はじめに
- CVPR22
- 決定境界を描画し, 再現性と汎化性について定量的に考察した論文
決定境界の描画 (領域の決定)
- 如何に決定境界を描画するかが重要になってくる
-
その上でまず, データ多様体
-
結論からいえば, データ多様体
-
Off-manifold → ❌
-
On-manifold → ⭕
-
決定境界の描画 (描画方法)
-
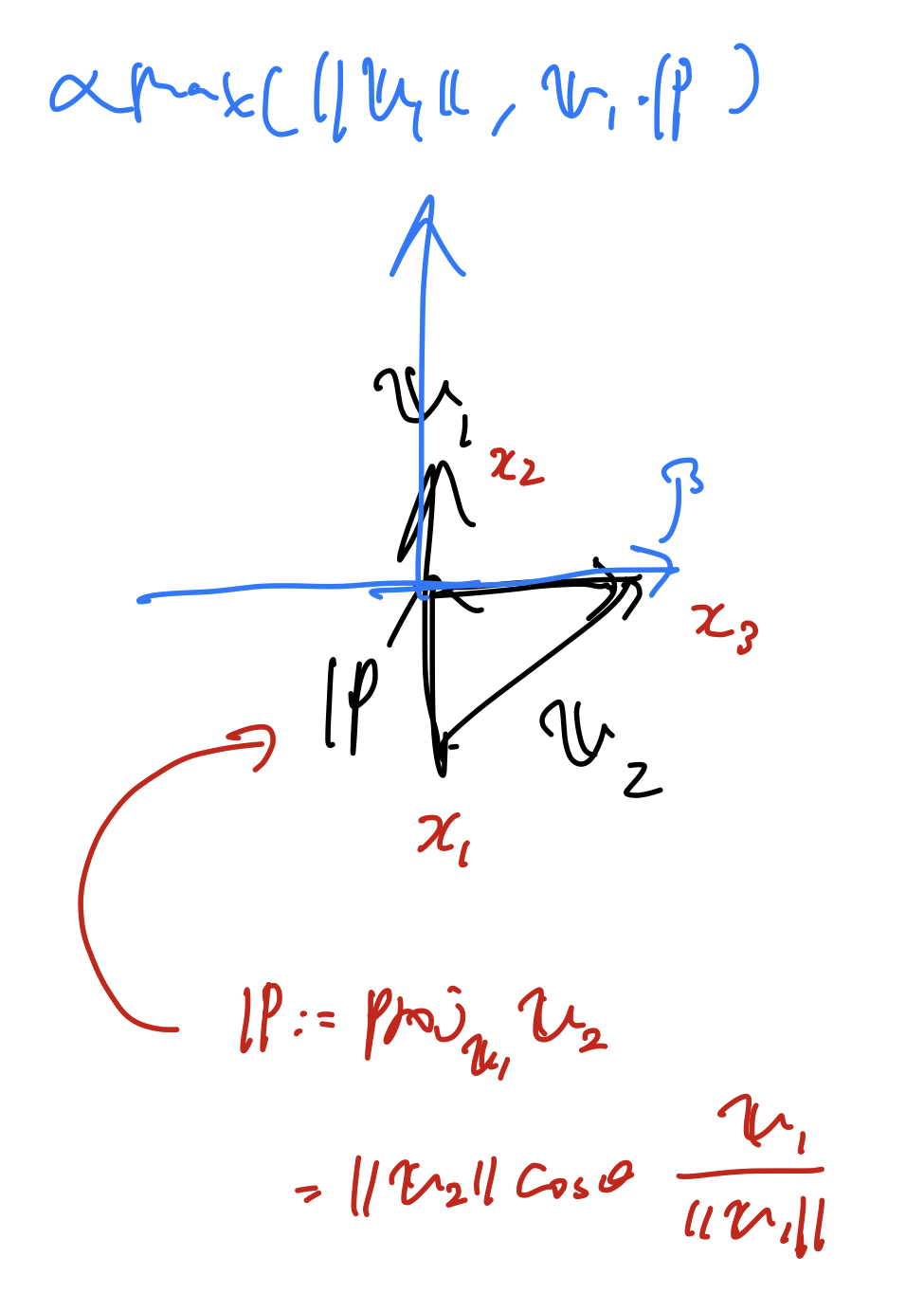
決定境界がデータ点の凸包においても構造化されているという仮定のもと, 以下のように描画する.
