-
認識する対象は画像中で様々な大きさを取る → パッチは対象物体をぶつ切りにする可能性があるのでまずい
-
画像の解像度が高くなると計算量が膨大になる
-
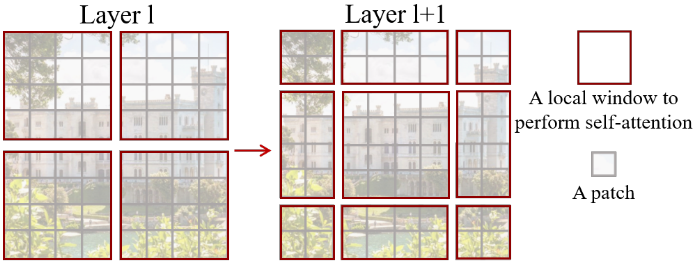
SwinTransformerの解決策
- pooling-likeに, 画像の縦横を小さくしていく
- 局所的なattentionを取る
-
Swin Transformer Block
- ほとんどTransformerと同じ
- 違うのはShifted Window-based Multi-head Self-attention
- 特徴マップをウィンドウで区切って, ウィンドウ内のみでself-attention
- hw個のパッチに対する計算量がO(h^2w^2) -> O(M^2M^2 * h/M * w/M) = O(M^2hw)に
- 考: これって大局的な注目を断ち切ってるだけならCNNっぽくやろうぜってことになるのかな
-
Transformerの計算効率化を行うためにウィンドウで区切るという手法を提案していましたが、これにより部分的にはCNNに近くなり、1回のブロック中では局所的な情報しか見れなくなっています。受容野の広さと計算効率にはトレードオフがあり、さらにネットワークの深さとの兼ね合いもあるので、今後も様々な提案がなされていくのだと思います。
- https://kyla.co.jp/blog/2021/05/10/論文紹介『swin-transformer-hierarchical-vision-transformer-using-shifted-windows』/
- ↑ ということなので多分そういうことっぽい
-