【論文メモ】Shifting More Attention to Visual Backbone: Query-modulated Refinement Networks for End-to-End Visual Grounding
· ☕ 1 min read
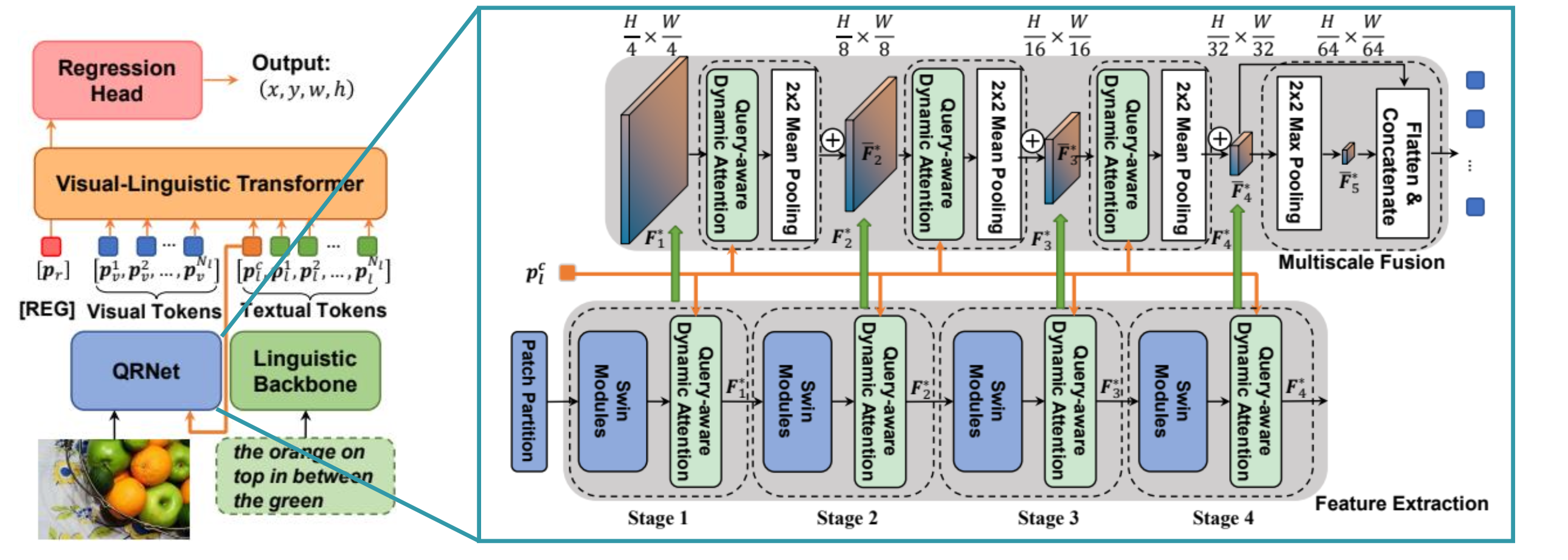
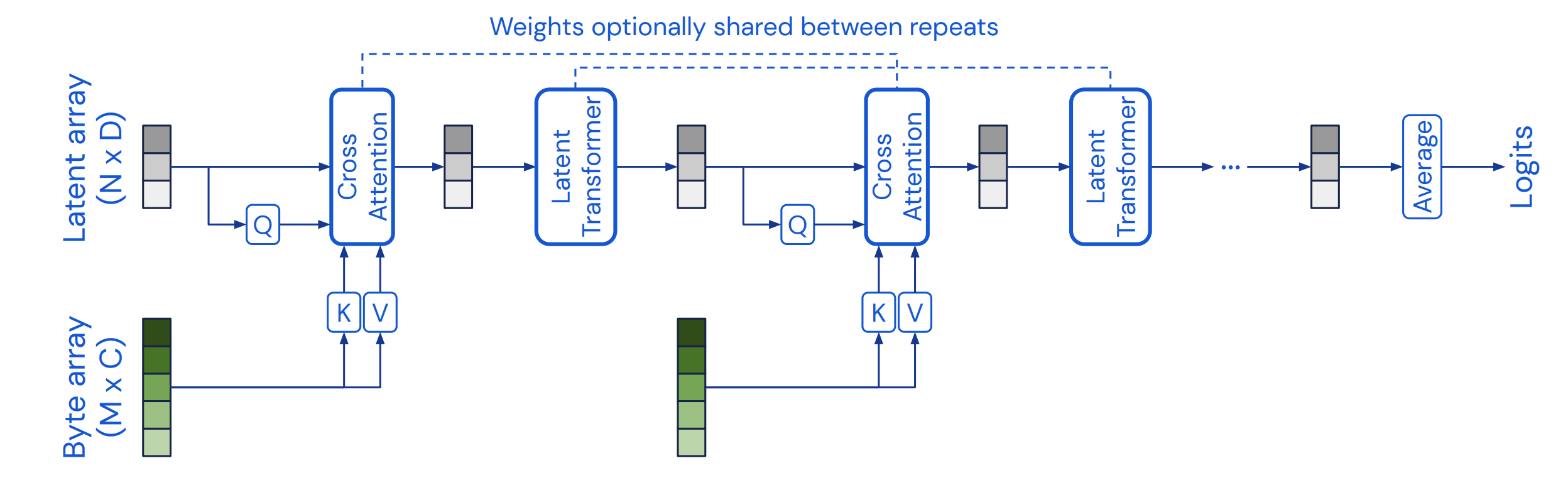
通常のV&Lモデルでは, 画像のバックボーンネットワークは言語特徴量を使用しない そのようなモデルでは, 「画像にりんごはいくつあるか?」などといったVQAタスクすら解けない(可能性が高い) そこで, SwinTransformerを拡張し, 各ステージで言語特徴量をspatial / channel方向にmixしながら推論し ...