- (なぜここで凸包が持ち出されたのかがよくわからない…)
- (論文ではMixupの論文の方法に則っているというが, そもそも論文中に当該箇所が見つからなかった…)
-
まずは
-
実験

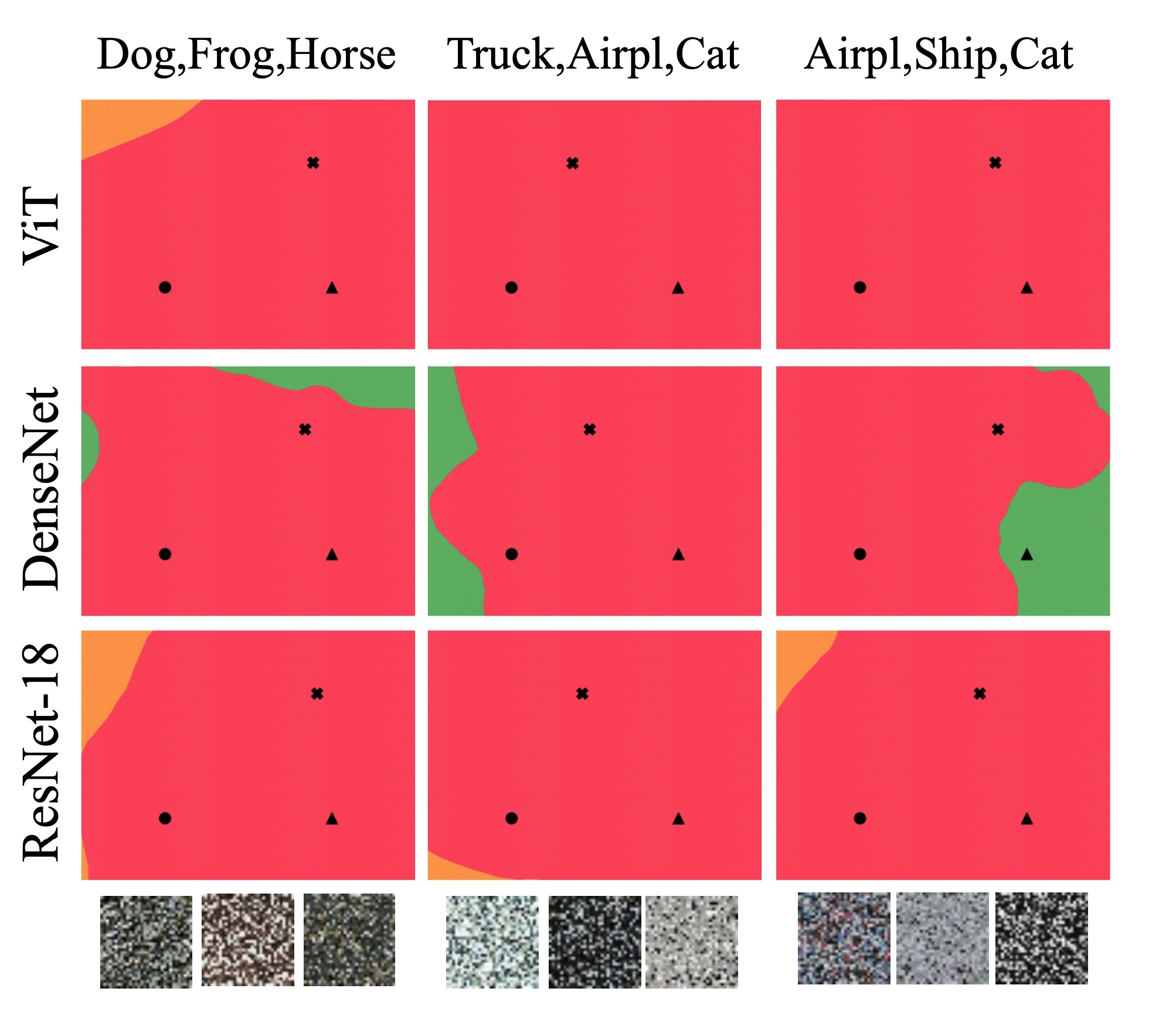
結果1 : 帰納バイアスによる違い
- 結果1 : 帰納バイアスによる違い
