【論文メモ】Neural Networks and the Chomsky Hierarchy
· ☕ 5 min read
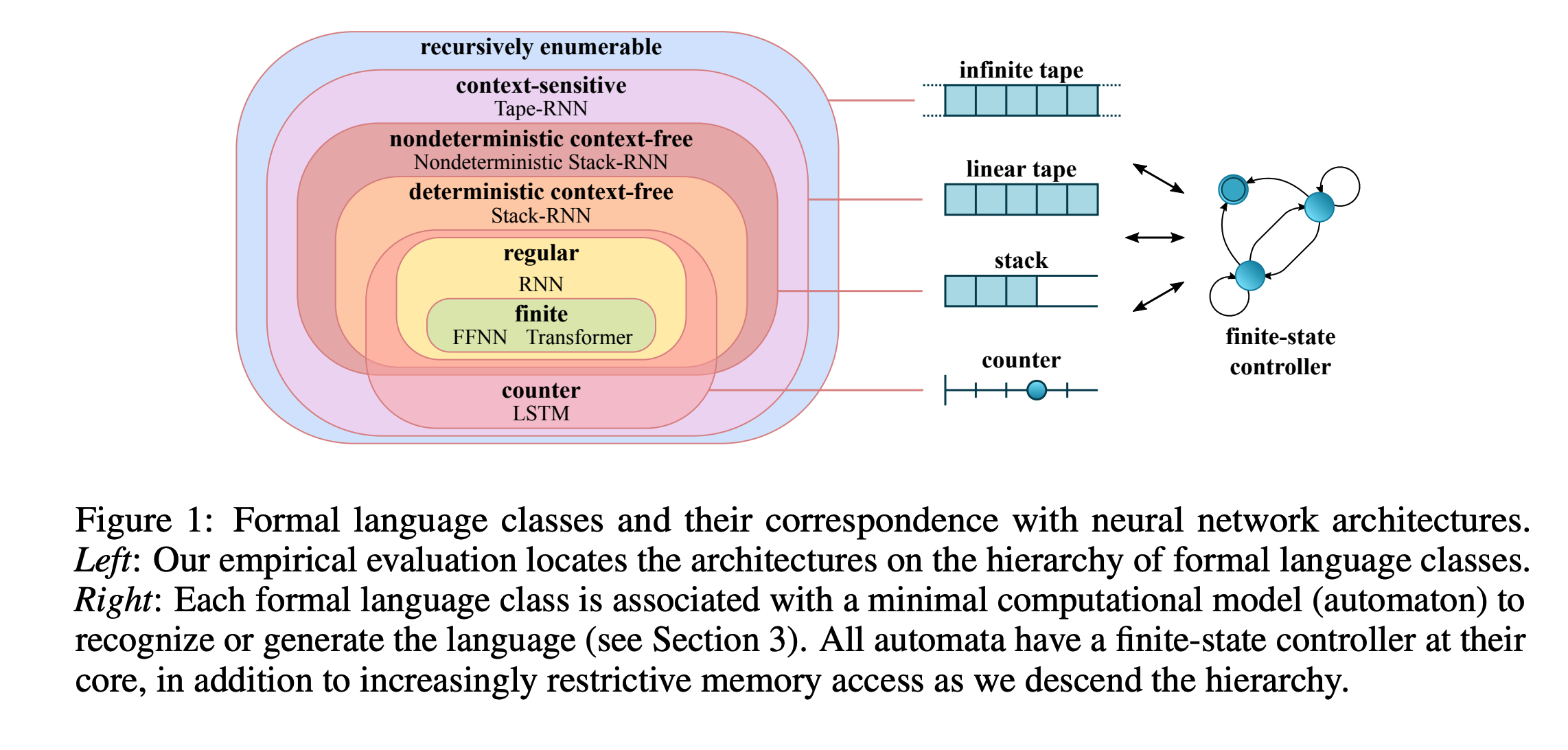
