVQ ... #post
コルモゴロフ複雑性 📅 2022/2/25 · ☕ 1 min read 文字列の複雑性を記述することができる 例えば A: 010101010101010101010101010101010101010101010101010101010101 B: 110010000110000111011110111011001111101001000010010101111001 ↑ どっちが複雑と言えるか? → B Bが複雑だということをどう表現するか. 例えば, 人間であれば「説明が簡単かどうか」を指標にすることができる これをコンピュータに落とし込めば… [* 出力 $x$ を出力できるプログラムのうち, 最も文字数が短いプログラムの文字数] これをコルモゴ ... #post
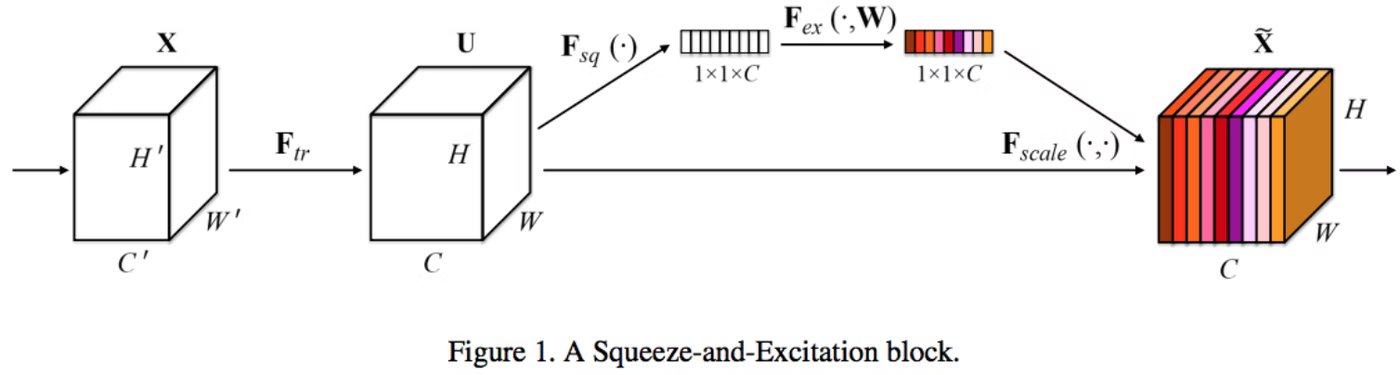
Squeeze-and-Excitation 📅 2022/2/25 · ☕ 1 min read Squeeze Global Average Poolingで各チャネルの平均 $z$を取る チャネル数を少しだけ減らす Excitation 各チャネルについて, 平均 $z$から元の次元に戻す ↑チャネルごとにこいつで重み付け 何が嬉しいの? 空間方向だけでなく, チャネル方向の関係を捉えることが出来る 例えば, ある特徴マップと別の特徴マップとで同じような部分に強い反応があれば, それらの関係を ... #post
KLダイバージェンス 📅 2022/2/20 · ☕ 1 min read 分布 $p(x), q(x)$ がそれぞれどの程度似ているかを測る指標 情報エントロピーの差を計算する $$KL(p||q) = \int_{-\infty}^{\infty}p(x)\ln \frac{p(x)}{q(x)}dx$$ 特徴 対称性がない それゆえ, 距離ではなく「擬距離」と呼ばれるらしい 対称性を持たせるために左右反転したものの平均を取ることがある $$D_{JS}(p||q) = \frac{KL(p||q) + KL(q||p)}{2}$$ これをJSダイバージェンスと呼ぶらしい ... #post
情報エントロピー 📅 2022/2/20 · ☕ 1 min read 要件 確率を用いたい ある独立な事象について, 情報量は加法的でありたい → つまり, ある独立な事象 $x, y$ について, $f(x,y) = f(x) + f(y)$ これらを満たすには, 積が加法的になれば良いので, $log$ が使えそうだ よって, 情報量を $f(x) = -log(p(x)) $ とする この”情報量”についての期待値を計算したものをエントロピーと定義する $H[y|x$ = -\sum_{x \in X} p(x) log(p(x)) ] ... #post