- CNN系は決定境界が似ている
- 一方で, ViT, MLP-Mixer, FCもやや似ている
- 特にCNN系ではオレンジ(label=AUTO)が全く出てこないのに対して, 前3つでは出現している
- CNN系はのっぺりしており, 再現性が期待される
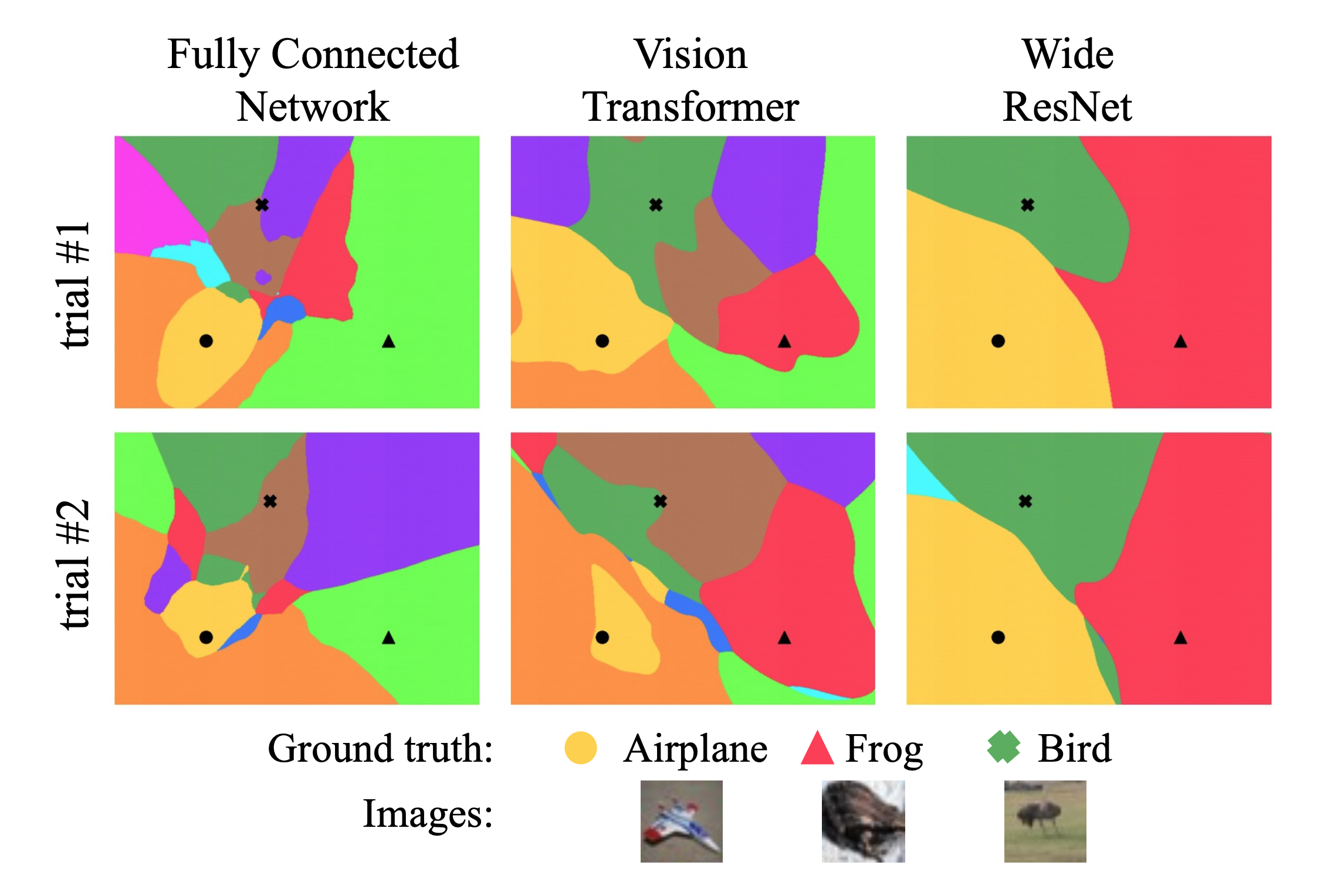
