【論文メモ】RegionCLIP: Region-based Language-Image Pretraining
· ☕ 1 min read
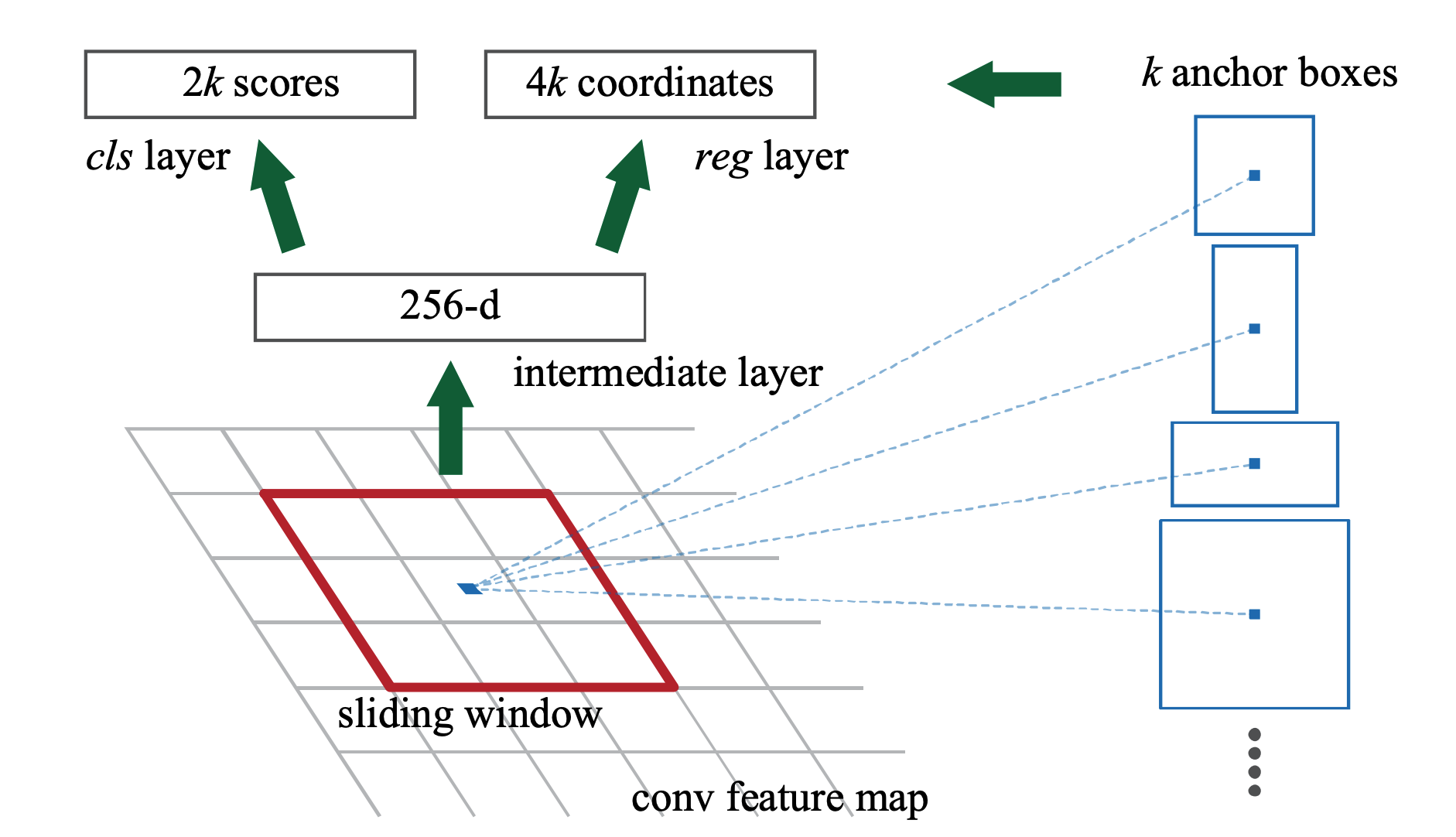
問題点: CLIPは画像全体を用いるため, 物体検出には向かない そこで, 本論文ではCLIPをRegion-text matchingへと拡張した CLIPを用いた open-vocabularyな物体検出タスクが行える open-vocabulary object detection 関連研究としてViLDを挙げている ViLD: Open-vocabulary Object Detection via Vision and Language Knowledge Distillation CVPR22 流れ [RPN](Resion Proposal Network)を用いて候補領域を探す RP ...