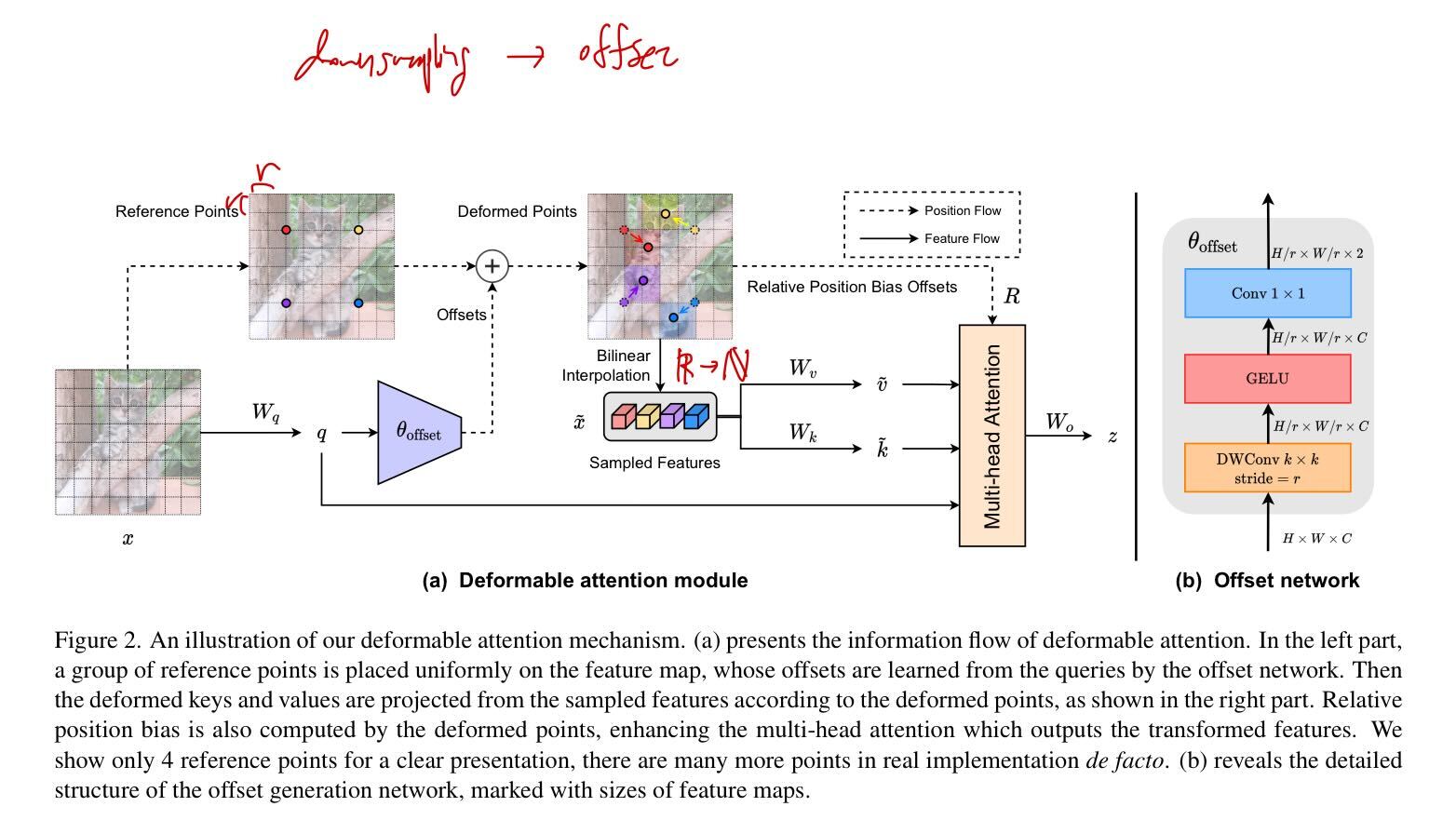
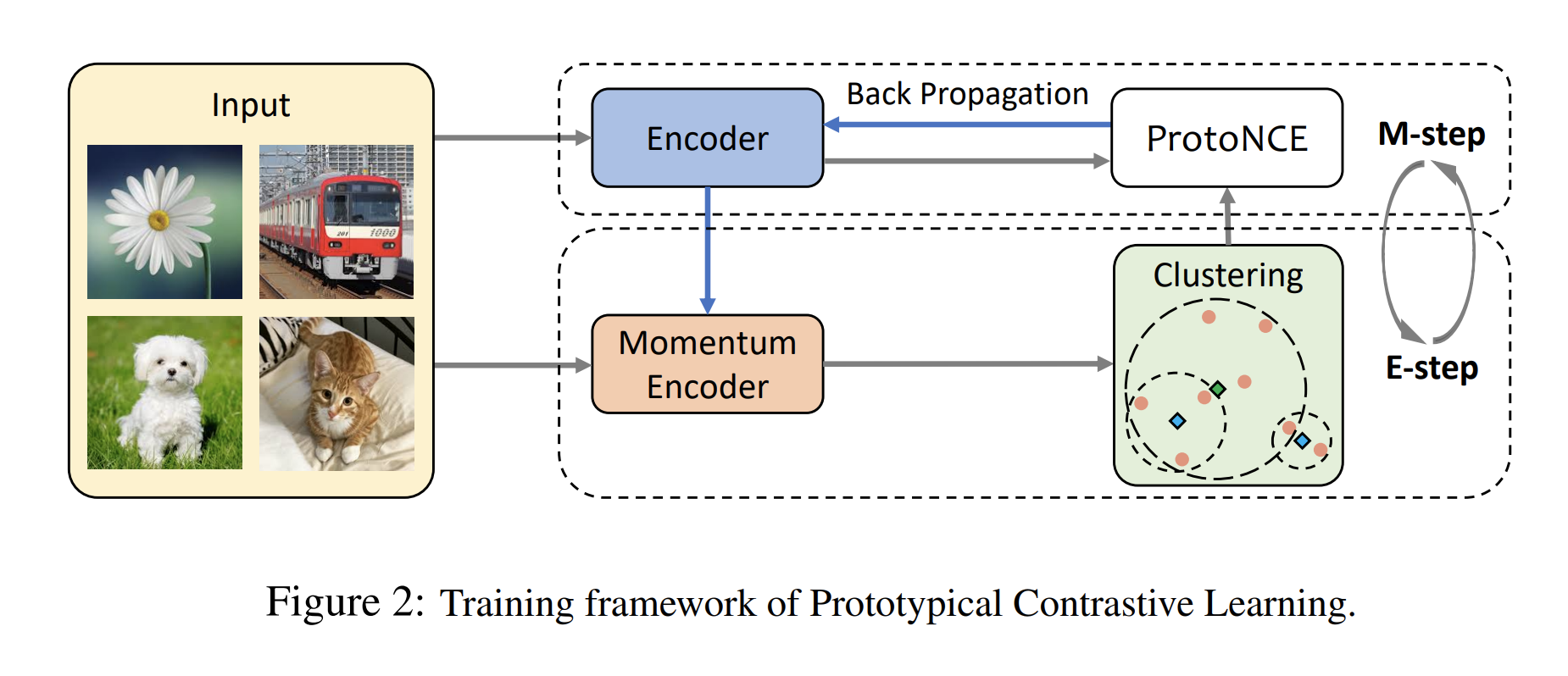
