はじめに
- ICLR22 [paper]
- 深層学習において, 残差接続は不可欠な存在となりつつある
- 残差接続により, より深い層数のNNを実現できるようになった
- 残差接続に対する解釈の矛盾
- 昨今の研究により残差接続は比較的浅い層をアンサンブルするような効果があるとの見方が強まっている
- しかし, 「深層」学習という名が体を表す通り, 一般には「層を増やす」ことがモデルの表現力を高めていると言われており, ここに残差接続に対する解釈の矛盾が存在する
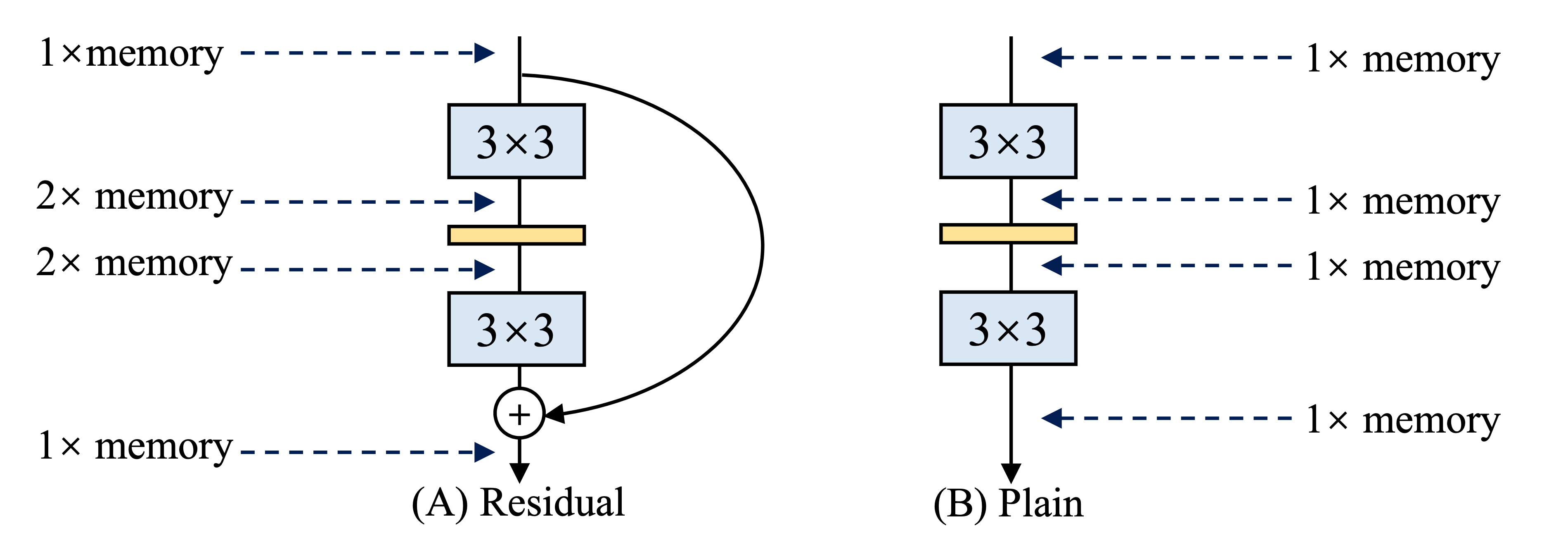
- また残差接続は推論時においてメモリを圧迫しているとの見方も存在する
- 残差接続が結合されるまで, 入力を保持する必要があるため, 一つのスキップでメモリを倍使う (下図参照)
- 例えば, 残差接続はResNet-50における特徴量の40%もメモリを使用している
- 深層学習において, 残差接続は不可欠な存在となりつつある
- したがって, 残差接続の再考が必要であり, 残差接続を用いず層を増やす手法としてTATを提案
引用: RepVGG: Making VGG-style ConvNets Great Again
カーネルの近似
- 活性化関数を $\phi(\cdot)$としたとき, 全結合のネットワーク $f$の各層における出力は以下のように書ける.
$$x^{l+1} = \phi\left(W_l x^l + b_l\right) \in \mathbb{R}^{d_{l+1}}$$
- ただし, 重みは $W_l \stackrel{\text{iid}}{\sim} \mathcal{N}(0, 1/d_l)$で初期化され, バイアス $b_l$は $0$で初期化されるとする.