結果2 : 定量的比較
- 結果2 : 定量的比較
- モデルのパラメタ
- ただし,
- つまり, 適当な格子点
- で, それらを比較した結果が下の図
- モデルのパラメタ
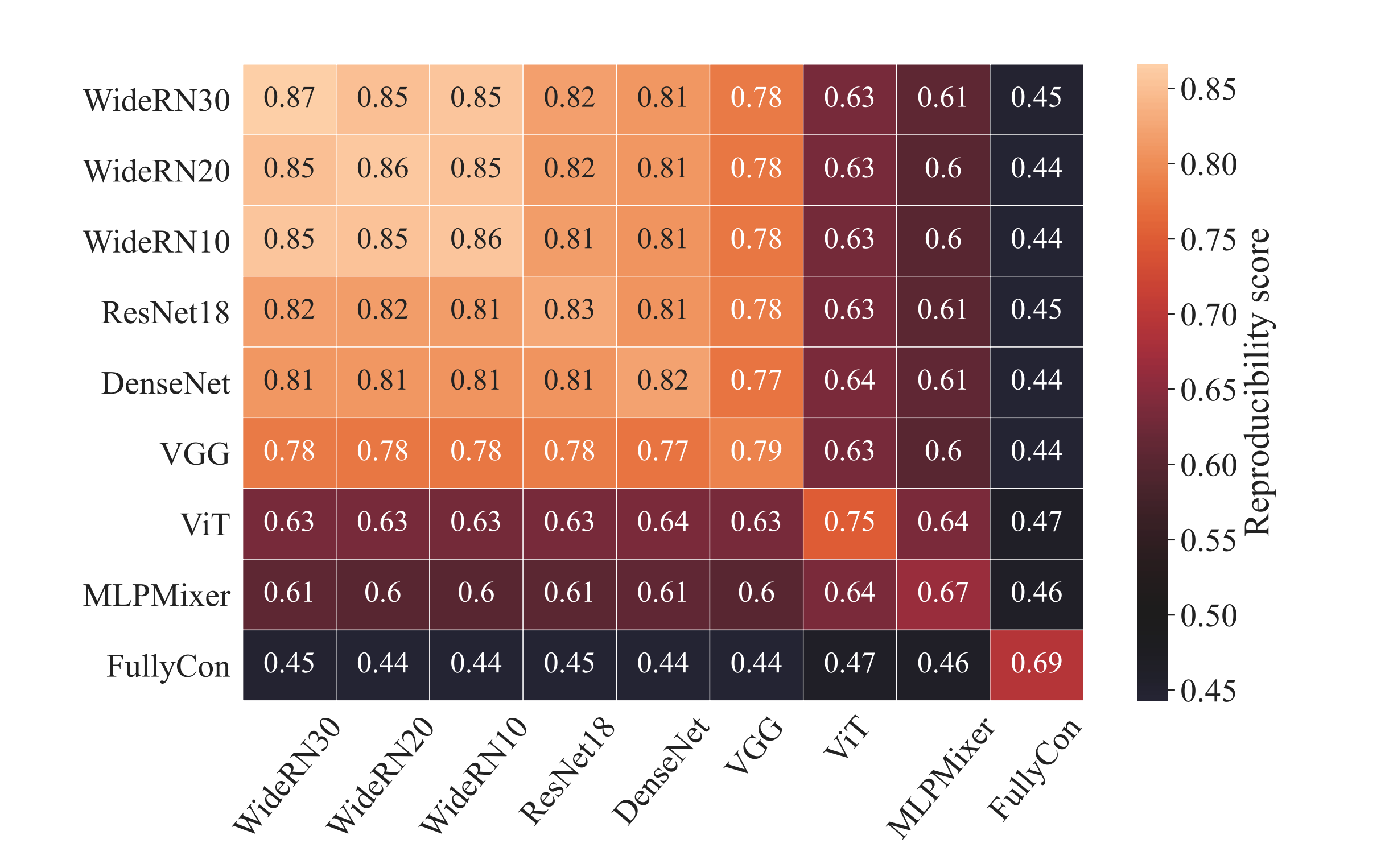
- 上図からわかったのが以下の三点
