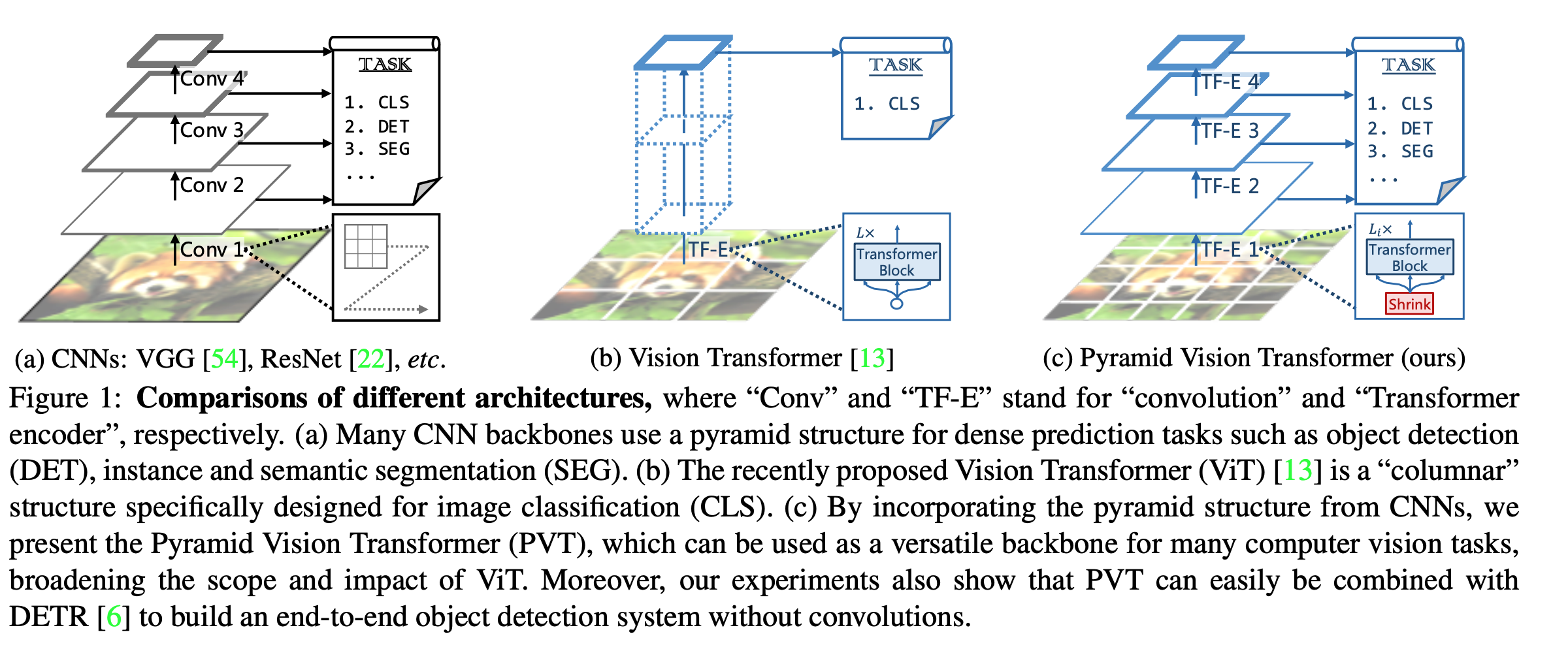
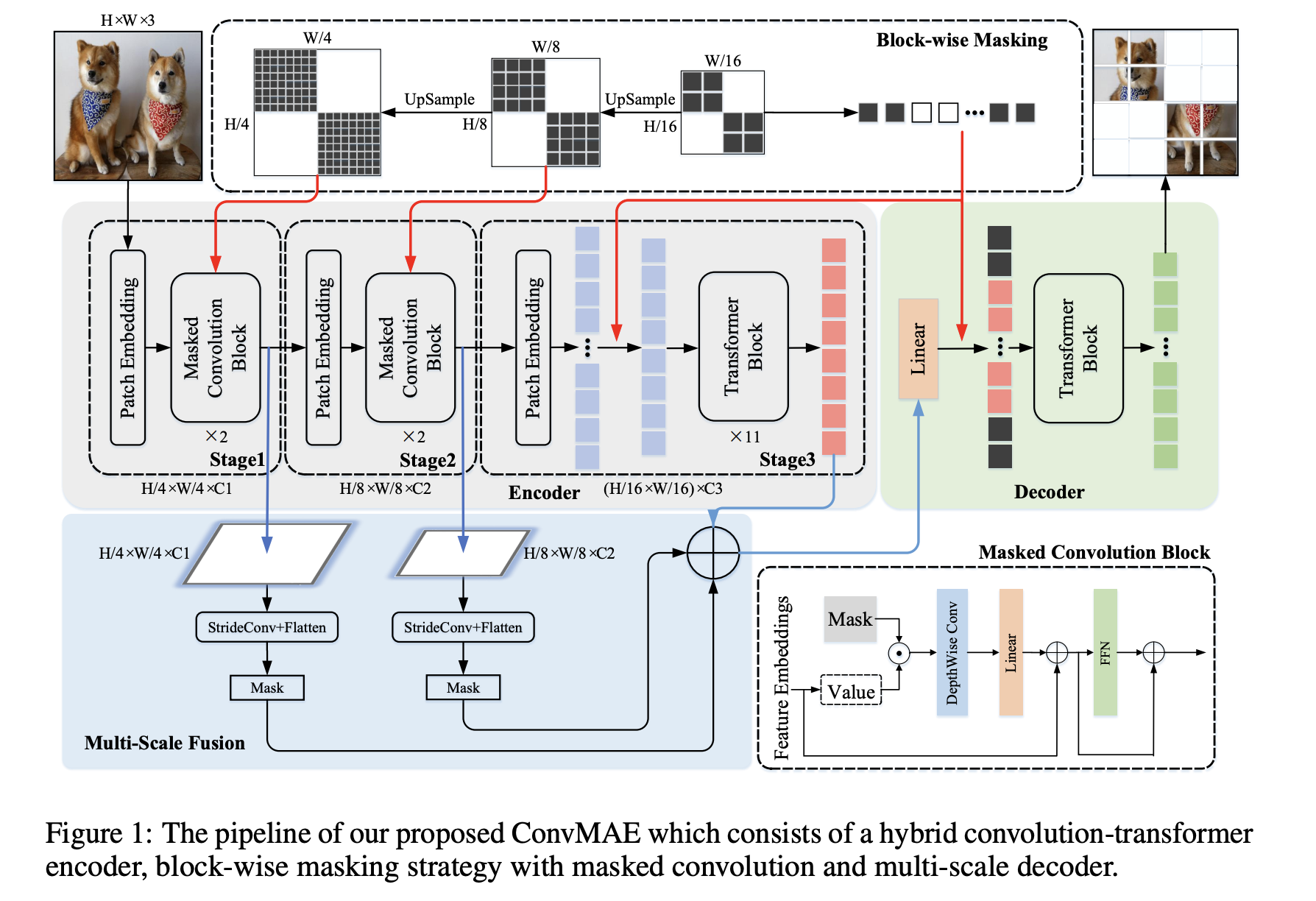
Pyramid Vision Transformer PVT v2では Positional Encodingが存在しない https://twitter.com/yu4u/status/1522360958228000769 FFNにzero padding付きのdepthwise convを入れることで位置情報をencodeさせて, Positional Encodingを置換 zero paddingに重要性がある → How Much Position Information Do Convolutional Neural Networks Encode? ...