- このとき, $f_\theta^l(x) := x^\ell$ として, $f_\theta^l : \mathbb{R}^k \rightarrow \mathbb{R}^{d_l}$のカーネル関数 $\kappa_f^l(x_1,x_2)$を以下のように定義すると,
$$\kappa_f^l(x_1,x_2) = \frac{1}{d_l}f_\theta^l(x_1)^\top f_\theta^l(x_2) $$
- ネットワーク $f$の層の幅を無限大に大きくしたときに, カーネル $\kappa_f^1(x_1,x_2)$は以下のような $\tilde{\kappa}_f^1(\Sigma_{x_1,x_2})$によって近似できることが知られている. (上のカーネルは $f$によって直接記述されているが, 近似されたカーネルは活性化関数 $\phi$によって書き下されている点に留意されたい)
$$\tilde{\kappa}_f^1(\Sigma_{x_1,x_2}^0) = \mathbb{E}_{z \sim \mathcal{N}(0, \Sigma_{x_1,x_2}^0)} \lbrack \phi(z) \phi(z)^\top \rbrack =: \Sigma^1$$
$$\Sigma_{x_1,x_2}^0 = \frac{1}{d_0}\begin{bmatrix}x_1^\top x_1 & x_2^\top x_1 \\ x_1^\top x_2 & x_2^\top x_2 \end{bmatrix}$$
- 各層ごとの $\Sigma^{l}$と $\Sigma^{l+1}$の間にも以下のような漸化式が成り立ち, 各層のカーネルを計算することができる.
$$\Sigma^{l+1} = \mathbb{E}_{z \sim \mathcal{N}(0, \Sigma^l)} \lbrack \phi(z) \phi(z)^\top \rbrack$$
$$\Sigma^l = \begin{bmatrix}\tilde{\kappa}_f^{l}(x_1, x_1) & \tilde{\kappa}_f^{l}(x_1, x_2) \\ \tilde{\kappa}_f^{l}(x_1, x_2) & \tilde{\kappa}_f^{l}(x_2, x_2) \end{bmatrix}$$
- (幅を無限大に飛ばす→NTKが想起されるが, NTKとは若干異なる)
Q/C maps
-
Q map
- $\Sigma^{l+1}$の対角成分 $q_i^{l+1}$は $\Sigma^{l}$の対角成分である $q_i^{l}$にのみ依存するので,