- 畳み込みの帰納バイアスを持つモデルは似た決定境界を持つ一方, MLP-MixerやViTなどは互いに異なった領域を描く
- CNNの幅が大きければ大きいほど再現性が高くなる
- 残差接続は決定境界にあまり影響しない
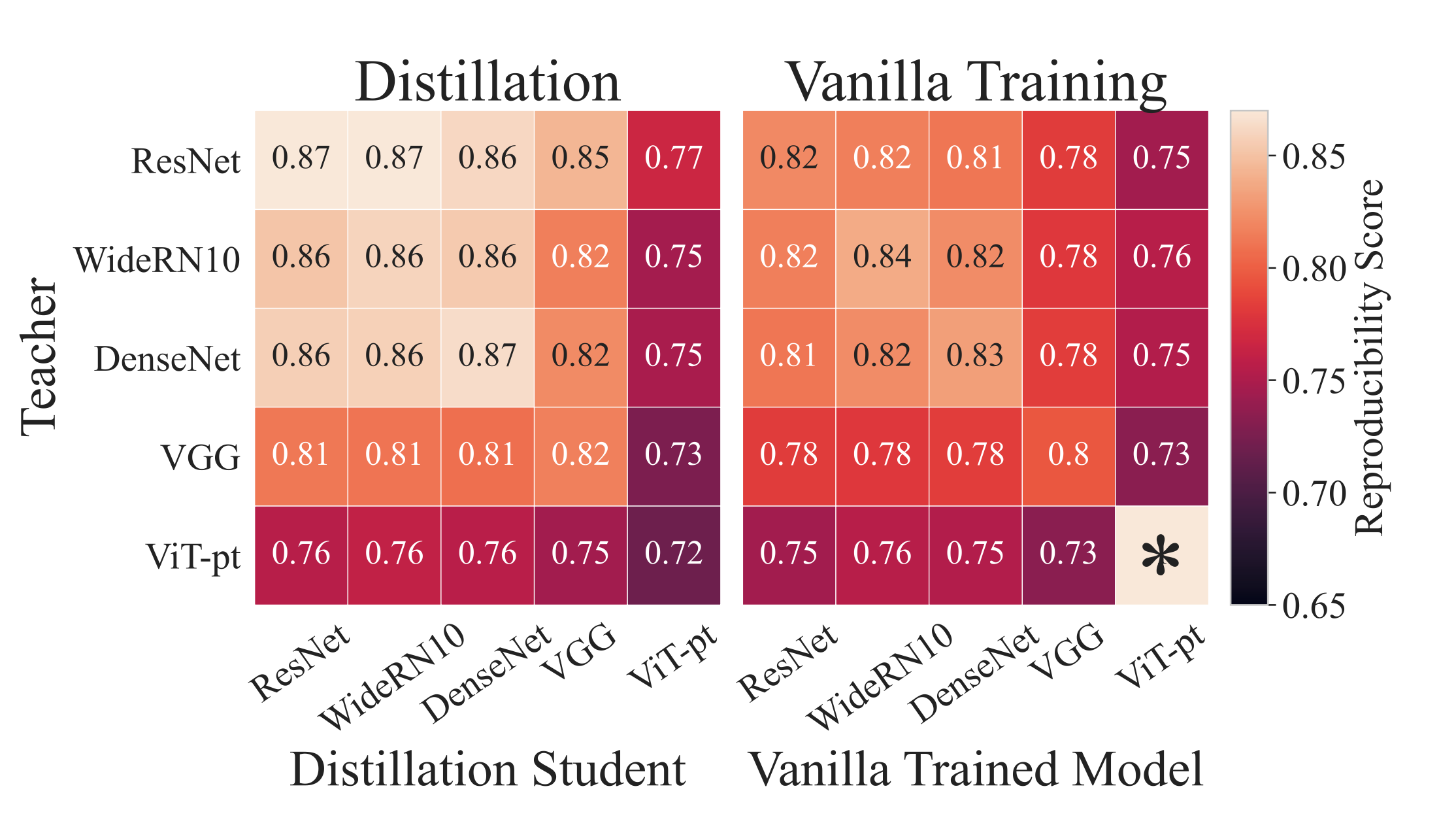
結果3 : 蒸留は決定境界を歪めるか?