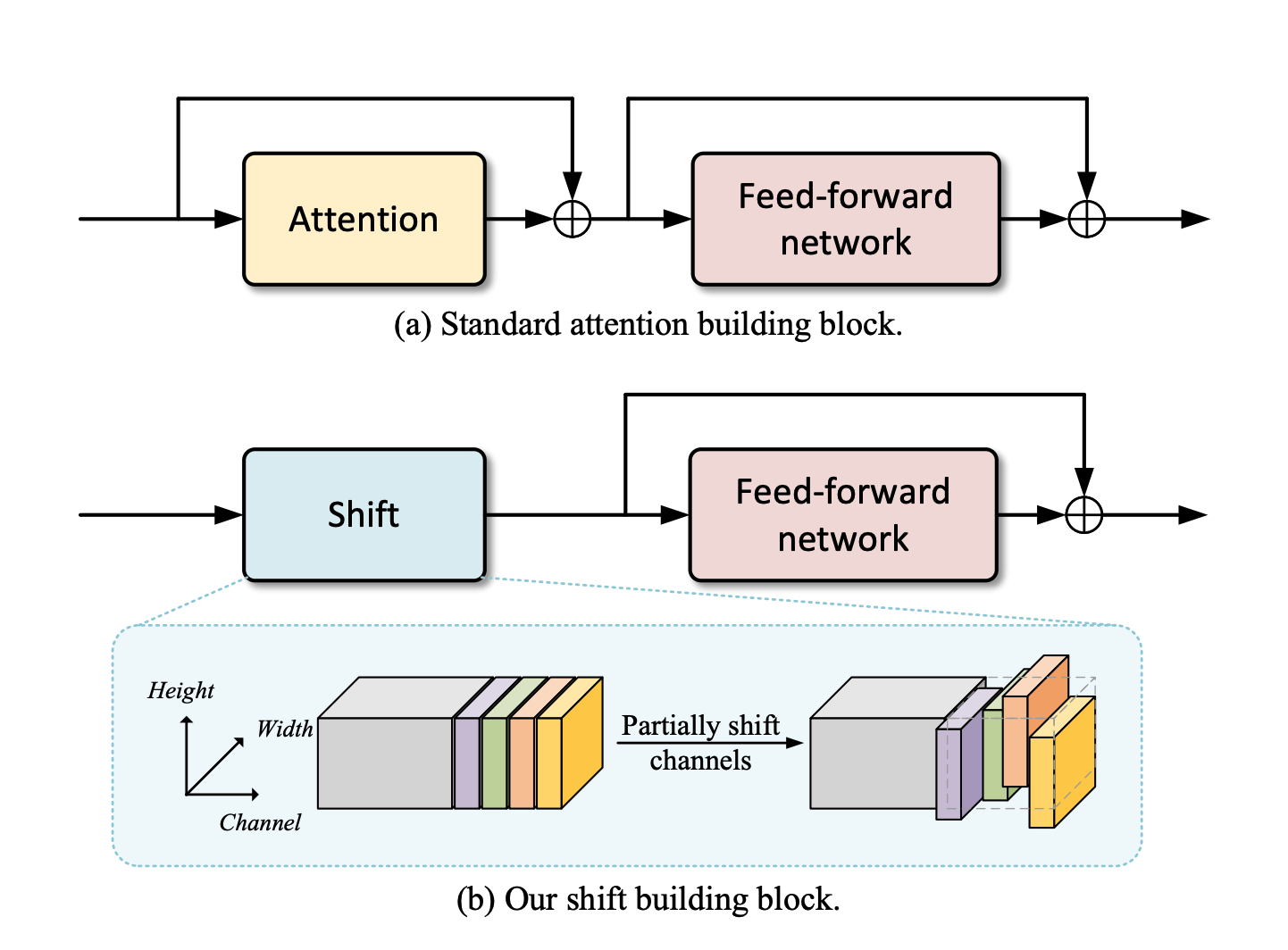
Chomsky Hierarchyにおいて, 各モデルがどのクラスに属するかを実験的に示した 各階層はオートマトンの性質と紐付いている RNNやTransformerは無限ステップにおいてチューリング完全であることが理論的に証明されているが, 有限ステップにおいて各モデルがどのクラスに属するかの研究は未だ発展中 例えば, Transformer ...