$$q_i^{l+1} = \mathbb{E}_{z \sim \mathcal{N}(0, q_i^l)}\lbrack\phi(z)^2\rbrack = \mathbb{E}_{z\sim \mathcal{N}(0, 1)}\lbrack\phi(\sqrt{q_i^l} z)^2\rbrack$$
- ただし, $q_i^0 = \frac{|x_i|^2}{d_0}$
- このとき, $q_i^{l+1} = \mathcal{Q}(q_i^l)$であるような $\mathcal{Q}$をlocal Q mapと呼ぶ
- また $L$層のネットワーク $f$全体において, $\mathcal{Q}_f(q) = \underbrace{\mathcal{Q} \circ \mathcal{Q} \cdots \mathcal{Q} \circ \mathcal{Q}}_{L \text{ times}} (q)$を global Q mapと呼ぶ
- カーネル $K(x,y)$は再生核ヒルベルト空間において $x,y$間の類似度を表すので, 対角成分 $q$及び $\mathcal{Q}$は入力の振幅を表す
-
C map
- 一方で $\Sigma^{l+1}$の非対角成分 $c^{l+1}$については, $c^{l+1} = \mathcal{C}(c^l,q_1,q_2)$と全成分に依存するので, 少し計算が厄介
- $\mathcal{C}$をlocal C mapと呼び, 一般に, 以下のように計算される. (説明略)
$$c^{l+1} = \mathcal{C}(c^l, q_1^l, q_2^l) = \frac{\mathbb{E}_{\lbrack {z_1 \ z_2} \rbrack^\top \sim \mathbb{N}\left(0, \Sigma^l \right)} \lbrack \phi(z_1) \phi(z_2) \rbrack}{ \sqrt{\mathcal{Q}(q_1^l) \mathcal{Q}(q_2^l)}}$$
$$\Sigma^l = \begin{bmatrix}q^l_1 & \sqrt{q^l_1 q^l_2} c^l \\ \sqrt{q^l_1 q^l_2} c^l & q_2^l\end{bmatrix}$$
-
ただし, $c_0 = x_1^\top x_2 / d_0$
-
非対角成分 $c$は $\tilde{\kappa}_f^{l}(x_1, x_2)$であるから, ある層の異なるノードにおける入力 $x_1,x_2$の類似度を計算することになる