- 結果3 : 蒸留は決定境界を歪めるか?
- 今まで双方の意見が出されていたらしいけど, 結論はNO
- ほとんどのモデルで, 似たような決定境界を得ることができる
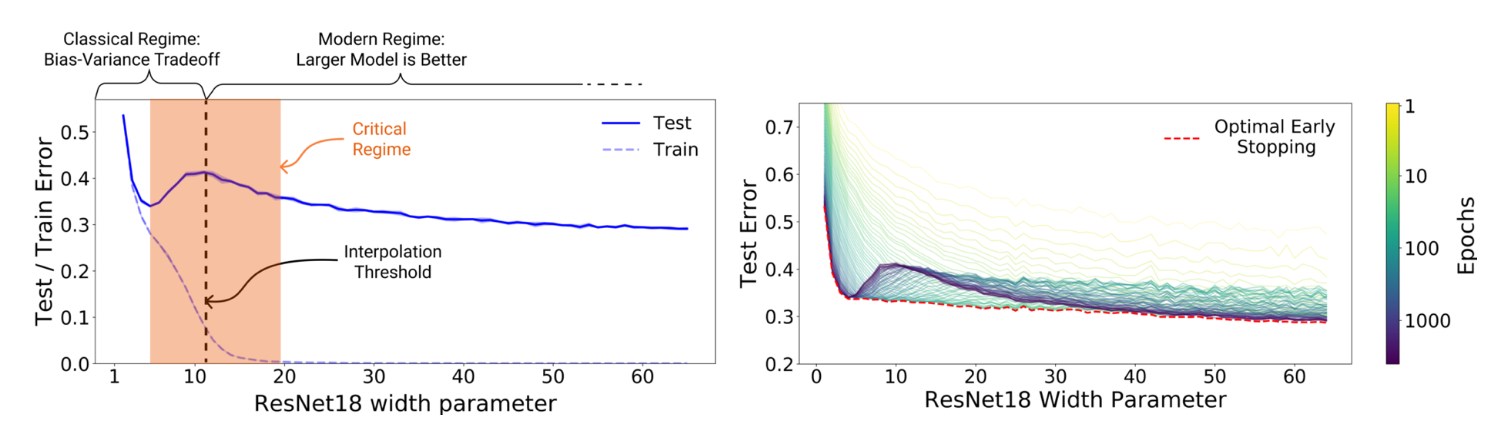
結果4. Double Descentについて
- 結果4. Double Descentについて
- Double Descent: NNに特有の現象で, パラメタを複雑にしていくと, lossが二回減少する現象
- (下図: U字カーブになっている)
- (補足: 近年のモデルではbias-variance分解は破綻しており, 古典的な議論とされている. 現在ではモデルの複雑度を上げるとどちらも減少することが経験的に知られており, Double Descentの文脈では頻出の議論である.)
