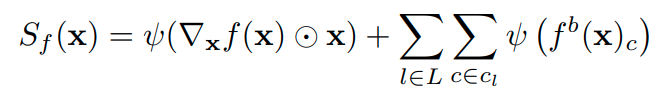【論文メモ】Pix2seq
· ☕ 1 min read
入力 : 画像 出力 : $(y_{\text{min}},x_{\text{min}},y_{\text{max}},x_{\text{max}},c)$ 普通のMLMと同じ感じで, 学習. $$\text{maximize}\sum_{j=1}^{L}\bm{w}_{j}\log P(\tilde{\bm{y}}_{j}|{\bm{x}},{\bm {y}}_{1:j-1})~{},$$ ...