- つまり, location-wiseな入力の類似度を計算することになる
-
こちらも同様, $L$層のネットワーク $f$全体において, $\mathcal{C}_f(c) = \underbrace{\mathcal{C} \circ \mathcal{C} \cdots \mathcal{C} \circ \mathcal{C}}_{L \text{ times}} (c)$をglobal C mapと呼ぶ
- この関数は $c_0 = x_1^\top x_2 / d_0$=類似度を入力として, 類似度 $c$が $f$の出力ごとの類似度とどう関係があるかをマッピングする
- $\mathcal{C}_f(c)$は入力の類似度に対しどれだけ出力の類似度を保持できているかを表すので, なるだけ $\mathcal{C}_f(c)$は非線形である方が良い
- Cが線形であればあるほど活性化関数も線形に近づく (14.3)
- 線形だと, 類似度をそのまま出力してる = 線形
- 逆に $\mathcal{C}_f(c)$が一様に1に近づけば近づくほど, 入力間の類似度を正しく $f$が測れないため, ネットワークの出力から入力間の相対的な距離を推測するのが困難であることになり, 勾配による学習が進まなくなる証拠となる
- 例えば ReLUを使った1層のネットワークの場合↓
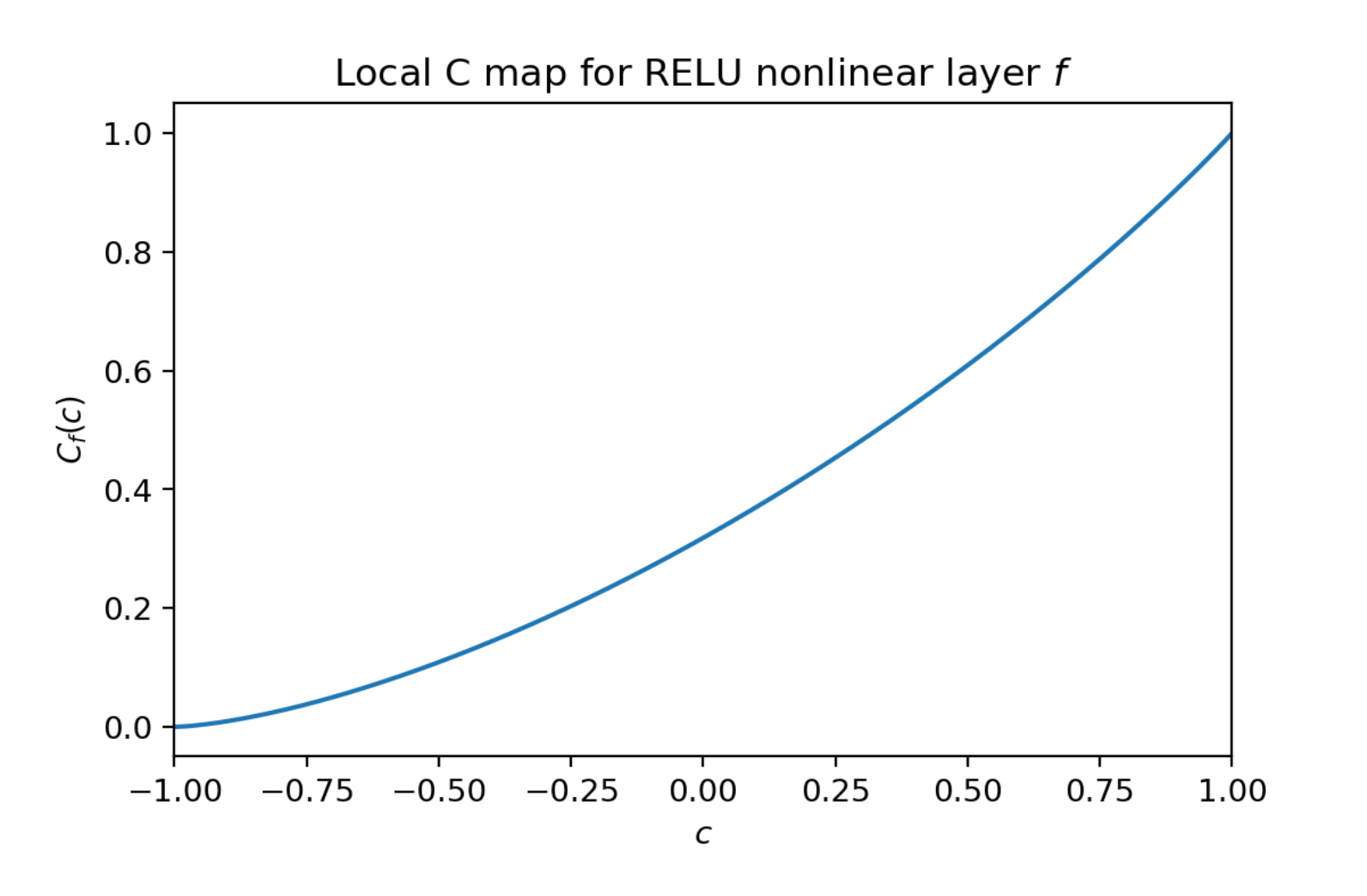
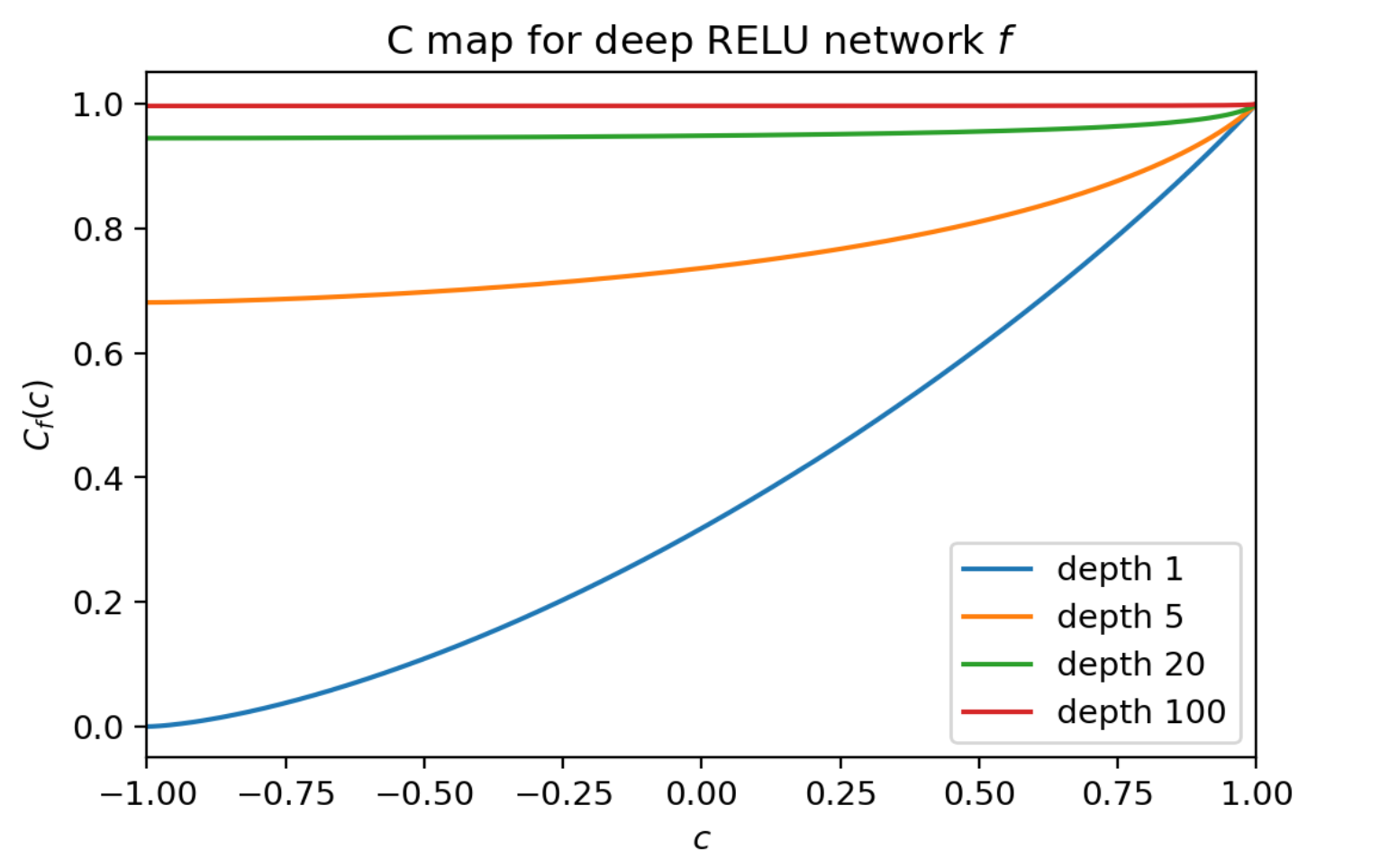
- これが何層にも連なると, C mapの値は1へと収束し, 単純に層を増やすだけでは学習が困難になる傍証が得られる↓
Tailored Activation Transformation for Leakly ReLU
- $\mathcal{C}_f(c)$について望ましい状態
- $C_f(0) = 0$ つまり, 全く類似してないサンプルは出力の類似度も0であってほしい
- $C_f’(1) = 1$つまり, なるだけ $C_f(x) = 1$に接近するような平坦な形は望ましくない
- Leakly ReLU (LReLu) $\phi_\alpha(x)$について
$$\phi_\alpha(x) = \max\{x, 0\} + \alpha \min\{x, 0\},$$
$$\tilde{\phi}_\alpha(x) = \sqrt{\frac{2}{1 + \alpha^2}}\phi_\alpha(x)$$
- という活性化関数を定義すると,