- Double Descent: NNに特有の現象で, パラメタを複雑にしていくと, lossが二回減少する現象
-
Double Descentはラベルノイズが含まれている場合に容易に再現できることが知られている
-
なので, 今回は20%のラベルノイズが入ったデータセットを実験に用いる
-
実験設定: ResNetのカーネルサイズ
- 大体
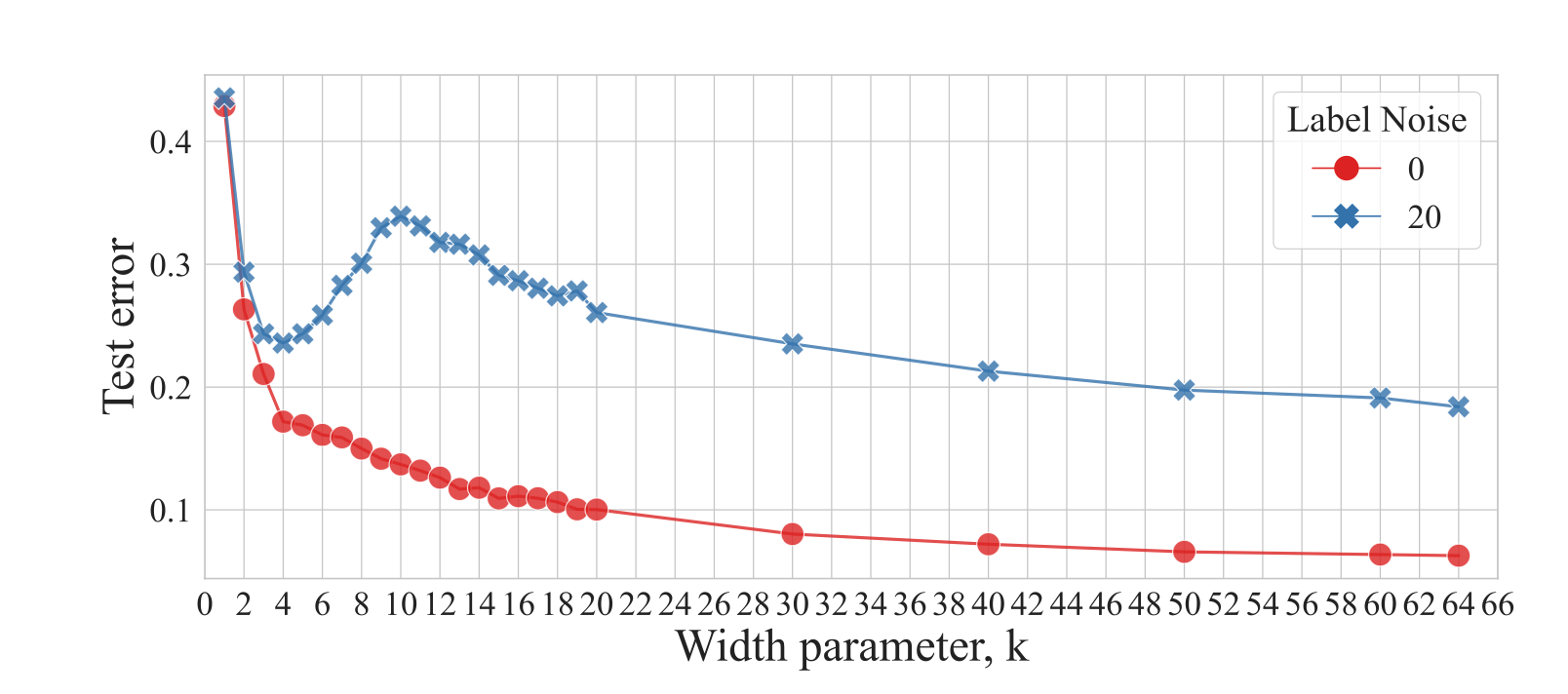
- 実際に決定境界を描画すると下のような感じ