Siamese Network 📅 2022/2/20 · ☕ 1 min read 画像分類:与えられた1枚の画像がどのクラスに属するのかを学習 Siamese Network:与えられた2枚以上の画像が、それぞれ異なるクラスに属するのか同一のクラスに属するのかを学習 https://qiita.com/koshian2/items/a31b85121c99af0eb050 自己教師あり学習 ラベル無しデータを用いた教師なし学習の一種 例えば指紋認証 人 $i$(クラス $i$) の人指し指は一つしかない 普通, 教師あり学習は一つのクラスに大 ... #post
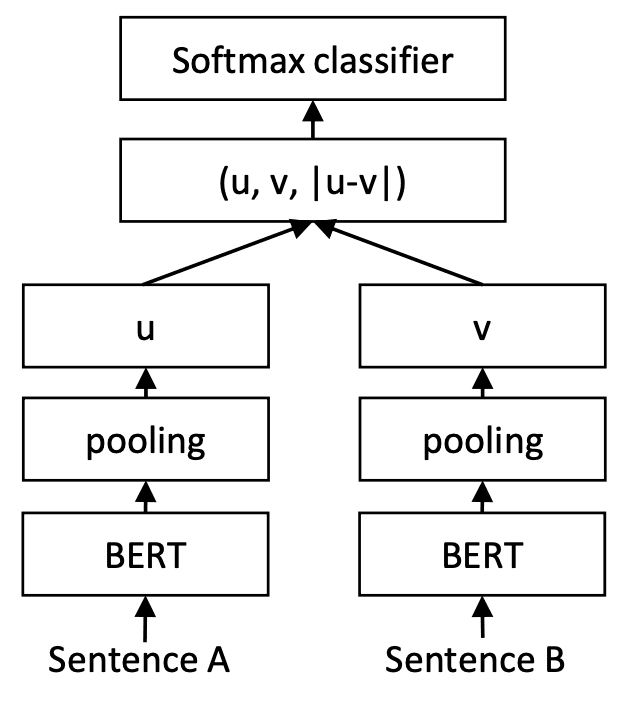
Sentence BERT 📅 2022/2/20 · ☕ 1 min read 得られる表現の埋め込み空間上での距離的な関係を学習するネットワークを Siamese Networkと言います 対照学習とは違う? SimCLRは対照学習 SimSiamは類似度ベース https://speakerdeck.com/sansandsoc/simsiam-exploring-simple-siamese-representation-learning?slide=4 ... #post
subword 📅 2022/2/20 · ☕ 1 min read なので, 基本的にTransformer本人からすれば「未知語」というものは存在しない subwordとは? 普通の単語はそのまま扱い, 固有名詞や数などはサブワードに分割 例: “I have a new GPU!” → { ‘i’, ‘have’, ‘a’, ’new’, ‘gp’, ‘##u’, ‘!’ } / “annoyingly” -> {“annoying”, “ly”} これにより, 語彙数の爆発を防ぐ 上で「普通の単語」と言ったが, 実装上は,「頻度が高いものはそのまま」「頻度が低いも ... #post
magnitude 📅 2022/2/19 · ☕ 1 min read 最初にメモリ上に展開するため, めっちゃ速い OOV (Out-of-Vocabulary) に強いらしい 似ているOOV同士は近い所に埋め込みたい (1) 似てる単語があったら, その単語に近くなるように埋め込みたい (2) $oov_d(w) = [0.3OOV_d(w)+0.7MATCH_3(3,6,w)$] (1) → 似ている単語は同じ感じにしたい = OOV (2) → 似てる単語があったら, その単語に近くなるように埋め込みたい = MATCH 与えられた単語に近い単語上位3つの平均を取る mag ... #post