$$\mathcal{Q}(q) = q \quad , \quad \mathcal{C}(c) = c + \tfrac{(1 - \alpha)^2 }{\pi (1 + \alpha^2)}\left(\sqrt{1 - c^2} - c\cos^{-1}(c)\right)$$
-
が成り立つ. ( $\alpha$については後述の方法で求める)
-
$\mathcal{Q}(q) = q$について
- 各層の入力に対して, 摂動に強くなる方向へ制約がかかるため, カーネルの近似誤差が小さくなる
- ここについてはあまりよくわかっていない
-
$\mathcal{C}(c)$について
- $\mathcal{C}_f(c)$について望ましい状態について再考すると
- $C_f’(1) = 1$→ 満足可能
- $C_f(0) = 0$ → これを満足するには $\alpha = 1$とする必要があり, これだと $C_f(c) = c$と線形になってしまうのでよろしくない
- そこで, $C_f(0) = \eta$として, $C_f(c)$の線形度合いを調整できるようにする
- $\mathcal{C}_f(c)$について望ましい状態について再考すると
-
以上より,
$$\mathcal{Q}(q) = q, \quad \mathcal{C}_f^\prime (1) = 1, \quad \mathcal{C}_f(0) = \eta$$ -
を満たすことができるように $\alpha$を決定すべき
-
そのようなLReLUのことをTReLUと呼び, 活性化関数をこのように変化させる手法としてTailored Activation Transformation(TAT)を提案
-
また, このような $\tilde{\phi}_\alpha(x)$を使ったネットワークは, 活性化関数を $\sqrt{2}\max\{x, 0\}$として残差接続の重みを $\sqrt{\frac{2}{1 + \alpha^2}}$としたResNetと同等であることが証明できる
-
TReLU計算アルゴリズム
-
目標: $\mathcal{C}_f(0) = \eta$を満たすような $\alpha$を見つける
-
このとき, $C_f(\cdot)$ではなく, $f$の全てのサブネットワーク $g$について $\mu_f^0(\alpha)$を定義し, $\mu_f^0(\alpha)$について最適化を行う
$$\mu_f^0(\alpha) = \max_{g : g \subseteq f} \mathcal{C}_g(0)$$ -
$\alpha, C(c)$の性質について
-
$C(c)$は以下のように $c$のみに依存して簡単に計算できる.