- これらから, 領域がどれだけ断片化(fragmentation)されているかが重要そうなことがわかる
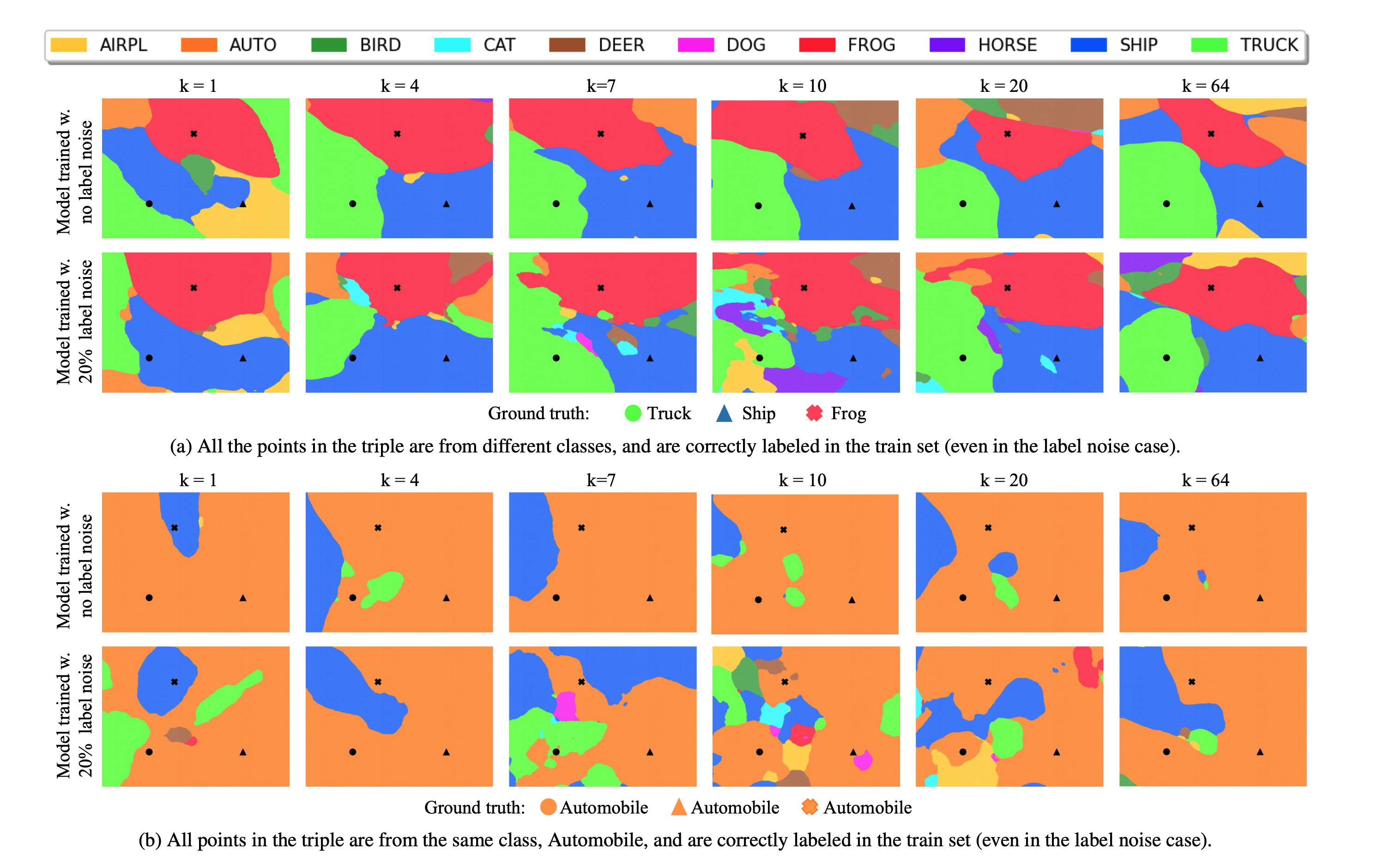
- ラベルの誤ったサンプルについて, 決定境界を描画するとこんな感じ
- 当該サンプルは
- 例えば, 左上の
- 例えば, 左上の
- 一方で
- 当該サンプルは

- ということで, Double Descentはfragmentationの増加が一要因となっていると思われる