$$\mathcal{C}(c) = c + \tfrac{(1 - \alpha)^2 }{\pi (1 + \alpha^2)}\underbrace{\left(\sqrt{1 - c^2} - c\cos^{-1}(c)\right)}_{=: A}$$ -
このとき,
$$\dfrac{dC}{d\alpha} = \frac{2A(\alpha^2-1)}{\pi(\alpha^2 + 1)^2} < 0 \quad (\alpha \in (-1,1))$$ -
より, $C(c)$は $\alpha$について単調減少なので, 二分探索ができる
アルゴリズム
-
$C(c)$は以下のように $c$のみに依存して簡単に計算できるので, まず全てのサブネットワーク $g$から $\mu_f^0(\alpha)$を求める
$$\mathcal{C}(c) = c + \tfrac{(1 - \alpha)^2 }{\pi (1 + \alpha^2)}\left(\sqrt{1 - c^2} - c\cos^{-1}(c)\right)$$ -
次に, $\alpha \in (-1,1)$ について, $\mu_f^0(\alpha) = \eta$を満たす $\alpha$を二分探索で求める
-
$\tilde{\phi}_\alpha(x) = \sqrt{\frac{2}{1 + \alpha^2}}\phi_\alpha(x)$を活性化関数としてモデルに適応する

一般化アルゴリズム
- LReLUだけでなく, 一般に滑らかな活性化関数であれば同様の手法を用いることができる

評価
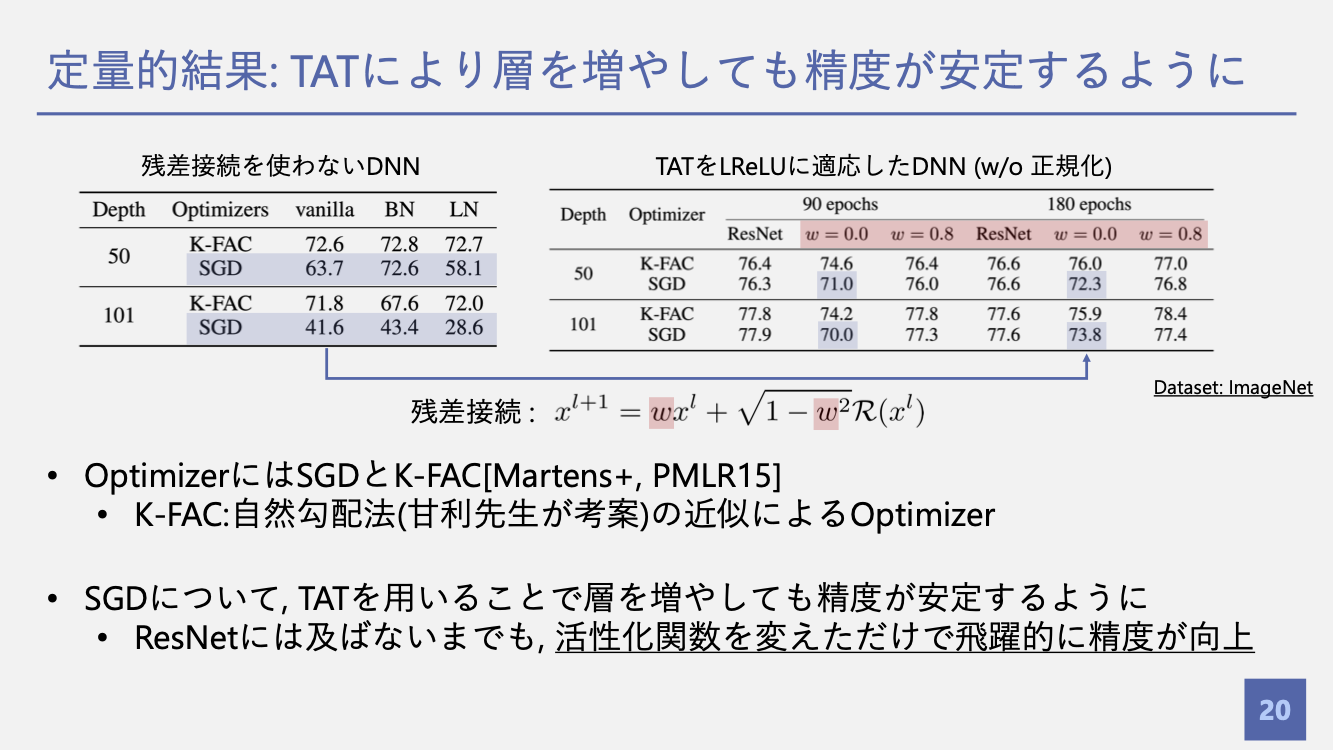
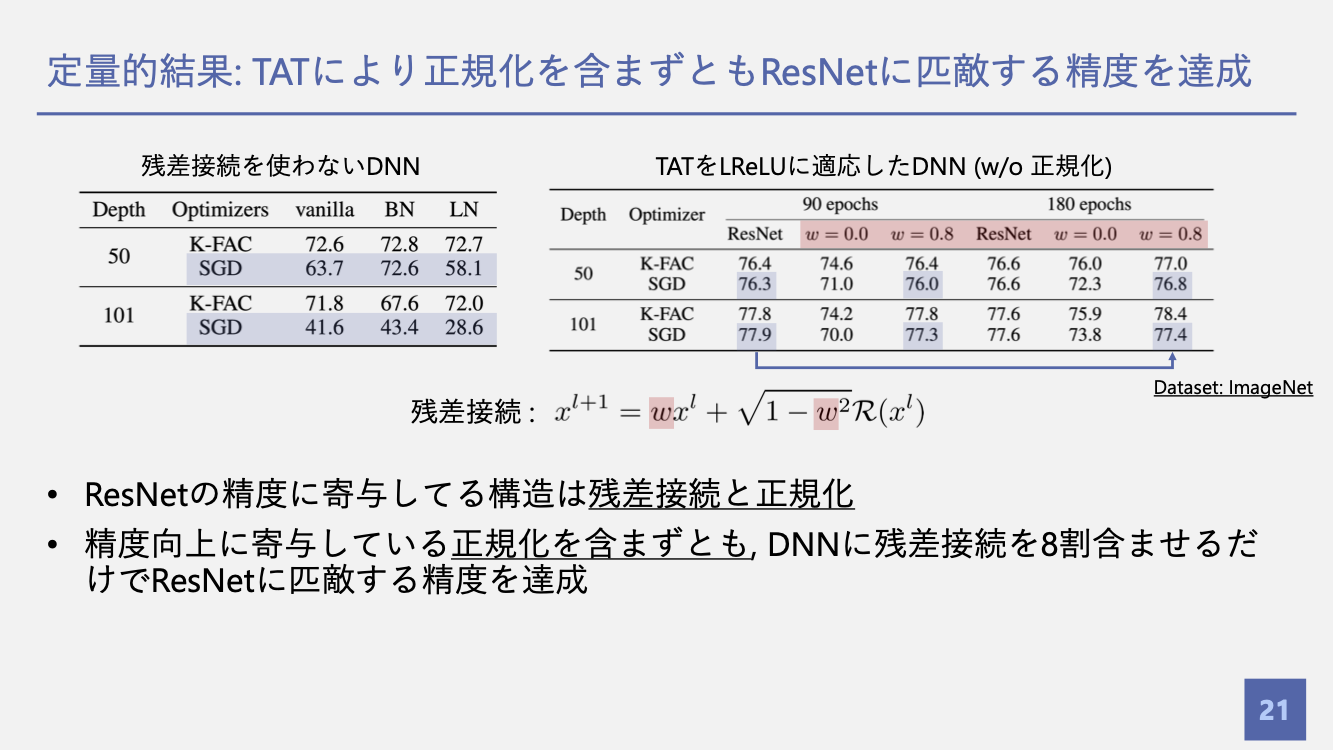
ロジックの整理 & misc
-
FFNにおけるカーネルを用意する→二次のGram行列の漸化式でカーネルの近似解が求まる→対角成分と非対角成分をそれぞれQ/C mapsと呼び, 入力の振幅と類似度を図る指標となる→ネットワーク全体における global Q/C mapsが理論解析のための道具となる
-
理想的なQ/C mapsの値が存在→maximal slope functionでサブネット全体を最適化
-
C mapを最大化するサブネットワークを探す $=: \mu$
-
$\mu$は $\alpha$について単調に減少するので, $\alpha$を二分探索
-
$\alpha$を活性化関数にapply
-
論文中に $\alpha$の範囲は明記されていなかったが, 下のコードを見る限り, $\alpha \in \lbrack-1,1\rbrack$っぽい (supprimentalから引用)
|
|